0 引子
「透過分析統計jump各暢銷漫畫的分鏡、人設、台詞,我總結出了流行漫畫的理論,將其套用之後的成果就是【暗殺教室】。」 [1] ——松井優征

第一次看到這段話時,我就像被雷劈中了。因為松井和荒木不同:荒木是透過jojo漫長的創作歲月歸納出了方法論,才寫出了漫畫術;而是松井則是先有了理論並加以實踐,最終透過漫畫的暢銷證明了自己的理論——這種爽感大概和透過萬有重力定律發現海王星一樣,是令人無法抗拒的知性過程。更進一步的,松井還提到了對角色的身高進行了歸納整理,這似乎說明他的部份理論甚至是定量化的。
不管松井優征是不是在口胡,以這個時間點為界,我閱讀漫畫有意無意的想形成一套自己的準則方式,也會刻意去追尋定量化;比如,對漫畫章節回數的劃分,對周刊jump各型別漫畫數目的統計,等等。不過針對漫畫的成體系的方法論總因為水平不夠而淺嘗輒止。

直到最近開始閱讀一些文獻,我才發現許多一直想考察的內容已經有人專門研究過了。這就是我們今天要介紹的內容——電腦科學在漫畫領域的套用。
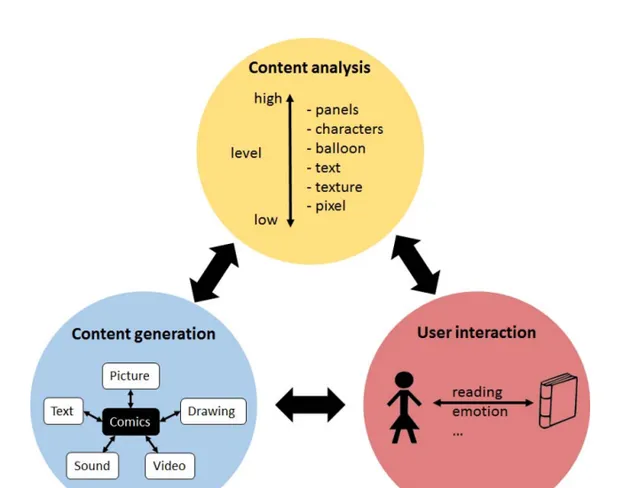
誠然,知乎比我既了解電腦科學也熟悉漫畫的大有人在,不過簡介整個領域的文章卻幾乎沒有。所以我只好越俎代庖一下,來簡單聊聊電腦科學近年來在漫畫領域的一些研究。這篇將對 漫畫內容分析 、 漫畫內容與讀者行為的關系 、 漫畫內容的生成以及向其他媒介的轉換 [2] [3] [4] 三個主要研究領域進行簡介。
後面至少還會寫一篇文章具體討論視線誘導,然後如果還有空閑,有機會的話大概會再詳細探討些別的內容。
比如:最近知乎有個問題探討鳥山明和北條司的受眾程度,在分析北條司的時候大多則提到了劇畫的衰落。那麽,什麽是劇畫?大多數人都能下個簡單的定義:更寫實化、符號化程度更低的漫畫。
那麽,寫實化什麽程度就算劇畫了呢?量度又是怎樣的呢?如果定量化,劇畫的特征是什麽?更進一步說,如何定義風格?這都是可以進一步思考的問題。而有研究已經涉及了這部份內容。

因為水平有限,本文可能存在諸多錯誤,請各位多批評;有些地方為了方便理解會難免廢話,各位見諒;因為是簡介,所以本文不涉及論文中提到的具體公式,如果感興趣可以去看相關文章;最後,如果這篇文章能促使在這方面更擅長的人寫點什麽更硬核的內容,那我也算是拋磚引玉了。
1 漫畫內容分析
漫畫是什麽?【理解漫畫】一書中,將其定義為「有意識的排列並置圖畫及其他影像」。我個人換一種說法:「有意識排列的影像及文本的組合」,或者更簡單的說, 漫畫=圖+文字+有意識的排列 。那麽如果對漫畫的內容進行分析,自然也是考察這些要素。
1.1 漫畫的元素
我們可以把漫畫的元素分的更細一些。如果只考察漫畫的「畫」,那麽至少有文字、影像、影像布局三方面要素。
其中,涉及「文字」的部份包括: 台詞和擬聲詞 ;台詞又可細分為有文字域的和沒有文字域的台詞;

同時,漫畫還有許多「符號化」的語言,比如上圖貝吉塔的汗珠,和各種可以表示角色心情的「符號」。
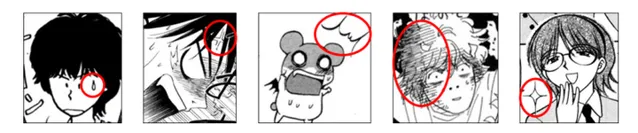
涉及「影像」的部份主要包括: 人物、背景、效果線 。更進一步的,又可以對人物的形態,面部要素等方面進行進行研究;影像的明暗對比涉及網點紙的疊加,故又可以考察網點紙的效果;效果線則起到視線誘導的作用 [5] 。另外,彩漫中因為涉及 色彩 ,所以其技法和黑白漫存在許多差異。

涉及影像布局的部份,即漫畫每頁 各幅畫的布局 。像上面這頁千佳的射擊就采用了跨頁和出血的效果;其他還有文字和人物的出格等和影像布局有關的內容。
當然,漫畫每頁的畫面構成只是一部份內容,而像世界觀、劇情、人設等難以量化的內容的討論,我們就不在這裏展開了。不過即使是分析以上這些看似簡單的概念,也會遇到相關問題——人雖然可以輕易辨識這些元素,但 電腦要如何去提取這些元素呢 ?下面依次舉例進行簡要說明。
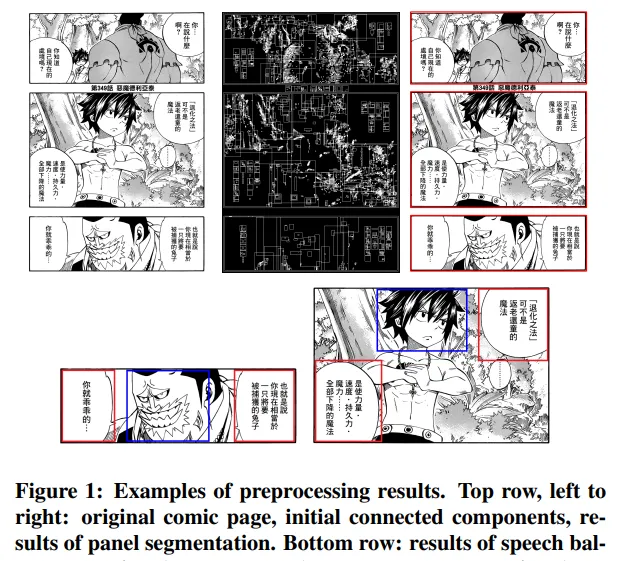
1.2 畫面切割
首先我們考察元素中相對比較好提取的要素——漫畫的分格。人的常規閱讀漫畫方式是和讀書一樣逐行的」Z字型「方式,但不同的分格手法會影響人的閱讀順序 [6] ,這就是漫畫采用多種分格布局的原因。
漫畫每格畫面之間一般存在著 間隔 ,透過控制間隔大小可以營造停滯感等效果。而間隔往往是純白或純黑的,所以電腦可透過明暗關系的改變來判斷各分格。
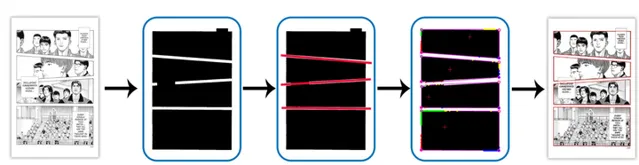
不過現實處理過程中自然不會像想象的那麽簡單,且不說以jojo分鏡為代表的各種稀奇古怪的畫面切割方式 [7] ,即使是橫平豎直的分格,當在分格中又出現新的分格(下圖e [8] )或破格導致畫面相疊(下圖h)的時候,該怎麽辦?
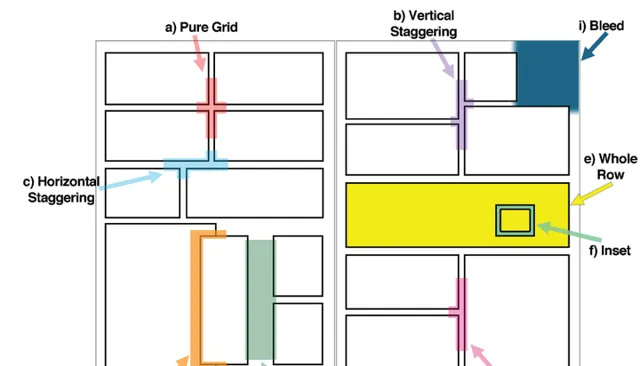
由此可見,單是簡單的分格,到實際處理時都會遇到諸多問題。所以不妨先解決部份情況——比如出格(與上圖h相關)的問題。比如,我們可以先把各分格全部塗黑,再透過出格部份占間隔的比例判斷是否刪去(比如設定當黑色部份<間隔線長度的0.2時,認為可以抹去) [9] 。
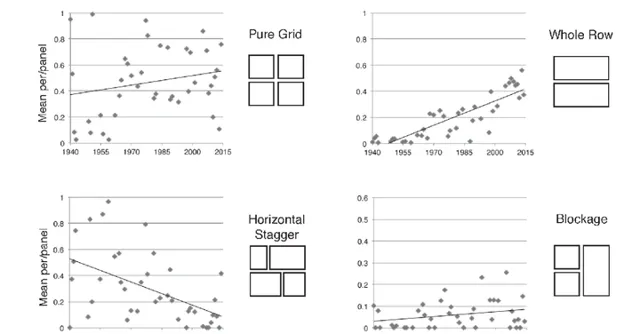
當然,我這裏只是做了簡單說明,近些年來各課題組針對該問題發展了一些方法。透過對分格的分析,根據漫畫資料庫,我們可以得到一些結論,比如各間隔方式的布局隨年份變化的情況。從下圖我們可以看出,美漫中跨單頁的分格明顯在逐年遞增 [10] ,而最近藤本樹在【再見繪梨】中大量套用了該型別的分格布局方式——藤本樹借鑒美漫的「證據」找到了(o゚ω゚o)。
1.3 文本提取
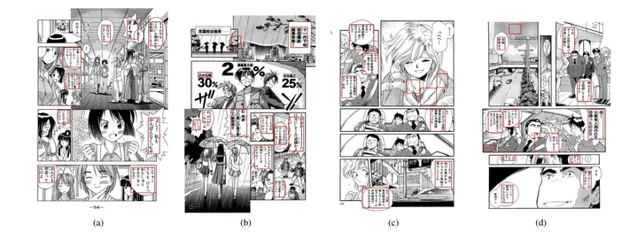
在區分出分格布局的基礎上,就可以考慮對文本內容進行提取了,知乎也有人做了類似的工具 [11] 。以文字域提取為例,常見的準則有兩類,分別是紋理(因為文字域內一般是純色),以及大小寬度等數據。當然也可直接透過文字準則——這就類似一些圖片轉譯軟體 [12] 。
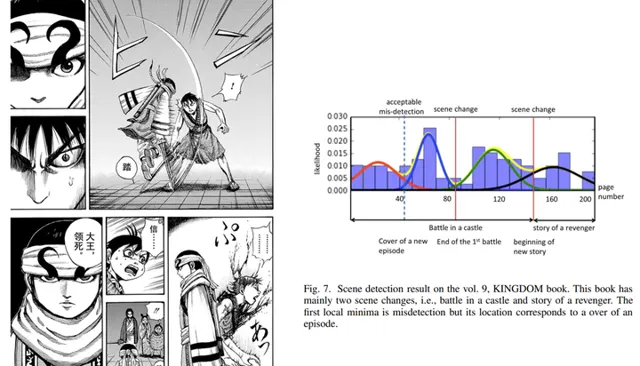
當然,也可以只分析特定的文本,比如【王者天下】中經常會出現只包含感嘆號的文字域,故可以透過其數量波動判斷故事場景的轉換 [13] [14] [15] ,如下右圖,可透過感嘆號的波動將第九卷拆分為三幕。
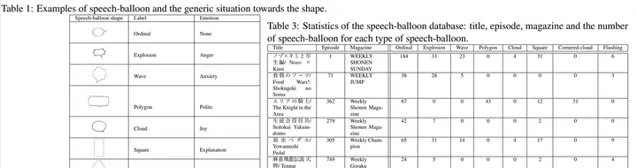
也可統計各文字域的形狀,不同形狀的文字域往往可以反映說話人不同的情緒 [16] ,比如下圖就統計了食戟之靈、妄想學生會、Billybat等漫畫中各文字域形狀的數目。具體我們不在這裏展開了。
1.4 人物形象資訊
荒木在自己的【漫畫術】中認為,角色是漫畫最重要的要素;近年熱門漫畫的一大優勢也是角色的塑造。不過人物資訊相對以上兩者顯然更難提取,所以經常需要采用機器學習的方法。常規提取人物資訊的方法往往是基於現實中的人體 [17] ,而漫畫中的人體存在諸多誇張,也難免存在變形,所以實際的方法一般不能直接移植到漫畫領域。

所以依舊可以選取較簡單的情況進行分析,比如只提取面部資訊;而眼睛則是人臉相對比較好提取的元素,因為眼睛一般都是圓形——由此可利用機器學習相關方法 [18] 先確定眼睛的位置,再透過眼睛和頭的對應比例以及各種輪廓線的檢測從而由眼睛外延確定頭像 [19] 。
我們知道少年漫、少女漫的風格往往是不同的,不同作家也存在著風格差異。在提取完頭像資訊之後,就可以繼續從頭像中提取對應的資訊,來調查各類漫畫之間的差異。
下表選擇了6種可以反映線條資訊的變量:比如l1即為相鄰線條之間的夾角;l2為各線段和水平線的夾角;l5則為具有相似方向的相鄰線條數目。之後,文章分別提取了少年漫畫雜誌少年jump,magazine,sunday和少女雜誌瑪格麗特、別冊friend、Sho-Comi中共240副頭像的對應變量進行比較。
當然,變量可以隨意選取,之後再透過數據處理篩選即可找到能用來反映差異的元素。比如下表就是以p值 [20] 作為量度,當p值越小(即加粗的數據)時,該變量判斷兩者不同的說服力越強。

1.5 相關工具與小節
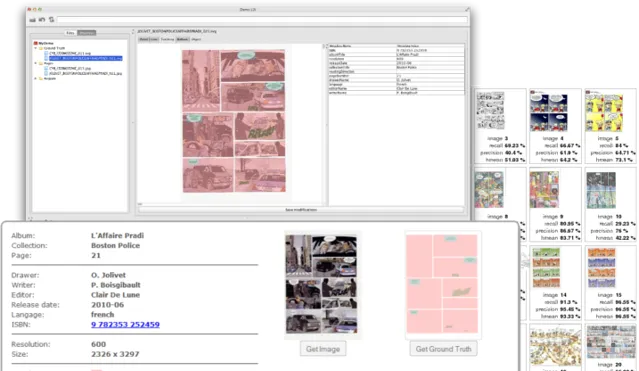
利用電腦分析漫畫,既需要各種處理工具 [2] ,也需要相關的資料庫——比如eBDtheque [21] ,comics [22] 這兩個資料庫,可以直接提取一些資訊。
這部份我們分三類漫畫元素各自舉了一些例子,其實其他可考察的物件還很多,比如之前提到的網點,就有文章嘗試以網點的多少作為判斷作者風格的量度之一。
以上提到的內容大體是 只基於漫畫 進行分析,但是漫畫是要有 讀者去讀去進行互動 的。所以接下來,我們在這基礎上引入讀者,看看讀者對漫畫會做出怎樣的反應。
2 漫畫內容與讀者行為的關系
少年Jump一直賴以生存的一項指標就是其順位制度;另一方面,有答主 [23] 認為編輯需要為海賊和之國、火影四戰、死神血戰篇的諸多問題負很大責任,因為編輯作為作品的「第一位讀者」,理應起到把關作用。那麽如果能預測讀者閱讀漫畫時的反應,對於創作漫畫無疑是大有裨益的。
2.1 視線誘導
視線誘導不僅套用於漫畫領域,在電影、美術作品、建築領域、媒體界、設計界都有套用。漫畫自然也不例外,視線誘導是控制漫畫閱讀節奏的核心要素。
想必各位看過許多視線誘導的標註,比如下圖是我隨手搜的龍珠視線誘導圖 [24] ;不過為什麽視線誘導就是下面這樣?為什麽不是其他的連結方式?或者說線到底該怎麽連?什麽是好的視線誘導方式?
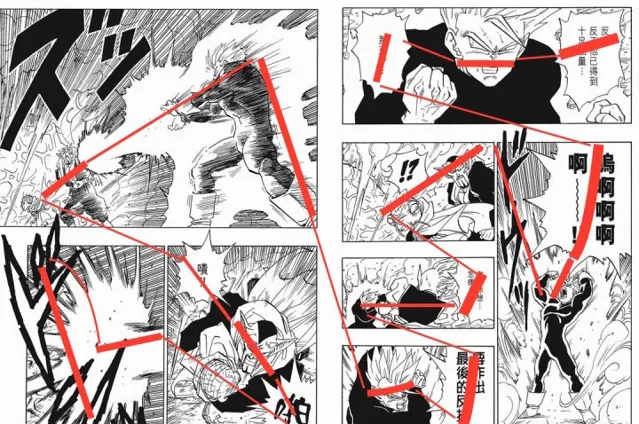
另外,我們連的線,真的是原版日漫的想體現的視線誘導嗎?比如上圖右上的擬聲詞,日本人會不會因為能夠辨識文字而在那裏停留,而我們因為母語不是日語而導致視線誘導和日本人不同呢? [25] 我認為顯然是會的。

最準確和嚴謹的辦法自然是找一組人來看漫畫做實驗,透過 眼球跟蹤器 追蹤人眼球的活動,再進行處理將其對映到螢幕上,從而得到最終的視線誘導軌跡。比如下圖是【王者天下】中的視線誘導圖 [26] ,由此,我們可以得到大量的樣本,再透過機器學習的辦法並進一步分析,即可得到視線誘導的影響因素。
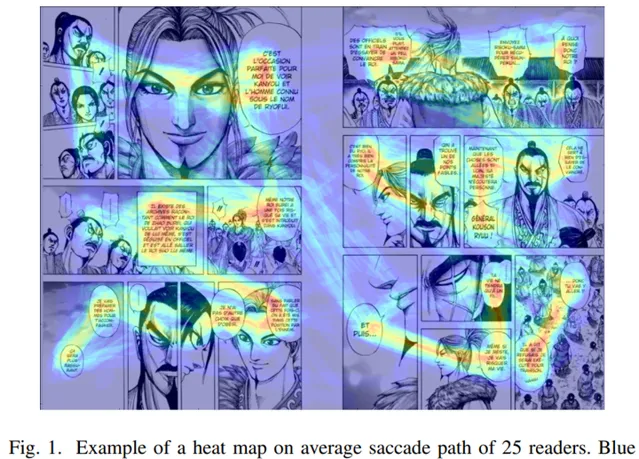
知乎有涉及這方面內容的問題 [27] ,我個人目前認為漫畫視線誘導可以看作是作者透過控制畫面不同位置資訊的疏密來達到的,而人眼會傾向於關註短時能獲取最多資訊的地方。而好的視線誘導,至少要做到讓讀者把所有作者想提供的資訊都收集到,更進一步則要讓讀者照作者的想法來調控閱讀的速度。
更具體的視線誘導分析涉及速度線、文字域、明暗對比、條漫、彩漫等諸多因素,之後會寫文章深入討論。
2.2 生理訊號
也有課題組對人閱讀漫畫時的情緒變化進行了研究。比如有課題組 [28] 透過對人體脈搏,體溫等數據的分析,可以準確預測受檢測者閱讀的漫畫是什麽型別漫畫。
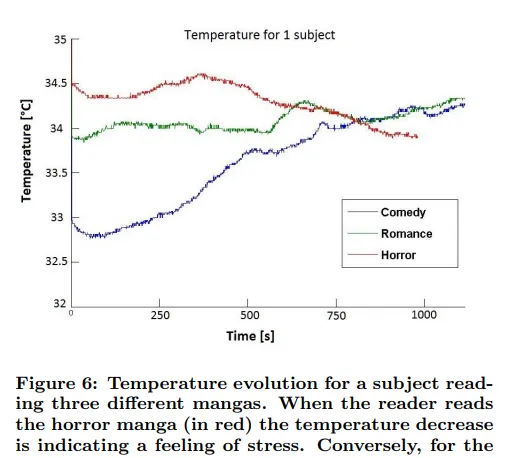
知乎有個問題是恐怖漫畫如何營造電影或遊戲中常出現的jump scare [29] (直譯:嚇你一大跳),我認為這部份研究大概可以為解決該問題提供一些幫助。
2.3 小結
顯然,還有許多人體訊號可以監測,不過我覺得監測有些訊號可能合理,但有些就未免有點大炮打蚊子的感覺。
和讀者行為有關的內容不止這些;比如,如果用手機閱讀,因為螢幕比較小,閱讀漫畫需要點選螢幕放大或下滑,由此漫畫會和讀者產生更多的互動;又比如,為了學生能高效愉快的學習,有許多人將課程或書籍做成了漫畫形式 [30] 。相關的漫畫各位可能也見到過——比如歐姆社那套入門書籍。我認為這某種程度上可視為該領域的成果。這方面內容我們會在第三節中再次提及。

以上是從讀者視角上考慮問題。自然也可以將視角放在 創作者 身上,看看電腦是怎樣輔助創作者們制作漫畫的。
3 與漫畫內容生成相關的問題
板繪雖然相對手繪有些質感可能無法做到,但相對有著易修改,易儲存,速度較快等優勢。比如,淺野一二〇在【惡魔的破壞】中的巨大兵器就是透過各種零件的拼接制作出來的。近年來,一些涉及漫畫自動化創作的工具逐漸被開發了出來,比如3D建模軟體;各種漫畫樣版也陸續投入了套用,比如近年jump+的自制漫畫軟體。
另一方面,對「漫畫」概念的「拓展」和媒介的變換也成為了熱點話題,比如萬惡的「講漫」概念的提出 [31] 。

不過總歸,經濟基礎決定上層建築,生產力決定生產關系,自動化工具帶來的高效率會使作者有更多時間思考劇情,從而創作出更優質的內容。
3.1 內容生成
除了上面提到的3D建模,常見的還有AI上色 [32] ,有些計畫正在尋求商業化。下圖是github上的萬星計畫 [33] [34] ,輸入線稿後分三步添加色塊、顏色漸變、陰影,最後得到成品。
不過註意一點,彩漫和黑白漫的技法有本質上的不同,這是在創作漫畫中需要考慮的問題。

相關的還有照片變為漫畫 [35] [36] 等計畫,有的已經做成了app,這方面文章知乎就有。總之,只要有心找一找,不難看到AI作畫方面的進展。下圖就是AI創作的幾幅作品 [37] 。

3.2 媒介轉換
有一些研究著眼於將漫畫直接透過程式轉換為動態漫畫,比如下面這個視訊就是透過電腦模擬攝影機運動的方法自動得到的一段灌籃高手的動態漫畫 [38] 。
 https://www.zhihu.com/video/1506041145716686848
https://www.zhihu.com/video/1506041145716686848
另外,考慮到盲人無法閱讀漫畫,所以現在也有研究致力於將漫畫轉換為盲文或者錄音的形式。
3.3 小結
我其實對這部份的一些工作有些看法。暫且不談幫助盲人閱讀漫畫的問題,我們究竟如何定義「漫畫」?回到一開始的定義,漫畫是「有意識排列的影像及文本的組合」。
那麽講漫似乎幾乎沒有有意識的影像布局,算漫畫還是算視訊?再比如下面這個「互動漫畫」,可以透過移動螢幕調整觀看漫畫的視角,從而實作部份3D的效果 [39] 。這種效果如果更進一步,比如透過視角隱藏線索,是不是就變成了遊戲了?
這是需要重視的問題,因為如果不小心,漫畫難免可能成為其他媒介的附庸。

另一方面,AI技術日新月異,這自然是好的,畢竟提高了效率,但這也導致了部份漫畫家的劃水,比如某天天看管人玩apex夢想「成為攝影家」的漫畫家就總用3D模型直接描圖。那麽未來AI會不會逐步替代漫畫家?我想還是不會的,就像【詩雲】裏講的那樣。雖然以上提到了各種漫畫相關的研究,但追根到底,漫畫畢竟是人創作的作品。總之,我期待技術逐步解放漫畫家們的生產力,也相信和希望AI替代漫畫家的那天在我有生之年不會到來。
結語
漫畫研究涉及心理學、美學、建築學等多個領域,本文只是簡要對電腦科學在漫畫領域的研究做個介紹。希望這篇文章可以對各位研究漫畫提供新的視角。
畢竟,當你接受不了漫畫表現論那一套學術性語言;認為齊澤克佶屈聱牙於是只好將文章放到我的最愛中吃灰;對東浩紀伊藤剛四方田犬彥表示雖覺厲但不明;對什麽無調性世界什麽大他者主客體的含義更是一頭霧水;那麽來看看基於數據分析的,可以證偽的IEEE論文也不失為另一條道路 [40] 。因為,數據不會騙人 [41] 。

溜了溜了。
參考
- ^ 少年jump50周年,NHK紀錄片。
- ^ a b Augereau O, Iwata M, Kise K. An overview of comics research in computer science[C]//2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). IEEE, 2017, 3: 54-59.
- ^ Augereau O, Iwata M, Kise K. A survey of comics research in computer science[J]. Journal of imaging, 2018, 4(7): 87.
- ^ 我這篇總體上是基於這兩篇綜述。
- ^ 其他涉及影像的還有諸如:色相、飽和度、動態模糊等方面的內容。
- ^ Cohn N. Navigating comics: an empirical and theoretical approach to strategies of reading comic page layouts[J]. Frontiers in psychology, 2013, 4: 186.
- ^ 荒木割り https://moebius.exblog.jp/6209517/
- ^ Pederson K, Cohn N. The changing pages of comics: Page layouts across eight decades of American superhero comics[J]. Studies in Comics, 2016, 7(1): 7-28.
- ^ Pang X, Cao Y, Lau R W H, et al. A robust panel extraction method for manga[C]//Proceedings of the 22nd ACM international conference on Multimedia. 2014: 1125-1128.
- ^ Pederson K, Cohn N. The changing pages of comics: Page layouts across eight decades of American superhero comics[J]. Studies in Comics, 2016, 7(1): 7-28.
- ^https://zhuanlan.zhihu.com/p/27563287
- ^ Piriyothinkul B, Pasupa K, Sugimoto M. Detecting text in manga using stroke width transform[C]//2019 11th International Conference on Knowledge and Smart Technology (KST). IEEE, 2019: 142-147.
- ^ file:///C:/Users/yunsh/Desktop/manga/文本分析-王者Histogram_of_Exclamation_Marks_and_Its_Application_for_Comics_Analysis.pdf
- ^ 我嚴重懷疑有一個實驗組特別喜歡王者,一共看到了好幾篇拿王者分析的文章。
- ^ 這篇其實還考察了阿特曼的漫畫。
- ^ Yamanishi R, Tanaka H, Nishihara Y, et al. Speech-balloon shapes estimation for emotional text communication[J]. Information Engineering Express, 2017, 3(2): 1-10.
- ^ Cao Z, Simon T, Wei S E, et al. Realtime multi-person 2d pose estimation using part affinity fields[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 7291-7299.
- ^ 如SVM演算法
- ^ Chu W T, Chao Y C. Line-based drawing style description for manga classification[C]//Proceedings of the 22Nd ACM international conference on multimedia. 2014: 781-784.
- ^ Li J, Yao L, Hendriks E, et al. Rhythmic brushstrokes distinguish van Gogh from his contemporaries: findings via automated brushstroke extraction[J]. IEEE transactions on pattern analysis and machine intelligence, 2011, 34(6): 1159-1176.
- ^https://ebdtheque.univ-lr.fr/database/?overview=1
- ^https://obj.umiacs.umd.edu/comics/index.html
- ^https://www.zhihu.com/question/530470941/answer/2468876777
- ^ 視線誘導 https://zhuanlan.zhihu.com/p/20441746
- ^ Rohan O, Sasamoto R, O'Brien S. Onomatopoeia: A relevance-based eye-tracking study of digital manga[J]. Journal of Pragmatics, 2021, 186: 60-72.
- ^ Rigaud C, Le T N, Burie J C, et al. Semi-automatic text and graphics extraction of manga using eye tracking information[C]//2016 12th IAPR Workshop on Document Analysis Systems (DAS). IEEE, 2016: 120-125.
- ^https://www.zhihu.com/question/502580823/answer/2249216543
- ^ Sanches C L, Augereau O, Kise K. Manga content analysis using physiological signals[C]//Proceedings of the 1st International Workshop on coMics ANalysis, Processing and Understanding. 2016: 1-6.
- ^https://www.zhihu.com/question/50716876/answer/122352558
- ^ Ramadhan R H, Ratnaningtyas L, Kuswanto H, et al. Analysis of Physics Aspects of Local Wisdom: Long Bumbung (Bamboo Cannon) in Media Development for Android-Based Physics Comics in Sound Wave Chapter[C]//Journal of Physics: Conference Series. IOP Publishing, 2019, 1397(1): 012016.
- ^ 所以「講漫」什麽時候上熱搜?
- ^ Casey E, Pérez V, Li Z. The Animation Transformer: Visual Correspondence via Segment Matching[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 11323-11332.
- ^https://github.com/lllyasviel/ style2paints
- ^https://zhuanlan.zhihu.com/p/77620838
- ^https://zhuanlan.zhihu.com/p/76936166
- ^https://zhuanlan.zhihu.com/p/76936166
- ^https://archive.org/details/1111101000-robots
- ^ Cao Y, Pang X, Chan A B, et al. Dynamic manga: Animating still manga via camera movement[J]. IEEE Transactions on Multimedia, 2016, 19(1): 160-172.
- ^http://andrebergs.com/protanopia/?msclkid=50e91b3bcd2511ec9570737ad11c5ee2
- ^ 我真的沒有針對誰的意思。
- ^ 其實數據騙人的事情也多了。











