面試官 : 今天要不來聊聊Redis吧?
候選者 :好
候選者 :我個人是這樣理解的:無論Redis也好、MySQL也好、HDFS也好、HBase也好,他們都是儲存數據的地方
候選者 :因為它們的設計理念的不同,我們會根據不同的套用場景使用不同的儲存
候選者 :像Redis一般我們會把它用作於緩存
候選者 :當然啦,日常有的套用場景比較簡單,用個HashMap也能解決很多的問題了,沒必要上Redis
候選者 :這就好比,有的單機限流可能應對某些場景就夠用了,也沒必要說一定要上分布式限流把系統搞得復雜

面試官 : 你在計畫裏有用到Redis嗎?怎麽用的?
候選者 :Redis肯定是用到的,我負責的計畫幾乎都會有Redis的蹤影
候選者 :我舉幾個我這邊計畫用的案例唄?
面試官 :嗯
候選者 :我這邊負責訊息管理平台,簡單來說就是發訊息的
候選者 :那發完訊息肯定我們是得知道訊息有沒有下發成功的,是吧?
候選者 :於是我們系統有一套完整的鏈路追蹤體系
候選者 :其中即時的數據我們就用Redis來進行儲存,有即時肯定就會有離線的嘛(離線的數據我們是儲存到Hive的)
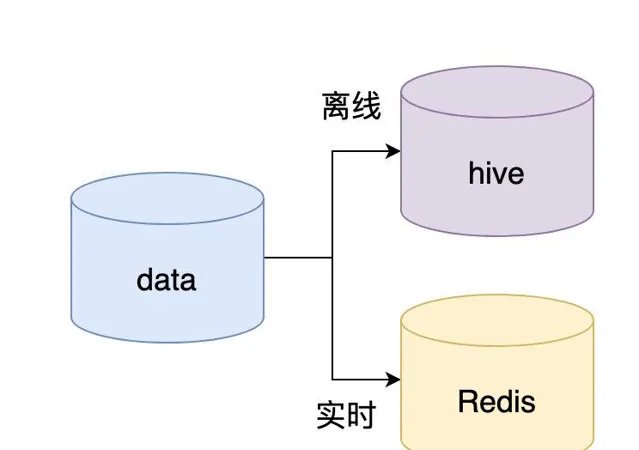
候選者 :對訊息進行即時鏈路追蹤,我這邊就用了Redis好幾種的數據結構
候選者 :分別有Set、List和Hash
面試官 :嗯….
候選者 :我再稍微鋪墊下鏈路追蹤的背景吧~
候選者 :要在訊息管理平台發訊息,首先得在後台新建一個「樣版」,有樣版自然會有一個樣版ID
候選者 :對樣版ID進行擴充套件,比如說加上日期和固定的業務參數,形成的ID可以唯一標識某個樣版的下發鏈路
候選者 :在系統上,我這邊叫它為UMPID
候選者 :在發送入口處會對所有需要下發的訊息打上UMPID,然後在關鍵鏈路上打上對應的點位

面試官 :嗯,你繼續吧
候選者 :接下來的工作就是清洗出統一的模型,然後根據不同維度進行處理啦。比如說:
候選者 :我要看某一天下發的所有樣版有哪些,那只要我把清洗出來後數據的,將對應UMPID扔到了Set就好了
候選者 :我要看某一個樣版的訊息下發的整體鏈路情況,那我以UMPID為Key,Value是Hash結構,Key是state,Value則是人數
候選者 :這裏的state我們在下發的過程中打的關鍵點位,比如接收到訊息打個51,訊息被去重了打個61,訊息成功下發了打個81…

候選者 :以UMPID為Key,Hash結構的Key(State)進行不斷的累加,就可以實作某一個樣版的訊息下發的整體鏈路情況
候選者 :我要看某個使用者當天下發的訊息有哪些,以及這些訊息的整體鏈路是如何。
候選者 :這邊我用的是List結構,Key是userId,Value則是UMPID+state(關鍵點位)+processTime(處理時間)
面試官 :嗯….
候選者 :簡單來說,就是透過Redis豐富的數據結構來實作對下發訊息多個維度的統計
候選者 :不同的套用場景選擇不同的數據結構,再等到透出做處理的時候,就變得十分簡單了
候選者 :訊息下發過程中去重或者一般正常的場景就直接Key-Value就能符合需求了
候選者 :像bitmap、hyperloglogs、sortset、steam等等這些數據結構在我所負責的計畫用得是真不多
候選者 :要是我有機會去到貴公司,貴公司有相關的套用場景,我相信我也很快就能掌握

候選者 :這些數據結構底層都由對應的object來支撐著,object記錄對應的「編碼」
候選者 :其實就是會根據key-value儲存的數量或者長度來使用選擇不同的底層數據結構實作
候選者 :比如說:ziplist壓縮列表這個底層數據結構有可能上層的實作是list、hash和sortset
候選者 :Hash結構的底層數據結構可能是hash和ziplist
候選者 :在節省記憶體和效能的考量之中切換
候選者 :Redis還是有點屌的啊。

面試官 : 就你上面那個即時鏈路場景,可以用其他的儲存替代嗎?
候選者 :嗯,理論上是可以的(或授權以嘗試用HBase),但總體來說沒這麽好吧
候選者 :因為Redis擁有豐富的數據結構,在透出的時候,處理會非常的方便。
候選者 :如果不用Redis的話,還得做很多解析的工作
候選者 :並且,我那場景的並行還是相當大的(就一條訊息發送,可能就產生10條記錄)
候選者 :監控峰值命令處理數會去到20k+QPS,當然了,這場景我肯定用了Pipeline的(不然處理會慢很多)
候選者 :綜合上面並行量和即時性以及數據結構,用Redis是一個比較好的選擇

面試官 :嗯…. 你覺得為什麽Redis可以這麽快?
候選者 :首先,它是純記憶體操作,記憶體本身就很快
候選者 :其次,它是單執行緒的,Redis伺服器核心是基於非阻塞的IO多路復用機制,單執行緒避免了多執行緒的頻繁上下文切換問題
候選者 :至於這個單執行緒,其實官網也有過說明(:表示使用Redis往往的瓶頸在於內與和網路,而不在於CPU
面試官 :了解。

【Java開源】訊息推播平台
我推薦一個 擁有從零開始的文件的計畫 ,既能用於畢設又可以在面試的時候大放異彩。
該計畫業務極容易理解,程式碼結構還算是比較清晰,最可怕的是幾乎每個方法和每個類都帶有中文註釋
擁有非常全的文件,作者從零搭建的過程一一都有記錄,計畫使用了蠻多的可靠和穩定的中介軟體的,包括並不限於SpringBoot、SpringDataJPA、MySQL、Docker、docker-compose、Kafka、Redis、Apollo、prometheus、Grafana、GrayLog、xxl-job等等。在使用每一個技術棧之前都講述了為什麽要使用,以及它的業務背景。我看過,他所說的場景是完全貼合線上環境的。
跟著README文件的部署使用姿勢就能跑起來,一步一步debug挺有意思的,作者還搞了個前端後台管理系統就讓整個系統變得更好理解了。並且在GitHub或者Gitee提的Issue幾乎都會有回復,也非常樂於合並開發者們的pull request,會讓人參與感賊強。
我相信在校、工作一年左右或常年做內網CRUD後台的同學去看看肯定會有所啟發,作者會經常在群裏回答該計畫相關的問題和程式碼設計思路。
B站也在開始更新訊息推播平台的視訊喲!
目前這個計畫GitHub和Gitee加起來已經 5K stars 了,我相信破萬是遲早的事情。 嗯,沒錯。這個計畫叫做austin, 是我寫的
訊息推播平台-Austin就是 奔著真實互聯網線上計畫 去設計和實作的,將計畫複制下來把中介軟體換成目前公司在用的,完善下基礎建設它就能成為線上計畫

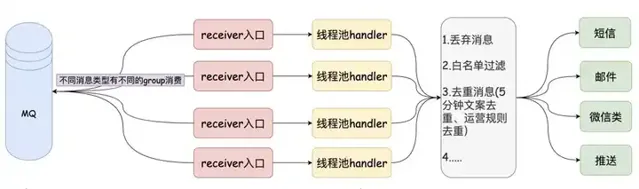
austin計畫 核心功能 :統一的介面發送各種型別訊息,對訊息生命周期全鏈路追蹤
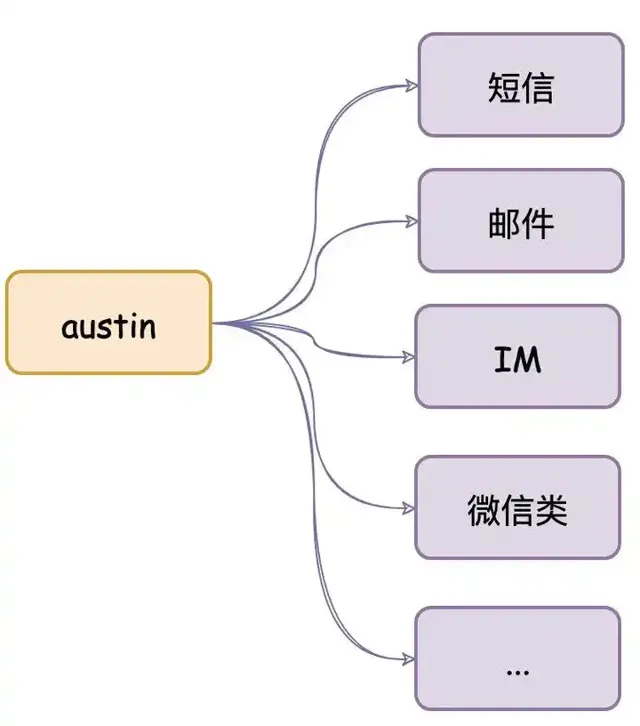
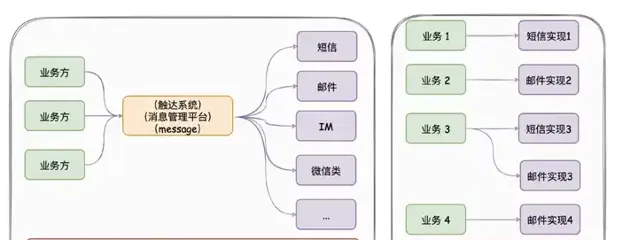
計畫出現意義 :只要公司內有發送訊息的需求,都應該要有類似austin的計畫,對各類訊息進行統一發送處理。這有利於對功能的收攏,以及提高業務需求開發的效率
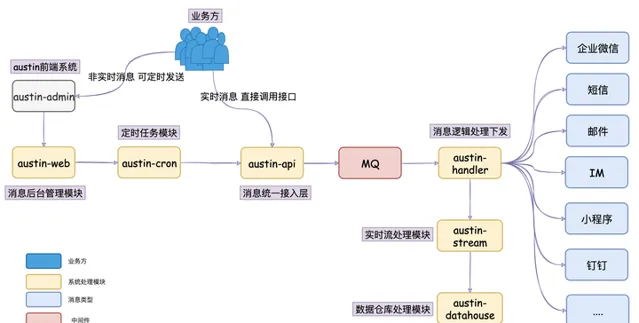
austin計畫 核心流程 :austin-api接收到發送訊息請求,直接將請求進MQ。austin-handler消費MQ訊息後由各類訊息的Handler進行發送處理


計畫Gitee連結:
計畫GitHub連結:










