貝葉斯定理太有用了,不管是在投資領域,還是機器學習,或是日常生活中幾乎都在用到它。
例如,生命科學家用貝葉斯定理研究基因是如何被控制的;教育學家意識到,學生的學習過程其實就是貝葉斯法則的運用;基金經理用貝葉斯法則找到投資策略;谷歌用貝葉斯定理改進搜尋功能,幫助使用者過濾垃圾信件;無人駕駛汽車接收車頂傳感器收集到的路況和交通數據,運用貝葉斯定理更新從地圖上獲得的資訊;人工智慧、機器轉譯中大量用到貝葉斯定理...
我將從以下4個角度來科普貝葉斯定理及其背後的思維:
1.貝葉斯定理有什麽用?
2.什麽是貝葉斯定理?
3.貝葉斯定理的套用案例
4.生活中的貝葉斯思維
1.貝葉斯定理有什麽用?英國數學家湯瑪斯·貝葉斯(Thomas Bayes)在1763年發表的一篇論文中,首先提出了這個定理。而這篇論文是在他死後才由他的一位朋友發表出來的。
(ps:貝葉斯定理其實就是下面圖片中的機率公式,這裏先不講這個公式,而是重點關註它的使用價值,因為只有理解了它的套用意義,你才會更有興趣去學習它。)

在這篇論文中,他為了解決一個「逆機率」問題,而提出了貝葉斯定理。
在貝葉斯寫這篇文章之前,人們已經能夠計算「正向機率」。什麽是正向機率呢?舉個例子,杜蕾斯舉辦了一個抽獎,抽獎桶裏有10個球,其中2個白球,8個黑球,抽到白球就算你中獎。你伸手進去隨便摸出1顆球,摸出是中獎球的機率是多大。

根據頻率機率的計算公式,你可以輕松的知道中獎的機率=中獎球數(2個白球)/球總數(2個白球+8個黑球)=2/10
如果還不懂怎麽算出來的,可以看我之前寫的科普機率的回答:猴子:如何理解條件機率?
而貝葉斯在他的文章中是為了解決一個「逆機率」的問題。比如上面的例子我們並不知道抽獎桶裏有什麽,而是摸出一個球,透過觀察這個球的顏色,來預測這個桶裏裏白色球和黑色球的比例。
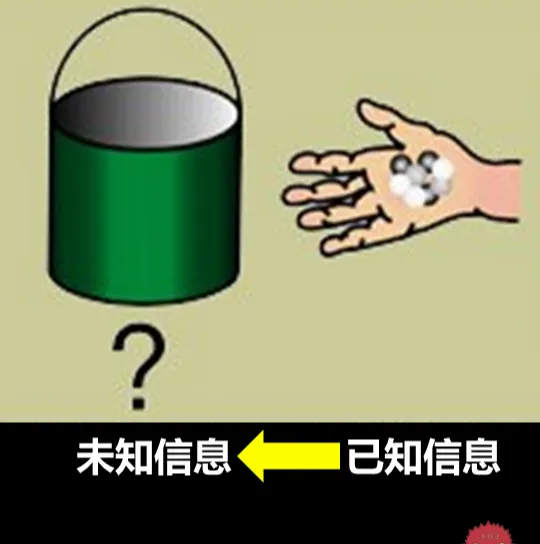
這個預測其實就可以用貝葉斯定理來做。貝葉斯當時的論文只是對「逆機率」這個問題的求解嘗試,這哥們當時並不清楚這裏面這裏麵包含著的深刻思想。
然而後來,貝葉斯定理席卷了機率論,並將套用延伸到各個領域。可以說,所有需要作出機率預測的地方都可以見到貝葉斯定理的影子,特別地,貝葉斯是機器學習的核心方法之一。
為什麽貝葉斯定理在現實生活中這麽有用呢?
這是因為現實生活中的問題,大部份都是像上面的「逆機率」問題。因為生活中絕大多數決策面臨的資訊都是不全的,我們手中只有有限的資訊。既然無法得到全面的資訊,我們就只能在資訊有限的情況下,盡可能做出一個好的預測。
比如天氣預報說,明天降雨的機率是30%,這是什麽意思呢?
我們無法像計算頻率機率那樣,重復地把明天過上100次,然後計算出大約有30次會下雨(下雨的天數/總天數)
而是只能利用有限的資訊(過去天氣的測量數據),用貝葉斯定理來預測出明天下雨的機率是多少。
同樣的,在現實世界中,我們每個人都需要預測。想要深入分析未來、思考是否買股票、政策給自己帶來哪些機遇、提出新產品構想,或者只是計劃一周的飯菜。
貝葉斯定理就是為了解決這些問題而誕生的,它可以根據過去的數據來預測出未來事情發生機率。
貝葉斯定理的思考方式為我們提供了有效的方法來幫助我們做決策,以便更好地預測未來的商業、金融、以及日常生活。
總結下第1部份:貝葉斯定理有什麽用?
在有限的資訊下,能夠幫助我們預測出機率。
所有需要作出機率預測的地方都可以見到貝葉斯定理的影子,特別地,貝葉斯是機器學習的核心方法之一。例如垃圾信件過濾,中文分詞,愛滋病檢查,肝癌檢查等。
2.什麽是貝葉斯定理?貝葉斯定理長這樣:
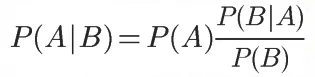
到這來,你可能會說:猴子,說人話,我一看到公式就頭大啊。
其實,我和你一樣,不喜歡公式。我們還是從一個例子開始聊起。
我的朋友小鹿說,他的女神每次看到他的時候都沖他笑,他現在想知道女神是不是喜歡他呢?
誰讓我學過統計機率知識呢,下面我們一起用貝葉斯幫小鹿預測下女神喜歡他的機率有多大,這樣小鹿就可以根據機率的大小來決定是否要表白女神。
首先,我分析了給定的已知資訊和未知資訊:
1)要求解的問題:女神喜歡你,記為A事件
2)已知條件:女神經常沖你笑,記為B事件
所以,P(A|B)表示女神經常沖你笑這個事件(B)發生後,女神喜歡你(A)的機率。
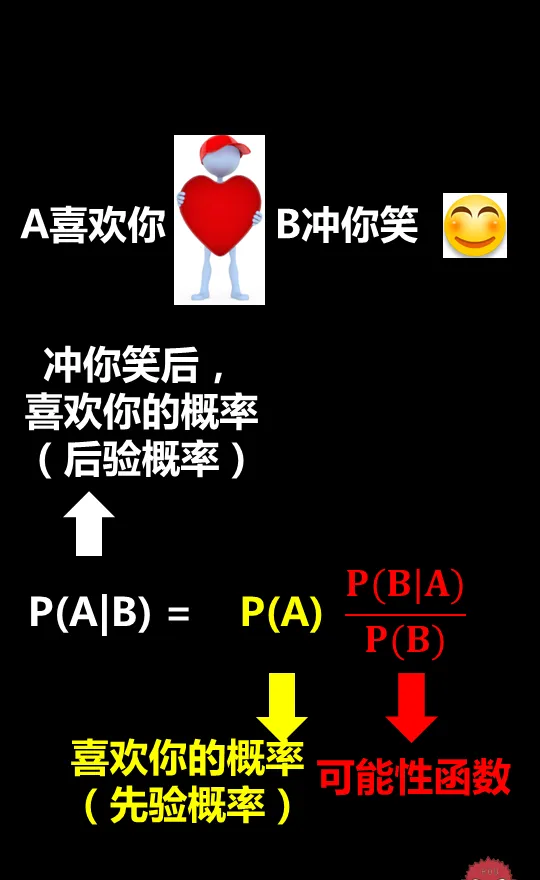
從公式來看,我們需要知道這麽3個事情:
1)先驗機率
我們把P(A)稱為"先驗機率"(Prior probability),也就是在不知道B事件的前提下,我們對A事件機率的一個主觀判斷。
對應這個例子裏就是在不知道女神經常對你笑的前提下,來主觀判斷出女神喜歡一個人的機率。這裏我們假設是50%,也就是不喜歡你,可能不喜歡你的機率都是一半。
2)可能性函式
P(B|A)/P(B)稱為"可能性函式"(Likelyhood),這是一個調整因子,也就是新資訊B帶來的調整,作用是將先驗機率(之前的主觀判斷)調整到更接近真實機率。
可能性函式你可以理解為新資訊過來後,對先驗機率的一個調整。比如我們剛開始看到「人工智慧」這個資訊,你有自己的理解(先驗機率-主觀判斷),但是當你學習了一些數據分析,或者看了些這方面的書後(新的資訊),然後你根據掌握的最新資訊最佳化了自己之前的理解(可能性函式-調整因子),最後重新理解了「人工智慧」這個資訊(後驗機率)
如果"可能性函式"P(B|A)/P(B)>1,意味著"先驗機率"被增強,事件A的發生的可能性變大;
如果"可能性函式"=1,意味著B事件無助於判斷事件A的可能性;
如果"可能性函式"<1,意味著"先驗機率"被削弱,事件A的可能性變小。
還是剛才的例子,根據女神經常沖你笑這個新的資訊,我調查走訪了女神的閨蜜,最後發現女神平日比較高冷,很少對人笑,也就是對你有好感的可能性比較大(可能性函式>1)。所以我估計出"可能性函式"P(B|A)/P(B)=1.5(具體如何估計,省去1萬字,後面會有更詳細科學的例子)
3)後驗機率
P(A|B)稱為"後驗機率"(Posterior probability),即在B事件發生之後,我們對A事件機率的重新評估。這個例子裏就是在女神沖你笑後,對女神喜歡你的機率重新預測。
帶入貝葉斯公式計算出P(A|B)=P(A)* P(B|A)/P(B)=50% *1.5=75%
因此,女神經常沖你笑,喜歡上你的機率是75%。這說明,女神經常沖你笑這個新資訊的推斷能力很強,將50%的"先驗機率"一下子提高到了75%的"後驗機率"。

在得到機率值後,小鹿自信滿滿的發了下面的表白微博:
稍後,果然收到了女神的回復。預測成功。
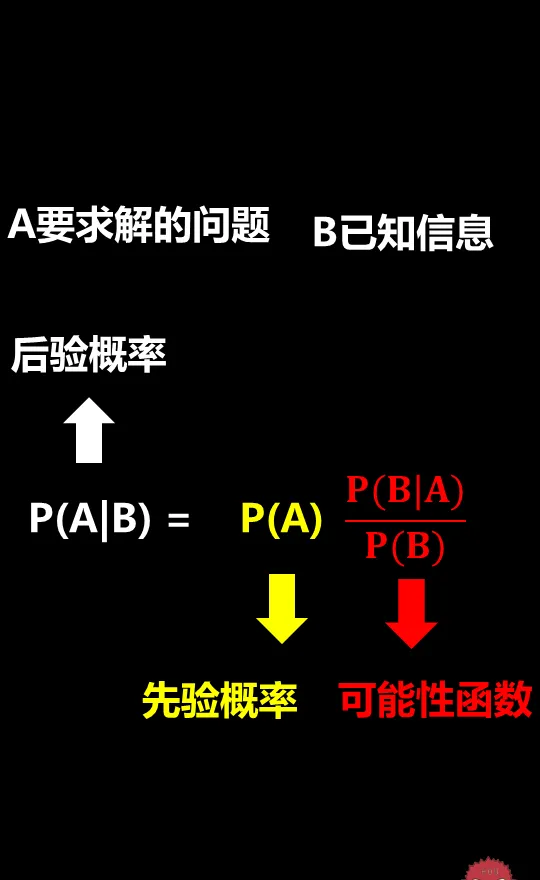
現在我們再看一遍貝葉斯公式,你現在就能明白這個公式背後的關鍵思想了:
我們先根據以往的經驗預估一個"先驗機率"P(A),然後加入新的資訊(實驗結果B),這樣有了新的資訊後,我們對事件A的預測就更加準確。
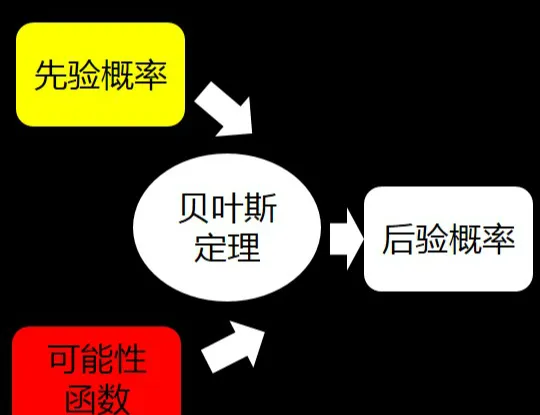
因此,貝葉斯定理可以理解成下面的式子:
後驗機率(新資訊出現後的A機率) = 先驗機率(A機率) x 可能性函式(新資訊帶來的調整)
貝葉斯的底層思想就是:
如果我能掌握一個事情的全部資訊,我當然能計算出一個客觀機率(古典機率)。
可是生活中絕大多數決策面臨的資訊都是不全的,我們手中只有有限的資訊。既然無法得到全面的資訊,我們就在資訊有限的情況下,盡可能做出一個好的預測。也就是,在主觀判斷的基礎上,你可以先估計一個值(先驗機率),然後根據觀察的新資訊不斷修正(可能性函式)。
如果用圖形表示就是這樣的:
其實Alpha狗也是這麽戰勝人類的,簡單來說,Alpha狗會在下每一步棋的時候,都可以計算自己贏棋的最大機率,就是說在每走一步之後,他都可以完全客觀冷靜的更新自己的機率值,完全不受其他環境影響。
3.貝葉斯定理的套用案例前面我們介紹了貝葉斯定理公式,及其背後的思想。現在我們來舉個套用案例,你會更加熟悉這個牛瓣的工具。
為了後面的案例計算,我們需要先補充下面這個知識。
1.全機率公式
這個公式的作用是計算貝葉斯定理中的P(B)。
假定樣本空間S,由兩個事件A與A'組成的和。例如下圖中,紅色部份是事件A,綠色部份是事件A',它們共同構成了樣本空間S。

這時候來了個事件B,如下圖:

全機率公式:
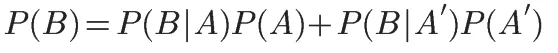
它的含義是,如果A和A'構成一個問題的全部(全部的樣本空間),那麽事件B的機率,就等於A和A'的機率分別乘以B對這兩個事件的條件機率之和。
看到這麽復雜的公式,記不住沒關系,因為我也記不住,下面用的時候翻到這裏來看下就可以了。
案例1:貝葉斯定理在做判斷上的套用
有兩個一模一樣的碗,1號碗裏有30個巧克力和10個水果糖,2號碗裏有20個巧克力和20個水果糖。
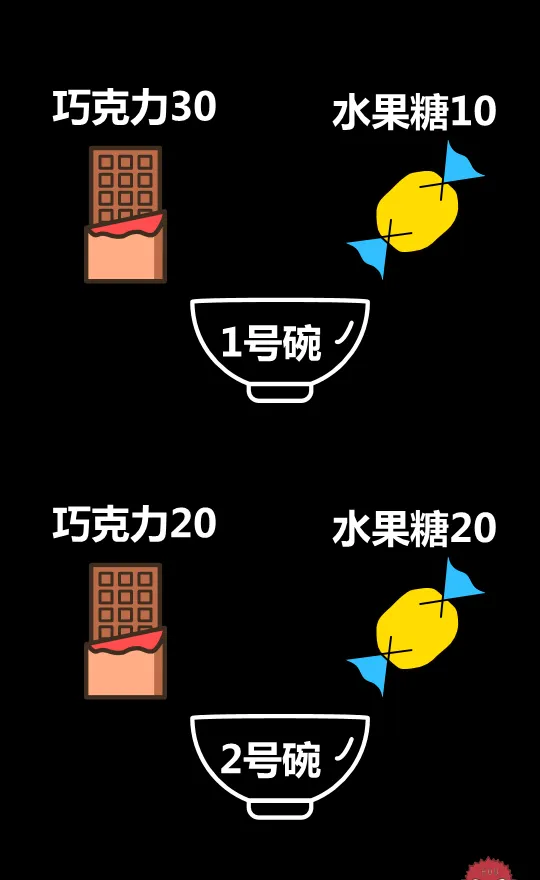
然後把碗蓋住。隨機選擇一個碗,從裏面摸出一個巧克力。
問題:這顆巧克力來自1號碗的機率是多少?
好了,下面我就用套路來解決這個問題,到最後我會給出這個套路。
第1步,分解問題
1)要求解的問題:取出的巧克力,來自1號碗的機率是多少?
來自1號碗記為事件A1,來自2號碗記為事件A2
取出的是巧克力,記為事件B,
那麽要求的問題就是P(A1|B),也就是取出的是巧克力(B),來自1號碗(A1)的機率
2)已知資訊:
1號碗裏有30個巧克力和10個水果糖
2號碗裏有20個巧克力和20個水果糖
取出的是巧克力
第2步,套用貝葉斯定理
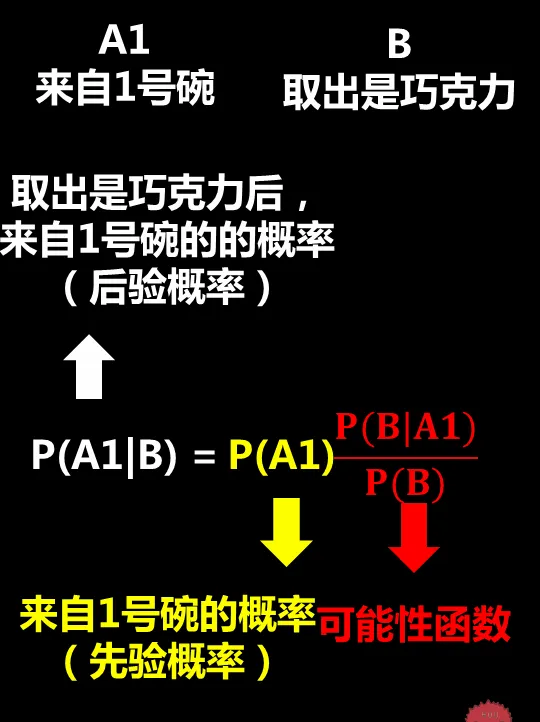
1)求先驗機率
由於兩個碗是一樣的,所以在得到新資訊(取出是巧克力之前),這兩個碗被選中的機率相同,因此P(A1)=P(A2)=0.5,(其中A1表示來自1號碗,A2表示來自2號碗)
這個機率就是"先驗機率",即沒有做實驗之前,來自一號碗、二號碗的機率都是0.5。
2)求可能性函式
P(B|A1)/P(B)
其中,P(B|A1)表示從1號碗中(A1)取出是巧克力(B)的機率。
因為1號碗裏有30個巧克力和10個水果糖,所以P(B|A1)=巧克力數(30)/(糖果總數30+10)=75%
現在貝葉斯公式裏只剩P(B)了,只有求出P(B)就可以得到答案。
根據全機率公式,可以用下圖求得P(B):
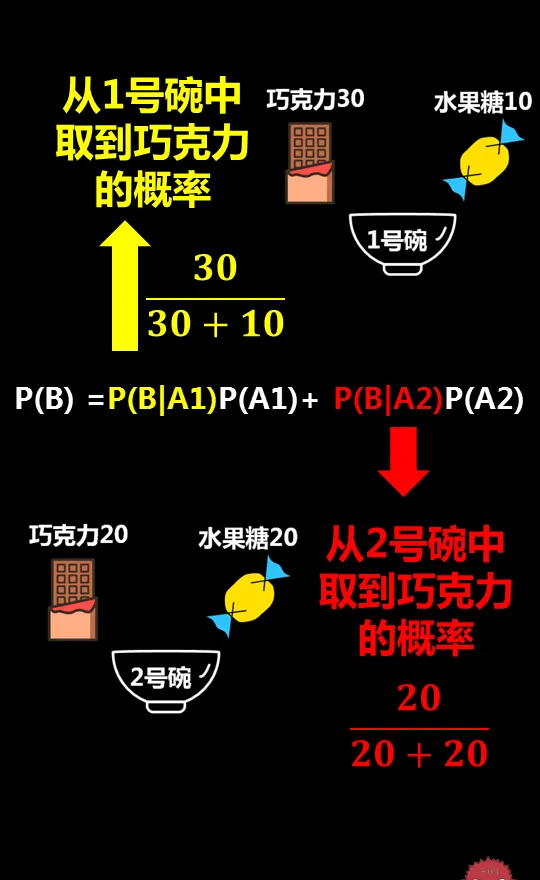
圖中P(B|A1)是1號碗中巧克力的機率,我們根據前面的已知條件,很容易求出。
同樣的,P(B|A2)是2號碗中巧克力的機率,也很容易求出(圖中已給出)。
而P(A1)=P(A2)=0.5
將這些數值帶入公式中就是小學生也可以算出來的事情了。最後P(B)=62.5%
所以,可能性函式P(B|A1)/P(B)=75%/62.5%=1.2。
可能性函式>1.表示新資訊B對事情A1的可能性增強了。
3)帶入貝葉斯公式求後驗機率
將上述計算結果,帶入貝葉斯定理,即可算出P(A1|B)=60%
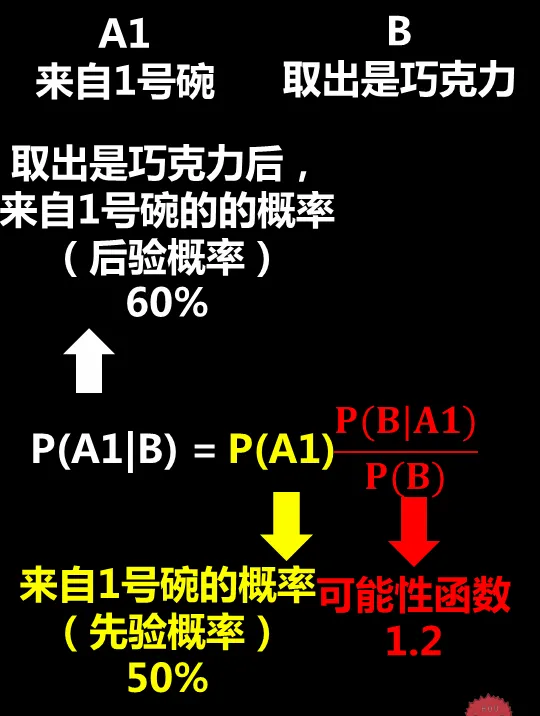
這個例子中我們需要關註的是約束條件:抓出的是巧克力。如果沒有這個約束條件在,來自一號碗這件事的機率就是50%了,因為巧克力的分布不均把機率從50%提升到60%。
現在,我總結下剛才的貝葉斯定理套用的套路,你就更清楚了,會發現像小學生做套用題一樣簡單:
第1步. 分解問題
簡單來說就像做套用題的感覺,先列出解決這個問題所需要的一些條件,然後記清楚哪些是已知的,哪些是未知的。
1)要求解的問題是什麽?
辨識出哪個是貝葉斯中的事件A(一般是想要知道的問題),哪個是事件B(一般是新的資訊,或者實驗結果)
2)已知條件是什麽?
第2步.套用貝葉斯定理
第3步,求貝葉斯公式中的2個指標
1)求先驗機率
2)求可能性函式
3)帶入貝葉斯公式求後驗機率

案例2:貝葉斯定理在醫療行業的套用
每一個醫學檢測,都存在假陽性率和假陰性率。假陽性,就是沒病,但是檢測結果顯示有病。假陰性正好相反,有病但是檢測結果正常。
即使檢測準確率是99%,如果醫生完全依賴檢測結果,也會誤診。也就是說假陽性的情況,根據檢測結果顯示有病,但是你實際並沒有得病。
舉個更具體的例子,因為愛滋病潛伏期很長,所以即便感染了也可能在很長的一段時間,身體沒有任何感覺,所以愛滋病檢測的假陽性會導致被測人非常大的心理壓力。
你可能會覺得,檢測準確率都99%了,誤測幾乎可以忽略不計了吧?所以你覺得這人肯定沒有患愛滋病了對不對?
讓我們用貝葉斯定理算一下,就會發現你的直覺是錯誤的。
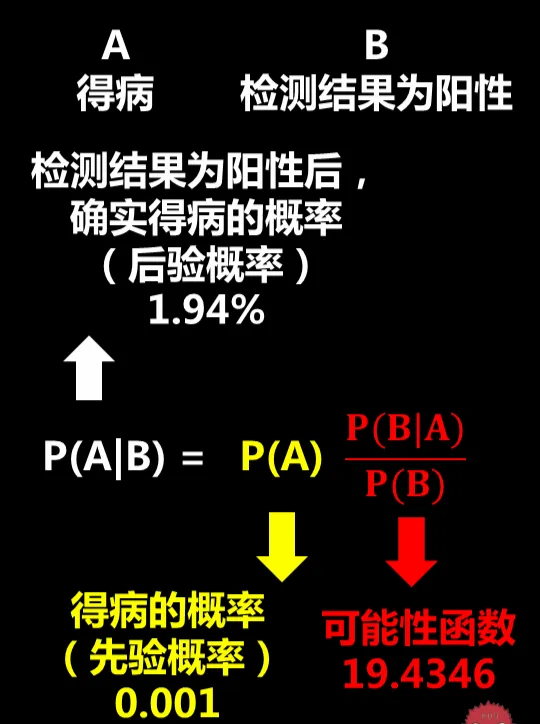
假設某種疾病的發病率是0.001,即1000人中會有1個人得病。現在有一種試劑可以檢驗患者是否得病,它的準確率是0.99,即在患者確實得病的情況下,它有99%的可能呈現陽性。它的誤報率是5%,即在患者沒有得病的情況下,它有5%的可能呈現陽性。
現在有一個病人的檢驗結果為陽性,請問他確實得病的可能性有多大?
好了,我知道你面對這一大推資訊又頭大了,我也是。但是我們不是有貝葉斯樣版套路嘛,下面開始。
第1步,分解問題
1)要求解的問題:病人的檢驗結果為陽性,他確實得病的機率有多大?
病人的檢驗結果為陽性(新的資訊)記為事件B,他得病記為事件A,
那麽要求的問題就是P(A|B),也就是病人的檢驗結果為陽性(B),他確實得病的機率(A)
2)已知資訊
這種疾病的發病率是0.001,即P(A)=0.001
試劑可以檢驗患者是否得病,準確率是0.99,也就是在患者確實得病的情況下(A),它有99%的可能呈現陽性(B),所以P(B|A)=0.99
試劑的誤報率是5%,即在患者沒有得病的情況下,它有5%的可能呈現陽性。得病我們記為事件A,那麽沒有得病就是事件A的反面,記為A',所以這句話就可以表示為P(B|A')=5%
2.套用貝葉斯定理

1)求先驗機率
疾病的發病率是0.001,即P(A)=0.001
2)求可能性函式
P(B|A)/P(B)
其中,P(B|A)表示在患者確實得病的情況下(A),試劑呈現陽性的機率,從前面的已知條件中我們已經知道P(B|A)=0.99
現在只有求出P(B)就可以得到答案。根據全機率公式,可以用下圖求得P(B)=0.05094

所以可能性函式P(B|A)/P(B)=0.99/0.05094=19.4346
3)帶入貝葉斯公式求後驗機率
我們得到了一個驚人的結果,P(A|B)等於1.94%。
也就是說,篩查的準確率都到了99%了,透過體檢結果有病(陽性)確實得病的機率也只有1.94%
你可能會說,再也不相信那些吹的天花亂墜的技術了,說好了篩查準確率那麽高,結果篩查的結果對於確診疾病一點用都沒有,這還要醫學技術幹什麽?
沒錯,這就是貝葉斯分析告訴我們的。我們拿愛滋病來說,由於發愛滋病實在是小機率事件,所以當我們對一大群人做愛滋病篩查時,雖說準確率有99%,但仍然會有相當一部份人因為誤測而被診斷為愛滋病,這一部份人在人群中的數目甚至比真正愛滋病患者的數目還要高。
你肯定要問了,那該怎樣糾正測量帶來這麽高的誤診呢?
造成這麽不靠譜的誤診的原因,是無差別地給一大群人做篩查,而不論測量準確率有多高,因為正常人的數目遠大於實際的患者,所以誤測造成的幹擾就非常大了。
根據貝葉斯定理,我們知道提高先驗機率,可以有效的提高後驗機率。
所以解決的辦法倒也很簡單,就是先釘選可疑的人群,比如10000人中檢查出現問題的那10個人,再獨立重復檢測一次。因為正常人連續兩次體檢都出現誤測的機率極低,這時篩選出真正患者的準確率就很高了,這也是為什麽許多疾病的檢測,往往還要送交獨立機構多次檢查的原因。
這也是為什麽愛滋病檢測第一次呈陽性的人,還需要做第二次檢測,第二次依然是陽性的還需要送交國家實驗室做第三次檢測。
在【醫學的真相】這本書裏舉了個例子,假設檢測愛滋病毒,對於每一個呈陽性的檢測結果,只有50%的機率能證明這位患者確實感染了病毒。但是如果醫生具備先驗知識,先篩選出一些高風險的病人,然後再讓這些病人進行愛滋病檢查,檢查的準確率就能提升到95%。
案例4:貝葉斯垃圾信件過濾器
垃圾信件是一種令人頭痛的問題,困擾著所有的互聯網使用者。全球垃圾信件的高峰出現在2006年,那時候所有信件中90%都是垃圾,2015年6月份全球垃圾信件的比例數位首次降低到50%以下。
最初的垃圾信件過濾是靠靜態關鍵詞加一些判斷條件來過濾,效果不好,漏網之魚多,冤枉的也不少。
2002年,Paul Graham提出使用"貝葉斯推斷"過濾垃圾信件。他說,這樣做的效果,好得不可思議。1000封垃圾信件可以過濾掉995封,且沒有一個誤判。
因為典型的垃圾信件詞匯在垃圾信件中會以更高的頻率出現,所以在做貝葉斯公式計算時,肯定會被辨識出來。之後用最高頻的15個垃圾詞匯做聯合機率計算,聯合機率的結果超過90%將說明它是垃圾信件。
用貝葉斯過濾器可以辨識很多覆寫過的垃圾信件,而且錯判率非常低。甚至不要求對初始值有多麽精確,精度會在隨後計算中逐漸逼近真實情況。
(ps:如果留言想詳細了解這個知識的很多,我後面會專門寫文章來回答大家)
4.生活中的貝葉斯思維貝葉斯定理與人腦的工作機制很像,這也是為什麽它能成為機器學習的基礎。
如果你仔細觀察小孩學習新東西的這個能力,會發現,很多東西根本就是看一遍就會。比如我3歲的外甥,看了我做伏地挺身的動作,也做了一次這個動作,雖然動作不標準,但也是有模有樣。
同樣的,我告訴他一個新單詞,他一開始並不知道這個詞是什麽意思,但是他可以根據當時的情景,先來個猜測(先驗機率/主觀判斷)。一有機會,他就會在不同的場合說出這個詞,然後觀察你的反應。如果我告訴他用對了,他就會進一步記住這個詞的意思,如果我告訴他用錯了,他就會進行相應調整。(可能性函式/調整因子)。經過這樣反復的猜測、試探、調整主觀判斷,就是貝葉斯定理思維的過程。
同樣的,我們成人也在用貝葉斯思維來做出決策。比如,你和女神在聊天的時候,如果對方說出「雖然」兩個字,你大概就會猜測,對方後面九成的可能性會說出「但是」。我們的大腦看起來就好像是天生在用貝葉斯定理,即根據生活的經歷有了主觀判斷(先驗機率),然後根據搜集新的資訊來修正(可能性函),最後做出高機率的預測(後驗機率)。
其實這個過程,就是下圖的大腦決策過程:

所以,在生活中涉及到預測的事情,用貝葉斯的思維可以提高預測的機率。你可以分3個步驟來預測:
1.分解問題
簡單來說就像小學生做套用題的感覺,先列出要解決的問題是什麽?已知條件有哪些?
2. 給出主觀判斷
不是瞎猜,而是根據自己的經歷和學識來給出一個主觀判斷。
3.搜集新的資訊,最佳化主觀判斷
持續關於你要解決問題相關資訊的最新動態,然後用獲取到的新資訊來不斷調整第2步的主觀判斷。如果新資訊符合這個主觀判斷,你就提高主觀判斷的可信度,如果不符合,你就降低主觀判斷的可信度。
比如我們剛開始看到「人工智慧是否造成人類失業」這個資訊,你有自己的理解(主觀判斷),但是當你學習了一些數據分析,或者看了些這方面的最新研究進展(新的資訊),然後你根據掌握的最新資訊最佳化了自己之前的理解(調整因子),最後重新理解了「人工智慧」這個資訊(後驗機率)。這也就是胡適說的「大膽假設,小心求證」。
機率的基礎知識補充:
參考資料:
YouTube英文視訊【Thomas Bayes: Probability for Success】
YouTube英文視訊【Everything You Ever Wanted to Know About Bayes' Theorem But Were Afraid To Ask.】
貝葉斯垃圾信件過濾器: http://www. paulgraham.com/spam.htm l
貝葉斯垃圾信件過濾Wiki: https:// en.wikipedia.org/wiki/N aive_Bayes_spam_filtering
貝葉斯推斷及其互聯網套用(一)
【聯邦黨人文集】背後的統計學幽靈











