写这个主要是为了完成作业,领导转发了夏core的文章,其中,特别对 第四招:GPGPU相比DSA对AI天生不足 ,领导们想知道里面说的有没有道理,以及针对这些观点,我们的看法是什么。于是,周末展开写了一些自己的观点。
附原文:
时间有限,只接第四招!
GPGPU是AI最高效的计算硬件架构吗?
「很明显的答案,不是。」
我也赞同!
虽然答案相同,但理由不同:GPGPU只是一个名词,代表通用计算为目的芯片,不是固定的架构。不同家的GPGPU,虽然都是叫GPGPU,其实架构差别很大的;而Nvidia十几年前的GPGPU和现在的Hopper架构,差别也是非常大。
既然GPGPU不是特指一个固定的硬件架构,那讨论它是不是AI最高效的计算硬件架构,是没有意义的。它适合在CPU/GPU这个更高维度来做区分对比。
相关专业从业者,要做AI架构比较的时候,最好直接拿两个架构对比,比如NV Hopper vs. Google TPU v4;NV Grace-Hopper vs. Tenstorrent Grendel。
PK完了之后,看看谁胜出。谁就当下AI最高效的计算( 硬件 )架构。(最好去掉硬件,单独讨论硬件好像没什么意义。)
GPGPU相比DSA对AI天生不足吗?
芯片架构都是「人」生的,没有「天」生的!
「不」足是可以「补」足的!
在Graphcis+AI芯片行业工作马上二十年了。我经历过几次非常大的硬件架构升级,软件架构重构,推翻重写。每次都是以年为时间单位的大项目。升级/重构是非常辛苦的事,但这些都是为了活提供更好的特性,或解决客户的痛点,不做公司就得死。
不得不承认,Nvidia在变革这一方面,经常是引领者!所以我并不怀疑他们对自己不足点的感知能力,以及他们的纠错补足能力。不论在AI计算的 最前沿 :大学,研究机构的算法研究中;还是在工业界 最广泛 的各个领域的AI计算实际应用中,都有大批的NV工程师,架构师去对接,获取第一手的反馈。最终将合适的架构改动反映在芯片架构中。
比如,我们只看到Hopper在Transformer引擎加持下跑大模型性能爆表,仔细反推一下,Nvidia的架构师们在2019/2020年就已经感知Transformer算法在未来AI计算的重要性,然后做架构方案,实现在Hopper架构中,而当大模型大火之时,一个几倍性能/能效的Hopper架构真的是让对手们难以招架。
架构服务于需求!有需求就改架构!
从GPU到GPGPU,是从Graphics到通用计算的的一个(DSA -> General)的过程。
现在AI有超大需求,反过来,再从GPGPU演进到一个GP-AI-PU,甚至AI-PU,也没什么不可以的。
Nvidia通过在SIMT架构的紧耦合扩展, SIMT本身的架构会约束限制了其AI DSA的上限?
大家对SIMT技术有些误解。
SIMT,就其字面含义,Single Instruction Multiple Threads,只是GPGPU在微架构层次(Warp/Thread)上的一个技术架构,因为涉及到指令集和编程模型,给用户带了很多便捷,所以名声比较大。但把它和GPGPU架构放在一个级别,甚至画上等号,这是一个概念上的错误。
它真的只是整个架构里非常非常小的一个技术,局限在SM核内很小的一部分管理warp内线程的微架构,对AI计算的Pattern(模式)来说,它的重要性比较低。因为AI算子中,需要精细branch控制的部分很少。
对于大型AI计算,NV的架构中,是采取多层次(Hierarchy),分而治之的策略。它在每一个层次上,都有很多相关的技术。下面,1-5是单芯片内的层次,6-8是多芯片scale-out:
- Thread:对一个warp内的threads(x32)进行管理,SIMT,Predicate,EMask,...
- Warp:对一个PU内的多个warp(x8/16)进行管理,Warp Scheduler,Multi-issue,...
- Block:一个SM内有多个PU(x4),它们之间需要block级别的管理,任务的颗粒
- Cluster:一个Cluster内多个SM(x16)协作管理,合作完成一些需要较大SRAM(MB大小Shared Memory)的任务,
- Grid/Device:100多个SM的管理,
- Grace-Hopper:CPU-GPGPU之间NVLink-C2C,插一句,NVlink C2C兼容CXL。
- NVLink:节点内多GPU连接,
- NVLink-Switch:多节点连接
有机会对多层次(Hierarchy)计算架构,和其它扁平式(层次较少)的DSA架构做一些对比分析。一个合适的架构层次对计算的控制流,数据流,软件的复杂度等关键指标影响很大,值得详细分析。
DSA on Hopper
抛开Transformer引擎,Hopper架构在Block/Cluster这两个层次,增加了不少新特性,基于这些新特性,打造了一个脱离SIMT(threads)的编程模型和指令集,能完成一套完全等于普通DSA的Buffer+DMA结构的编程和计算控制。在整个conv/matmul的编程中,甚至不需要任何的vector/SIMT相关的指令。
夏Core举例说的SIMT/Tensor core,其实还停留在老的架构的理解上,这里可以对Hopper几个特性做一些简单介绍,其实NV对AI的DSA化支持力度其实很大了。

简单的说,Hopper架构的DSA改进,和SIMT没关系,也不会受到SIMT的限制。
相关DSA特性包括
其中,TMA支持img2col,multicast,shared memory swizzle等;
Async warpgroup-level MMA:包括大size(64×32B×256)的MMA,直接读写shared memory,SM内所有Tensor core协同工作机制。算力也和壁仞的一个CU(4个Tcore/PU)的差不多。这里有一些介绍,大家可以看一看:
而后面两个特性(DSMEM+Async barrier),更是能将Cluster里多个SM协同完成更大的conv/matmul,减少外部带宽需求。当然合作方式并不是壁仞的脉动方式,而是各自独立,但支持DSMEM访问,数据广播,优点是更灵活,算力更大!缺点是复杂度比较高。
基本上, 上面特性完全解决了原文中提到的数据通路和Tensor Core尺寸的问题。
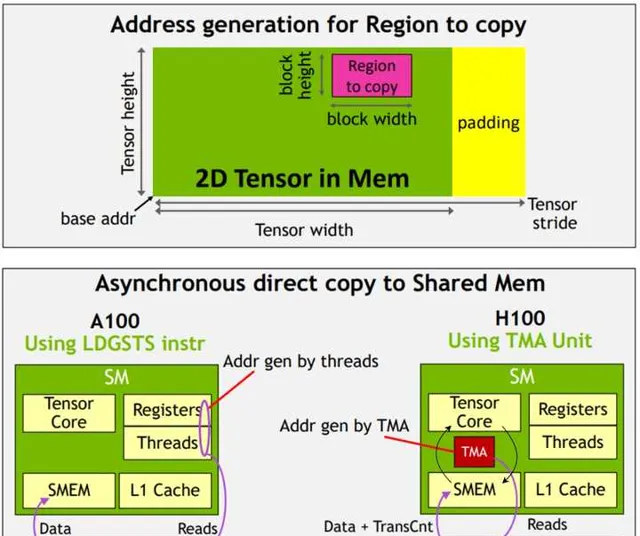
而且,不考虑量化等Fused操作的话,整个Conv/Matmul类型的算子里,你都看不到任何thread概念的代码/指令,完全就是基于tile的Tensor+DSA编程模式。
其它
以后有机会,再探讨探讨其它几个话题:虚拟化,CPU-GPU融合,统一内存架构和编程模型等。
不可否认传统的GPU/GPGPU都有其历史包袱。但并没有阻止大家努力地把架构往新的方向推动。比如十几年,AMD(前司)的Phil Rogers就在大力推行HSA,另一个前司(ARM),当时Jem Davies也是大力辅助。可惜还是没有成功。现在ARM在Mobile上推了几年的Total Computing。总之,新技术的推广落地确实很难。很多技术都是好技术,技术的支持确参杂太多利益,这是一些公司/组织推动技术和规范时总遇到的问题。回过头来看,NV在这一块其实做得还挺成功。
交作业。夏core刀下留情!







