最方便的是直接用現有的數據集。
IMDb 官方釋出的有數據集:
數據集的官網連結如下,
(但是官方給出的是簡要數據集,似乎不包含題主所說的Technical Spec)。所以這裏需要從官方的數據集出發去爬所需要的條目
數據的格式是TSV
可以用excel預覽一下
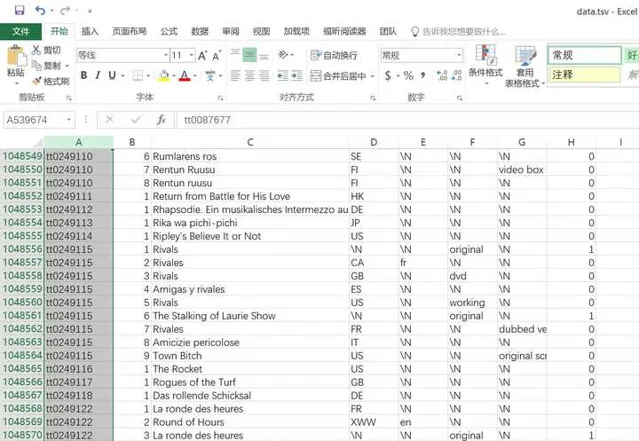
A列是電影的唯一標識ID,每個電影對應唯一一個ID
C列是電影的名字
官方數據集每天更新,所以無需擔心數據中不包含新電影
也就是說在這裏官方已經提供了一個完整的id集合。
這看起來是一個非常【爬蟲友好的網站】,都不用自己抓索引,自己就把所有索引直接給出了。
回到題主所需要的 Technical Spec 欄目
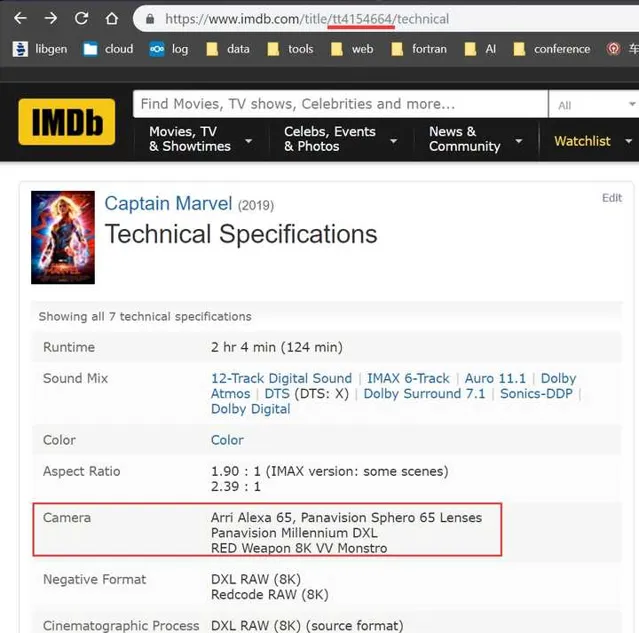
開啟某個電影的Technical Spec頁面,無需登入,位址列裏面t開頭的欄位就是ID,改變ID就可以存取不同電影的Technical Spec。
所以這個爬蟲的思路非常簡單,遍歷所有ID,把每個ID下的Technical Spec 頁面裏的Camera保存下來就OK
這裏需要使用urllib來獲取網頁,然後使用re來正規表式解析網頁找到我們需要的內容。
回到網頁按下F12開啟開發者模式
檢視對應內容是如何組織標簽的:
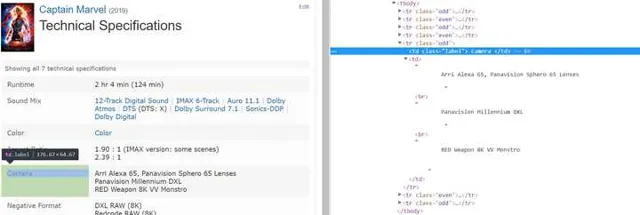
以上面這個電影的ID為例,用正規表式來提取這幾行裏的有用資訊(正規表式是一種從字串中尋找特定特征的字串的方法,具體可以參考Python 正規表式 | 菜鳥教程):
import
urllib.request
as
urlreq
import
re
id_str
=
'tt4154664'
x
=
urlreq
.
urlopen
(
"https://www.imdb.com/title/tt4154664/technical"
)
content_url
=
x
.
read
()
.
decode
(
'utf-8'
)
a
=
re
.
search
(
r
'<td class=\"label\"> Camera </td>.*?</td>'
,
content_url
,
re
.
S
)
res
=
re
.
sub
(
'<td.*?>|</td>|<br>'
,
''
,
a
.
group
())
print
(
res
)
程式碼中前兩行引入urllib用於網頁請求,引入re用於正規表式匹配。5-6行請求網頁,直接請求下來的網頁html是這樣的,需要從中提取有用資訊
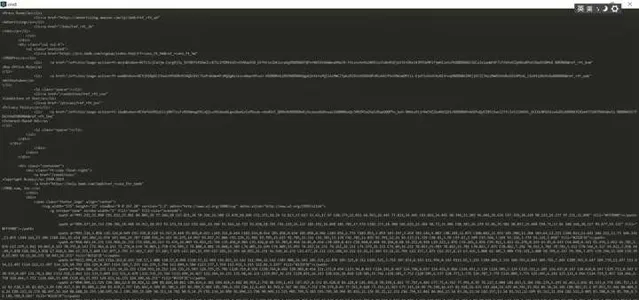
第7行使用re尋找所需要的內容,第八行整理一下,去掉<td>|</td>|<br> 這些標簽。
得到的內容應該是題主想要的Camera內容
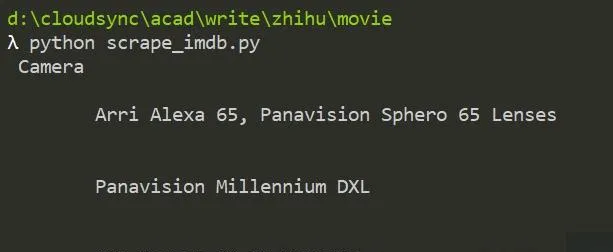
對於這一條成功的獲取了所需要的資訊。
接下來就是遍歷官方提供的整個大列表,收集所有電影的camera資訊,存入一個TSV或者CSV或者whatever。方便搜尋就行。
註:
根據IMDb官方條款,使用機器人批次收集資訊是違規的(來源: Conditions of Use - IMDb )
Robots and Screen Scraping: You may not use data mining, robots, screen scraping, or similar data gathering and extraction tools on this site, except with our express written consent as noted below.所以這裏不展開講如何改變user_agent,調節抓取間隔,使用代理,以及分布式抓取的方法
幾個電影相關的數據集
(IMDb的API授權非常的貴,爬蟲抓全站又違規,所以這裏列出幾個電影相關的現成數據集)
比較有名的是Kaggle裏的幾個:
IMDB 5000 Movie Dataset
IMDB Movies Dataset
IMDb官方提供的乞丐版也算上吧: - IMDb,https:// datasets.imdbws.com/
OMDb,一個提供開放API的電影資料庫 The Open Movie Database
=========
Pjer內容分類:
精選 射電 編程 科研&工具 太陽物理










