本人從事人臉辨識相關工作,這一波人工智慧投資風刮起來,很多人臉辨識公司恨不得馬上往自己臉上貼幾噸金,有個朋友說了一句很有意思的話:
外行一般覺得很科幻,內行一般覺得很絕望,業界領袖和資本狂魔各種打雞血。
大部份AI公司都在燒錢階段,未來變現有很大的不確定性。看看百度自動駕駛的系統和google影像辨識系統的開放可以預知未來免費是大趨勢,那可是曾經投入數百億美元。但是資本投進來,必須拉著媒體一起吆喝,不然本都回不了(進入AI行業才知道很多資本方原來什麽也不懂亂投)。
人臉辨識作為一項模組技術很少有獨立套用(獨立的業務層設計),大部份只是為已有的業務軟體體系上做增強,比如客戶人臉校驗(在過去密碼基礎上增加一層),人臉檢索(比人工高效,網路攝影機結果過濾),相似人臉推薦(比如婚介社交,整容設計),不過這個過程中已經死掉大量公司,因為利潤太少,非強需求。
目前相關產業公司在已知的主要商業模式中都在實踐,但 賣貨,賣授權,賣服務,後台流量變現 這四大商業模式中,都沒有看到一個公司真正賺錢了(常見主要為人臉sdk授權和api服務)。 作為行業中人,所謂的絕望無非如下:
1. 演算法再好,也只是調味料,最終出路還是做到最終產品中,透過業務層疊加開發,形成產品和方案,更多時候是一個方案服務商,更像過去傳統軟體商,規模難有爆發。
2. 使用門檻、成本很低,目前市場上終端演算法部署比較低端的產品授權就500元/套(1:1的遠端介面呼叫所使用的前端授權),市場競爭的結果就是低價傾銷。甚至還有特例,演算法完全免費。
人臉辨識行業真實情況:
人臉辨識目前就是為了各種噱頭立項、經費申請瓜分用的,有個別一些公司靠這個拿國家各種科技補貼。但真正賺錢都是那些中間商公司,人臉辨識一家都沒有。至於未來有沒有新商業模式出現,暫且無法推斷。
這幾年許多公司紮堆做萬億級市場的安防和最新的手機網路攝影機辨識,但是在整條產業鏈中,只是極小的參與者(沒有太大話語權),比如安防的,在過去最大的贏家是有全套安防軟硬體監控體系的海康和大華,人臉辨識增強了其本來的產品優勢。做手機人臉解鎖,最重要的是手機網路攝影機部件廠商整合(比如做3D結構光辨識),而這些廠商的利潤經過這幾年的競爭幾乎透明化了,部份配件龍頭上市公司的年報營收300億,毛利潤才幾個億,最終可以給人臉辨識技術提供商提供多少專利費還是個未知數。對於一些埋頭玩演算法的公司是巨大打擊,基本都陸陸續續變成方案整合商,但是每一家公司的需求不一樣,需要單獨客製,導致這個行業無法直接復制,也無法進行互聯網方式的估價。
人臉辨識技術沒有想象中的那樣偉大,在千萬的業務解決方案中,就是一個小模組,其他的都是業務層的開發問題,使用上,技術也未必要高精尖,如果一定要真正稱得上人工智慧組成部份的,個人認為未來最大的使用端是機器人視覺互動。
--------以下為答案--------
題主問題比較寬泛(到底是盈利強,還是演算法強,還是套用強?),人臉辨識技術的衡量維度太多,但從技術比較,比如影像比對級的1:1,1:N,N:N;衡量的標準和維度都不同。比如演算法精確度上,國內國外的人臉辨識技術大多數在開源OPENCV等開源庫上進行新規則添加(深度學習進行疊層運算),公司之間的辨識正確率差異僅僅在小數點上,99.6%-99.7%提升意義不大,如果說在LFW上稱王稱霸就是世界一流,就要被內行笑話了。
衡量人臉辨識的演算法能力幾個指標:拒識率、誤識率、透過率,準確率。
先看看人臉辨識的基本流程:
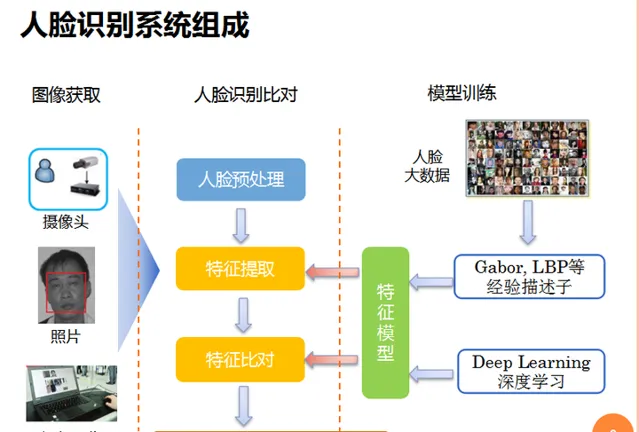
人臉辨識最難的部份是有充分適應各大光線環境的人臉預處理演算法,需要在各種復雜的光線環境中提取到人臉資訊,特別是行動網際網路時代,網路攝影機拍照的地方可以在斑駁的樹影下,也可以在昏暗的街燈下,以及深夜出租車內,這對演算法的魯棒性考驗極大。同時還要考慮照片和視訊欺詐,二次成像的光線汙染等問題。
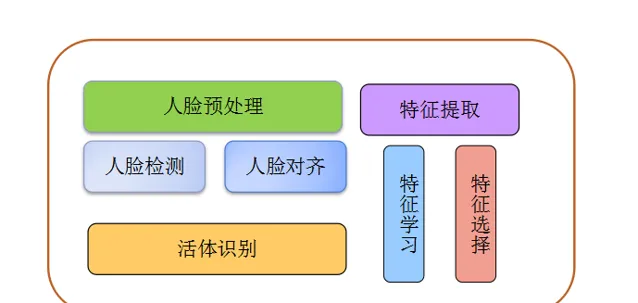
下面說一下目前人臉辨識的常見問題:
1:1人臉辨識演算法主要用於身份驗證
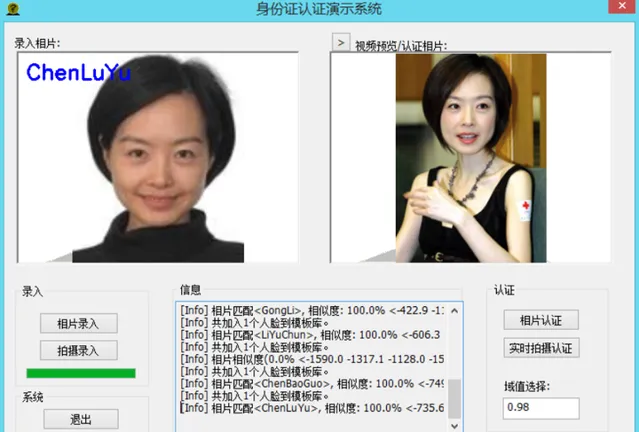
1:1人臉辨識技術主要是利用影像處理技術從影像中提取人像特征點,利用生物統計學的原理進行分析建立數學模型,即人臉特征點模型。再從人臉特征點模型與被測者的人的面像進行特征分析(可以假定為無數的幾何特征點求解),根據分析的結果來給出一個相似值,透過這個值即可確定是否為同一人。簡單的說就是A/B兩張照片比對,產生的計算數值是否達到要求。
這個值我們稱之為閾值,可以從1到100(100就是極端嚴苛)很多人臉辨識公司說他們的產品很容易透過,那只說了一半,如果閾值調整到5以下,幾乎大部份人都可以是相似的,而調整到95以上,同一個人在不同的背景環境拍出的照片都無法匹配。所以當一公司跟你吹牛演算法準確度,先問下使用的是用什麽閾值,同一人臉比對透過率,非同一人比對透過率。所以沒有閾值說明的演算法都是耍流氓。
1:1主要用於快速的人臉辨識比對,作為身份確認的一種新方式,比如考生身份確認、公司考勤確認、各種證件照和本人確認,由於這些照片源不一定有權威統一的介面呼叫,所以一直沒有用起來。目前市面上做的比對來源主要有三種方式:
1. 使用者自傳照片,比如支付寶的人臉比對,使用者自傳的照片最大的問題是照片品質的合格率太低,拍照的光線、角度等因素會導致采集源的品質下降,不利於後期的大批次人臉特征碼管理。
2. 使用身份證讀卡器,讀取身份證上的照片,遺憾的是這張照片2K的大小,不過也是目前用最多的源照片提取方式,比較適合簽到場合。
2016給國內一些會議培訓公司的辨識軟體(用於驗證會員是否有效以及是否本人):

3. 使用公安部旗下NCIIC的人臉比對介面(註意,不是網紋照片介面,這個介面已經不對外),使用的是直接的人臉比對介面。目前具備有這個庫呼叫許可權的,目前所知的只有幾家,在人臉辨識公司中,好像只看到一家在提供,這裏先不提了。BAT應該都還沒有接入,如有大家有新發現的可以補充。
實際上,解決比對源的問題的關鍵是需要有權威的照片數據來進行比對,許多公司剛剛開始的時候采取NCIIC(公安部的一個事業單位)身份證返照介面的照片,進行消網紋處理進行比對,但人臉的很多特征點被損毀成功率大概只有6成(根據六月份釋出的網路安全法,目前網紋返照介面市面上除了銀行系統可以使用外,其他所用的身份證返照介面都是非法的,一用就被查)。
1:1 人臉辨識演算法主要使用場景
曾經有一些問題是關於如何確認本人的笑話,派出所要求一個小夥證明就是本人,證明你媽是你媽。。這種奇葩問題,但是許多陌生場合也有這種尷尬,你如果沒有帶證件,警察無法看到你的照片,如何確認你就是XX就是之前經常出現的執法矛盾;如果一個人把身份證弄丟了,外面風雪交加,如何給這類人辦理酒店入住手續?這些就是身份確認的問題。公安部推身份證網上副本 身份認證可「刷臉」完成就是用來解決這個問題,我們出門不用完全依賴身份證可以確定身份,可以方便很多。
但是1:1人臉演算法的巨大隱患是我們隨處可見的人臉,實際就是一個公開的鑰匙,馬雲提出刷臉消費吃飯,如果沒有手機驗證碼(本身也是一重手機實名驗證,同時做了人臉庫圖源定位,方便1:1校驗),分分鐘鐘被吃垮。但是既然可以用手機,為什麽還用刷臉,不是多此一舉嗎?
另外還有一些高級會所,希望實作VIP的貴賓警報服務,這個在下面的1:N和N:人臉辨識演算法系統中可以看到。但是1:1比對的身份套用哪家強了?
在互聯網買機票、車票,醫院掛號,政府惠民工程計畫,以及各種證券開戶、電信開戶、互聯網金融開戶都會用到。過去的身份認證方式是非常不妥的(比如支付寶的持有註冊流程,還有一些不知名的社交APP等需要上傳身份證照片),這些資料是極其容易被盜取和轉賣的,下圖是來自百度的圖片搜尋結果截圖,還有最近的一些女大學生的裸條資料泄露知乎專欄,導致犯罪分子有很多利用的漏洞,黑客軍團號稱資料2000萬,分分鐘鐘薅幹一家金融平台沒有問題(以下來自百度身份證搜尋結果截圖):

人臉辨識的破解:
許多金融公司喜歡把人臉辨識SDK模組嵌入到APP當中,但這個太容易繞過,所以會再加上活體檢測(市場上常見的活體檢測為隨機動作配合),但是即便加了活體檢測,也一樣可以繞過。比如下面這兩種方式:
1. 3D人臉仿真面具

2. 人臉模型即時重建
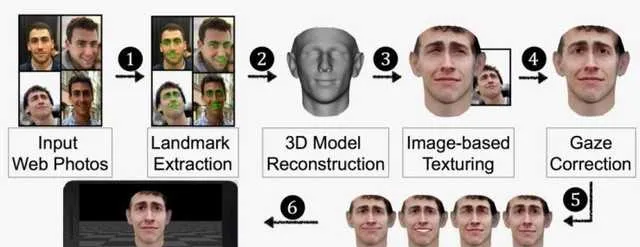
所謂道高一尺魔高一丈,這個還是增加其他的多維校驗才能確認身份,否則真有人要進行遠端攻擊,也不是很難的事情。那麽活體檢測哪家強了?
1:N人臉辨識演算法主要用於人臉檢索
跟1:1的A/B兩張照片比對最大的區別是A/B A/C A/D……多個1:1計算,這個最大的問題是一旦BCD總和數量越大計算速度越慢,而總和超過20萬,就回出現多個相似結果(20萬人這個大數會導致有不少人長相相似),需要人工輔助定位。過去我們在電影裏面看到什麽「天網」辨識系統只是一種理想狀態,實際套用中都是排列出多個結果,排第一的未必是需要的人。
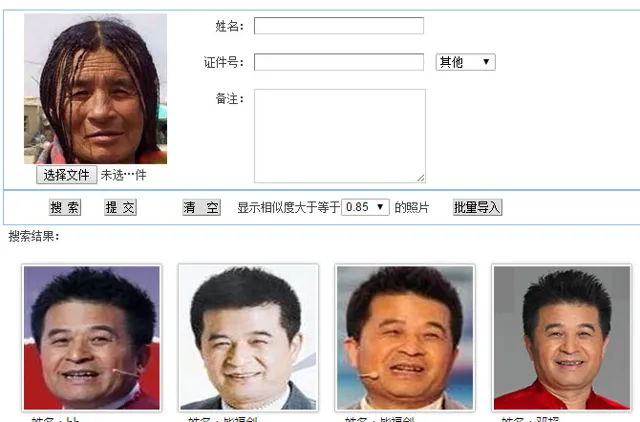
1:N人臉辨識演算法主要用於排查犯罪嫌疑人、失蹤人口的全庫搜尋、一人多證的重復排查,以此相似度列出相應的結果,可以大大提高排查效率。類似的也可以用到走失兒童的計畫中去。
這一類系統的部署需要兩個條件:
1. BCD基本庫(比如1000萬人)
2. 強大的演算法硬體
1:N同時作業就是N:N了,同時相應多張照片檢索需求,檢索耗費的時間跟硬體演算法關系極大,就這一領域的套用,又哪家公司強了?
N:N人臉辨識演算法主要用於即時多1:N檢索計算:
N:N 該演算法實際上是基於1:N的演算法,輸入多個求解結果。比如視訊流的幀處理所用,對伺服器的計算環境要求嚴苛,目前的演算法系統所支撐的輸出率非常有限。
主要的限制如下:
海量的人臉照片解析需要大量運算(目前很少看到在采集端直接解析的,都是照片剪裁)
海量的人臉照片傳輸需要大量的頻寬(常見的720布控網路攝影機抓取最小的人臉照片為20K)
海量的人臉照片在後台檢索需要耗費大量的運算(國內主流主機為例,最多到24路網路攝影機)
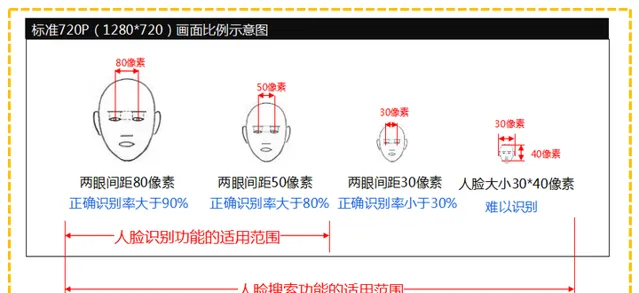
由此可見,真正實作「天網」人臉檢索,一來要解決數億網路攝影機的圖片處理,二來需要解決聯合庫的超算檢索,這可不是一般公司吃得消。有些小區和高級場所,對VIP客戶的辨識和接待比較喜歡這種視訊校驗方式,但是實際部署使用者會受到網路攝影機位置、角度,以及多人同時入場產生的問題,而且人臉庫會非常有限,不然計算時間長,體驗極差,一些所謂的迎賓機通常也就幾個人的照片(就是純粹給領導看的),實用價值大大的打折扣,有戴墨鏡或者帽子遮蔽都認不出,畢竟關鍵特征取樣有限。這又有誰強了?
拍照和直播APP的人臉影像疊加
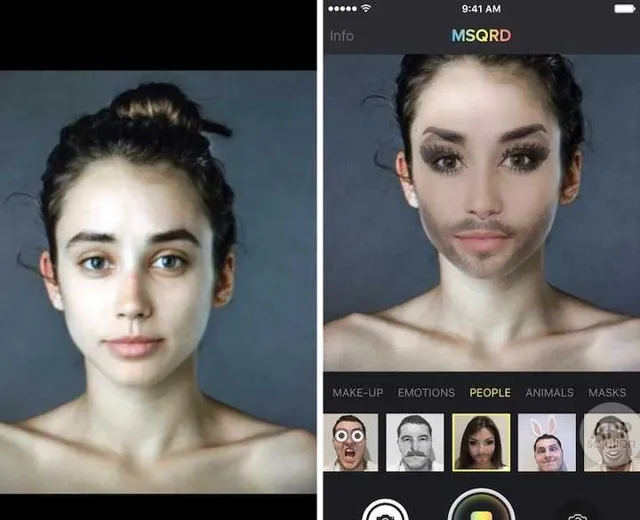
國內比較多的娛樂APP透過對人像圖層跟蹤處理,也是一個不錯的技術切入點,但是產品安裝包會比較大,現在做的也只是跟蹤技術,屬於底層辨識,如果復雜一些的需要透過雲服務實作,但是伺服器演算法解析速度和頻寬比較難以跟上,也不算是一種靠譜的商業模式。
人臉辨識的技術發展方向:
結合三維資訊: 二維和三維資訊融合使特征更加魯棒多特征融合: 單一特征難以應對復雜的光照和姿態變化
大規模人臉比對: 面向海量數據的人臉比對與搜尋
深度學習: 在大數據條件下充分發揮深度神經網路強大的學習能力
在視訊級N:N的校驗中,如果要提高透過率,很多時候是采取降低準確率的方式,降低演算法佇列數量;同樣在一些比賽中為了降低誤識率,大大提高了準確率,所以演算法在校驗的過程中必須遵循至少一個固定標準,追求的是速度效率還是最高準確率。
人臉辨識演算法的套用分類派系:
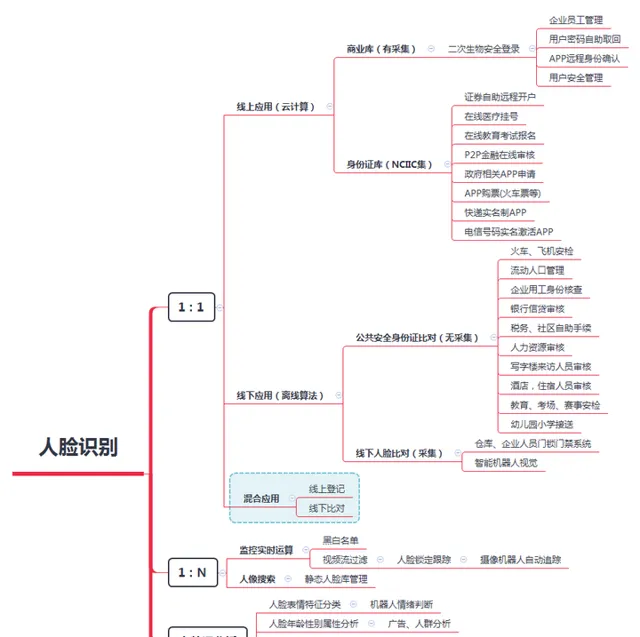
人臉辨識對應解決方案方向:
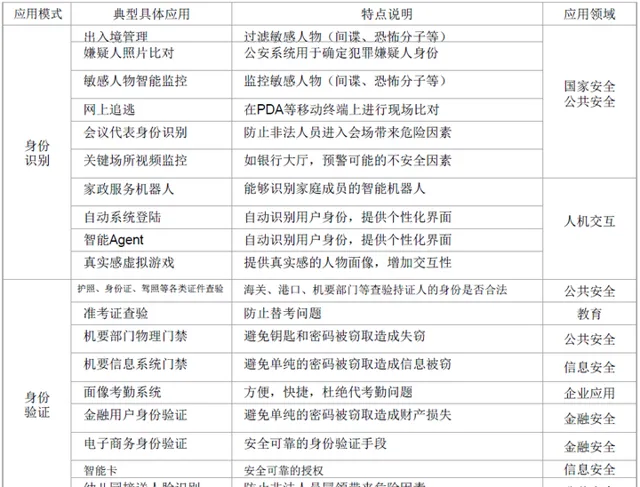
個人認為未來人臉辨識會讓大部份的數據更加真實,而可以透過社會工程學樣版做很多分析和改良,比如近期一些科學家利用人臉辨識來分析一些人的健康、清晰,甚至是犯罪傾向,或許在未來還可以結合大數據,對我們過去傳統的面相分析技術做一個全新的提升,到時候算命先生都要失業了。更多機器人互動、無人機產生的攝像目標釘選分析等科幻畫面並不是多遙遠的事情。
關於演算法核心研發情況的爭論:
基本上國內每家公司都會說自己的演算法牛 ,實際上有幾家有人臉核心演算法呢?國內在完全從事演算法研究的總工程師人數到目前(2016年)總計不到100人,不過也沒有現在問題也不大,中科院計算所山世光教授已經開源了SeetaFace開源人臉辨識引擎介紹 - 知乎專欄,沒有基礎的公司不用太辛苦從零開始在OPENCV基礎上做演算法升級,相信很快google微軟還會有新的演算法釋出。現在演算法基本都是98%以上,這點差距已經不重要,演算法核不核心也沒有太大問題。大家不用太過於焦慮,產品到套用階段,單單靠演算法可不夠,還要考慮實際的使用。
目前做人臉辨識的公司很多,整合套用的有數百家,國內的看百度,看融資,看各種報道就差不多了,只是認真沈下心來做事情的公司太少。國內的騰訊和阿裏都在做(阿裏支付寶用的是自己的團隊研發演算法,只是特別低調,把名聲都留給自己投資的公司,阿裏可不止投了一家),國內的公司吹牛逼的、炒概念的太多,就不聊了。這些公司 幾乎做的都是政府的安全計畫 ,但公司普遍規模都很小,盈利和投資也很少見報道。Facebook公司進入這個領域,主要是進行人群的分類和套用的最佳化(針對性的市場推廣),計畫都是作為公司原本業務的一種補充。
所以這個問題到了最後,答案很簡單:
人臉辨識哪家強並不重要,
未來的競爭不在現在這些戰場。
借用雷布斯的話:少一些胡來的人,大家都可以專心做事。
人工智慧投資泡沫帶來的浮躁,反而讓大家都不好好做事情了,所以花了時間整理了這篇,潑了點冷水,期待同行們真真正正為社會提供一些有價值的,也有資本報酬的產品。











