1. 什么是AB实验?
在同一时间维度,让相似的群体体验不同的实验(策略或功能),基于实际业务数据的分析结果辅助决策
2. AB实验的流程是什么?
1)确定实验评估指标
2)流量分配:实验的分层分流方案
3)确定实验有效天数:实验的有效天数即为实验进行多少天能达到流量的 最小 样本量。
4)策略上线(灰度上线)
5)实验效果分析
3. AB实验涉及的分析方法有哪些?
3.1 分层分流方法
不同实验间的数据,应该尽量正交
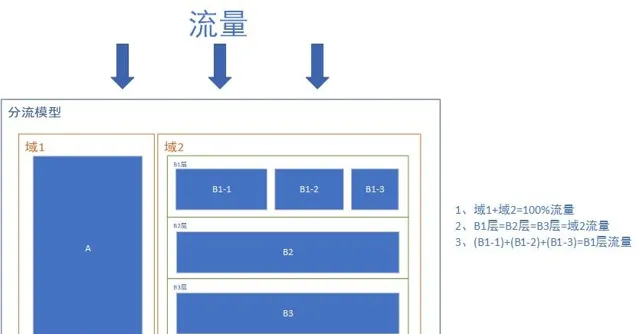
X1实验中存在2000个X2实验的样本,那么这2000个样本的分布与在X2实验中样本分布是一致的
3.2 假设检验
用于判断实验的差异
假设检验只能表明,实验组比对照组提升的概率,但不能表明提升的程度
举例:实验组比对照组点击率平均高30%、置信度水平为95%,说明实验组比对照组提升的概率大于95%,不能说明实验组比对照组提升30%的概率大于95%
检验过程如下:
(1)判断两组样本的正态性:KS检验
满足正态性则进行步骤(2),否则使用非参数检验(Wilcox检验)
(2)判断两组样本的方差是否已知
如果已知则使用Z检验(方差已知检验均值),否则进行步骤(3)
(3)判断两组样本的方差是否相等(方差齐性检验-F检验)
如果相等则使用T检验(方差相等的均值检验),否则样本数据做变换(X/var(x)、Y/var(y)),再做方差调和后的T检验(welch T test)
最小样本量:
统计功效在80%时,每组样本量>1000
R语言:Power.t.test(power=0.8, delta=, sig-level =0.05)
4. AB实验重点注意的问题
4.1 分流问题
AB两组均匀分流:体现为AA实验无差异
小样本量:一般>1000
4.2 缺乏对照组
不建议:选择90%的作为实验组、剩余10%直接作为对照组(实验组与对照组不在同一「实验层」)
未上AB实验的对照组,可能被其他策略污染
4.3 延滞效应
前一个策略实验结束后,可能会对下一个策略有滞后的营销,因此建议在下一个策略时重新分流
4.4 多重检验问题
AB实验应该尽量减少核心观察指标的数量
原因:观察一个指标置信度95%,同时观察两个指标置信度则降为95%*95%=90.25%,同时观察10个指标置信度为0.95^10=60%,几乎与随机猜测无差异。
如果要同时观测多个指标,则要提升每个指标的置信度,提升方法采用Bonferroni校正(即在同一个数据集上,同时检验n个独立假设,那么用于检验每个假设的统计学显著水平应为仅检验一个假设时显著水平的1/n)
举例:当同时观察10个指标,又希望实验的置信度在95%,应该保持每个指标的置信度水平为(1-0.05/10)=99.5%
4.5 人群不同时
不同时刻人群已发生改变,实验中不要改动流量或策略条件,或临时增加实验组,即实验中啥也不要动
4.6 震荡效应
用户在感受到策略变化的前2-3天内一般处于新鲜感,部分用户会积极探索策略变化,而后续热情逐渐退去,直至收敛。因此,一般选择用户行为收敛的2-3天作为结束实验的时机。
4.7 时间波谷效应
不同时间窗口的实验,只能进行定性比较,不能进行定量比较
原因:不同时间窗口,实验的人群和行为均已经发生变化,不再具备定量比较的意义
4.8 时间窗口效应
短期实验效果,不见得长期持续(由于震荡效应也可知道),重点验证实验当时的假设是否成立
如果要评估多个策略的综合实验效果,建议设置长期对照组进行评估
4.9 辛普森悖论
体现为「AB实验vs全量上线」后的效果反转
4.10 网络效应
体现为「实验组vs对照组」的样本不独立,存在用户局部内相互营销
1)实验组带动对照组:实际收益>评估值
举例:比如一些用户得知其他用户某项功能上存在差异,也想要点开试试,这样就造成了实验组带动对照组的点击率上涨,使得实验组与对照组在数据上的差距变小,即评估值变小
2)实验组与对照组有资源竞争:实际收益<评估值
举例:在某种资源一定的前提下,为实验组增加资源,则会导致对照组的资源减少,使得实验组与对照组在数据上的差异变大,即评估值变大
以上重点参考:【策略产品经历实践】
人生漫漫,书生海海,我读你看。
微信号-book2h、微信名-书生海海










