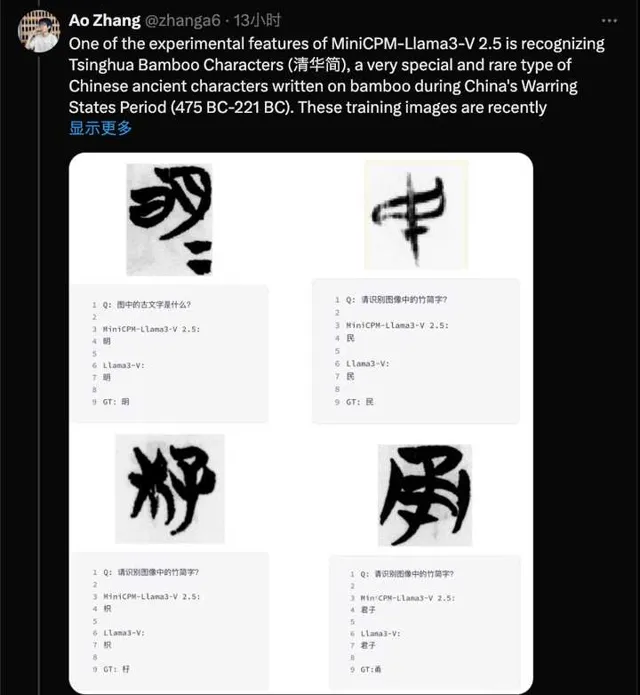
有感而發說幾句。已經比較確信Llama3-V是對我們MiniCPM-Llama3-V 2.5套殼,比較有意思的證據是MiniCPM-Llama3-V 2.5研發時內建了一個彩蛋,就是對清華簡的辨識能力。這是我們從清華簡逐字掃描並標註的數據集,並未公開,而Llama3-V展現出了一模一樣的清華簡辨識能力,連做錯的樣例都一樣。
人工智慧的飛速發展離不開全球演算法、數據與模型的開源共享,讓人們始終可以站在SOTA的肩上持續前進。我們這次開源的 MiniCPM-Llama3-V 2.5 就用到了最新的Llama3 作為語言模型基座。而開源共享的基石是對開源協定的遵守,對其他貢獻者的信任,對前人成果的尊重和致敬,Llama3-V團隊無疑嚴重破壞了這一點。他們在受到質疑後已在Huggingface刪庫,該團隊三人中的兩位也只是史丹佛大學本科生,未來還有很長的路,如果知錯能改,善莫大焉。
OpenBMB團隊是開源社群的受益者,也一直是積極的貢獻者,從最初的CPM模型、BM Infra系列,到後來的Ultra對齊技術、ChatDev等Agent計畫系列,再到今年的MiniCPM。這次看到大家在twitter、github和pyq上對我們的支持和聲援,讓我們倍感欣慰,給我們更大的動力和信心繼續擁抱開源共享。
這次事件還讓我感慨的是過去十幾年科研經歷的鬥轉星移。回想2006年我讀博時,大家的主要目標還是能不能在國際頂級會議上發篇論文;到2014年我開始做老師時,就只有獲得國際著名會議的最佳論文等重要成果,才有機會登上系裏的新聞主頁;2018年BERT出來時,我們馬上看到了它的變革意義,做出了知識增強的預訓練模型ERNIE發在ACL 2019上,當時以為已經站到國際前沿了;2020年OpenAI釋出了1700+億參數GPT-3,讓我們清醒認識到與國際頂尖成果的差距,知恥而後勇開始了「大模型」的探索;2022年底OpenAI推出的ChatGPT,讓大眾真切感受到AI領域國內外的差距,特別是2023年Llama等國際開源模型釋出後,開始有「國外一開源、國內就自研」說法;而到了2024年的今天,我們也應該看到國內大模型團隊如智譜-清華GLM、阿裏Qwen、DeepSeek和面壁-清華OpenBMB正在透過持續的開源共享,在國際上受到了廣泛的關註和認可,這次事件也算側面反映我們創新成果受到的國際關註。

所以,從橫向來看,我們顯然仍與國際頂尖工作如Sora和GPT-4o有顯著差距;同時,從縱向來看,我們已經從十幾年的nobody,快速成長為人工智慧科技創新的關鍵推動者。面向即將到來的AGI時代,我們應該更加自信積極地投身其中。
前段時間OpenBMB周年紀念,寫過一段寄語,與大家共勉:「通用人工智慧,是人類文明的共同夢想;人人為我、我為人人的開源精神,正是人類文明之光,邁向通用人工智慧之路必須也必將由全人類智慧的開源共享而鑄就。OpenBMB正是抱著這樣的使命和願景一路走來。星星之火,可以燎原,希望未來OpenBMB不斷壯大,與全球AI從業者攜手,加速邁向通用人工智慧的星辰大海。」
歡迎關註點贊我們的MiniCPM-V計畫:
github:https:// github.com/OpenBMB/Mini CPM-V
huggingface:openbmb/MiniCPM-Llama3-V-2_5 · Hugging Face











