首先和很多人的直观感觉相反, 如今 PC DDR5 不是 64bit 单通道位宽, M1 系列也不是 128bit 位宽.
包括 DDR5 的 UDIMM 就从 64bit 单通道变成了 32bit 双通道.
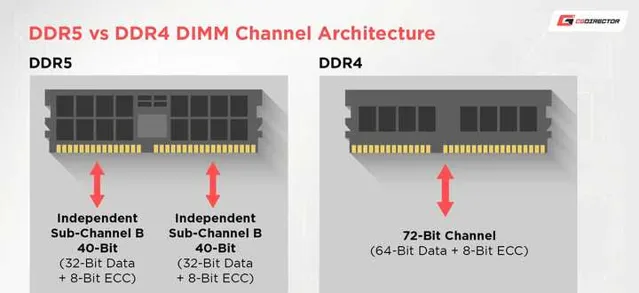
细心的朋友可以发现, 上面图里放的其实是边带 ECC DIMM.
而因为 DDR5 拆成两条通道, 因此每个通道的 ECC bit 都要独立开来, 而每个通道为了实现 ECC 加一颗 chip等于加 8bit.
因此 DDR5 ECC 的物理位宽是 de facto 更宽的.
但这样做除了实现双通道, 并不会带来更好的 ECC 效果(仍然是1bit纠错/2bit报告), 内存和 PHY 成本上升是扎扎实实的.
所以部分服务器 DDR5 内存还是 72bit, 这样少一颗颗粒, 大规模的场景下的降本可以想象有多少.

至于手机平台的话, 一个 LPDDR4/5 的 chip 实际上有两个 16bit 通道, 因此能组成不同的组合. 不同的组合需要的引脚、性能、功耗都有所不同.
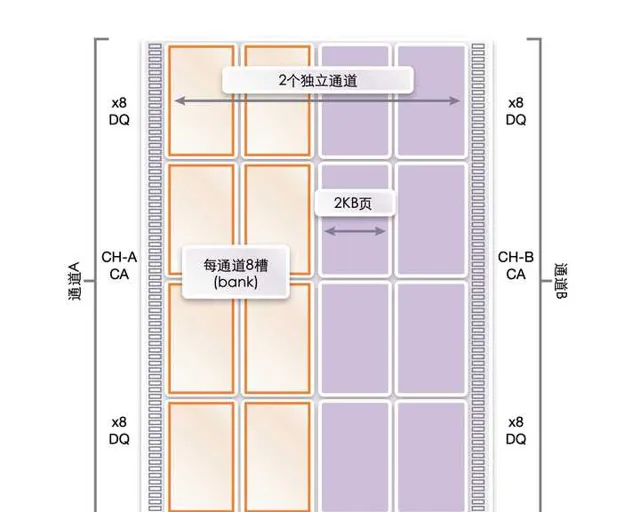
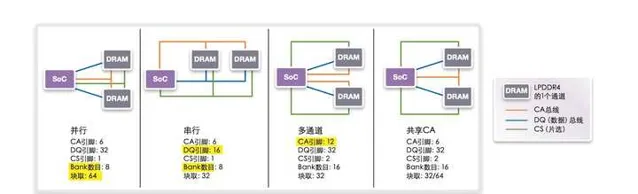
特别是移动平台有待机休眠的需求, 移动 SoC 上的内存布局通常都是不对称多通道, 某一个通道会专门放待机会访问的内容(意味着这部分的带宽其实是很低的), 其他部分休眠的时候就可以进入自刷新.
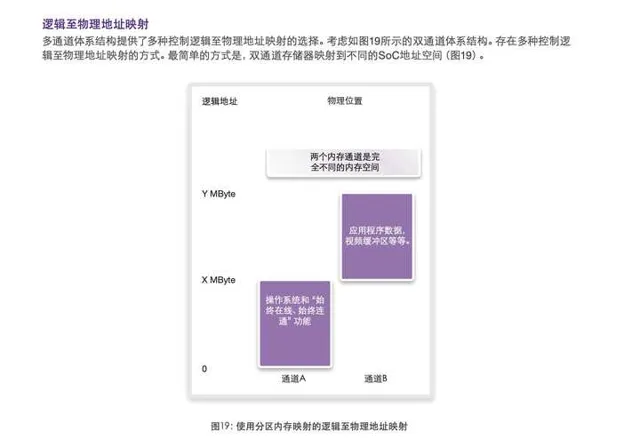
回到 PC 这边的话, 回答为什么不做更宽.
那很显然, 如果芯片要做更宽的内存, 就意味着更大的内存控制器, which 吃面积.
同时需要更多的内存颗粒去满足这些位宽, 对主板布局有挑战, 同时需要更厚的板层数量、更高质量的工艺实现更好的信号完整性.
那就很容易碰到一个矛盾:
高位宽需要更多芯片和更高信号完整性, 更高信号完整性意味着内存越靠近芯片, 而芯片边上一圈的空间是有限的, 那意味着牺牲容量.
以及, 更贵.
以及CPU通常延迟的重要性大于带宽, 除非核心足够多.
更不用说又不是人均 7950X 会碰到带宽瓶颈, 用 R5/i5 的一堆, 而现在的 i5 本质上是 8+16 的 die 切出来的, 不可能为此继续增加通道/改变主板.
因此超过128bit位宽的 CPU 只有在 HEDT(如Threadripper, 以前的 X 系主板+Extreme) 平台才能见到, 其实就是服务器下放.
那有的人说, 笔记本上核显卡需要带宽, 为什么 x86 平台还是 128bit 封顶.
这就要提到刚才说的, 内存控制器+PHY 要吃面积.
而通常 128bit 的移动 SoC 还要兼任嵌入式 SoC, 要上 ECC 内存, 然后起码得同时兼容 DDR5/LPDDR5(以前是兼容 DDR4/LPDDR4X, Intel 得兼容 LPDDR5/DDR4/DDR5).
仔细看的话可以发现 AMD SoC PHY 部分有些类似 IOD 上的 2x72bit 设计, 但实际再放大看, 似乎 LPDDR4/DDR4 的 PHY 分开的, DDR4 部分是 (4+5)x16bit, 而 LPDDR4 是 8*16bit)
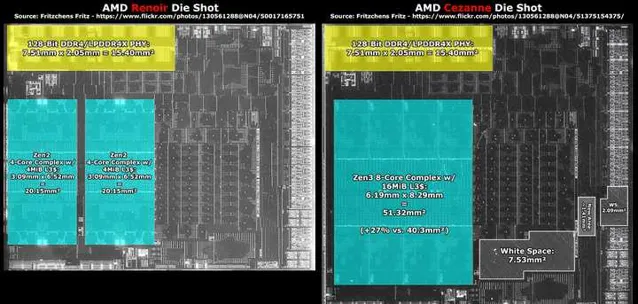
对于笔记本的产品经理来说, 不同的产品线可能会用不同的内存, 因此 SoC 就有必要同时兼容多种内存(虽然不同内存类型的 SoC 会用不同的封装, 比如 fp7 和 fp7r2, 以及主板设计不兼容)
当然这么做的代价, 就是单位面积的能做的带宽会更低.
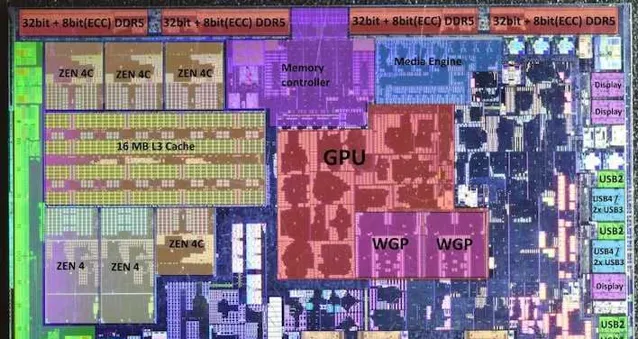
因此如果要降低成本的话, 就不能盲目支持很多种类的内存, 这就是为什么 AM5 平台只支持 DDR5, 而 AMD 给 Chromebook 上网本用的 Mendocino 只支持 2x32bit LPDDR5, 就是为了省钱(当然 LPDDR5 因为手机的出货量, 496ball Mobile LPDDR5 模组其实挺便宜的, 有不少山寨笔记本用了手机内存上 12-24GB, 甚至是让 LPDDR5X 降级运行在 LPDDR5 上)

包括大家熟知的 Steam Deck 的 SoC 应该也只支持 LPDDR5, 新款用了和 M2 类似的 64bit 颗粒. 而且可以注意到尺寸显著缩小.

另外一个问题就是电气完整性.
就如下图的统计, 7nm 的 CZE 内存控制器的密度仅为 3.7bit/mm2, 而 M1 只支持 LPDDR4X 的情况下为 7.8. 虽然说 M1 是 5nm 工艺不是很公平, 但是可以看 Rembarndt 的 6nm 上了 DDR5/LPDDR5 之后, 内存控制器的面积效率相比 CZE 进一步倒车, 密度远远落后于 M2.
同样, M2 相比 M1 的内存控制器面积效率也是倒车的, 因为 LPDDR5 的内存控制器更复杂. A15-A16 也体现了这种变化.
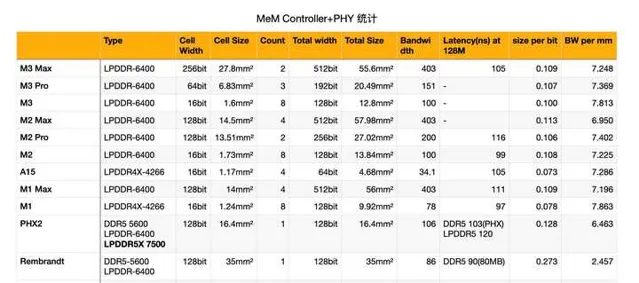
之所以 AMD 这边内存控制器密度这么低, 除了刚才提到的兼容的种类多(特别是 ECC 需要多加 DQ), 工艺老(当然先进工艺对 PHY/SRAM 密度帮助不是很大, 这就是为什么 RDNA3 用特殊的 6nm 做了 MCD), 更重要的原因是:
为了实现更高的电气完整性, PHY 的驱动能力有了很大加强.
这就是为什么 RMB 能实现 10 层板上 6400 内存, 而 Intel 这边 12 代只能通过 HDI 上 6000 频率, 但代价就是内存 PHY 面积. 但 RMB 的内存控制器密度低的感人, 只有苹果主流水平的 1/3.
PHX 上倒是上了 AMD 自研的 IP, 可以发现每平方毫米位宽做到了 6.5, 算是比较可以了.
但是就这个水平的话, 做 128bit 可能还好, 但要堆到 256bit 的话, 那在 4nm 下 PHY 的内存控制器面积就要高达 33mm2.
因此 256bit 位宽 Strix Halo 将确定只支持 LPDDR5/5X 内存.
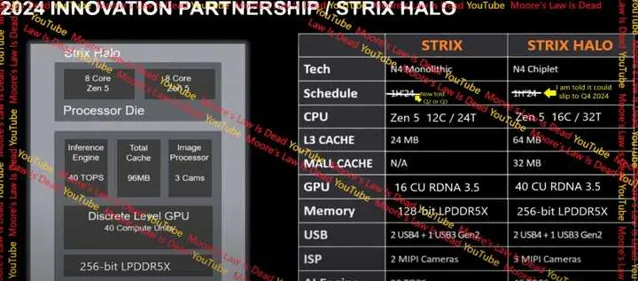
包括 AGX Orin 也做了 64GB/256bit 位宽, 盛惠 2000 刀. 让老黄教育下在座什么叫黄金内存.
所以, MSDT/LP PC 做超过 128bit 只是时间问题, 且服务的还是 GPU.
接着再回到这张图
可以发现, 苹果单位面积实现的位宽一直是领先的. 这是一定程度上是因为 MoP 封装带来了更好的电气完整性, 降低了驱动力的要求.
在同代之间, Max 的内存控制器的密度都是相对偏低的.
而 M2 Pro 的内存控制器密度反倒是反超了 M2, 毕竟同样的 64bit 颗粒, 却只需要 32GB 封顶, 而 M2 需要支持 24GB 的版本.

这种变化应该还是内存PHY驱动力导致的. 因为 Max/Ultra 要支持更大的内存, 比如 M3 Max 上史无前例的 128bit 宽单颗粒 32GB, 应该是 A17 Pro 的同款 16gb DUV D1beta die. 要知道这个 package 里面有 16 片 chip(2x8层), 相对需要高一些的驱动力.
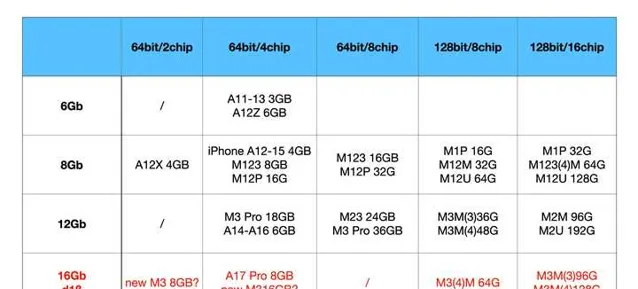
另外一件大家知道的事情就是, M3 Pro 位宽从 256 缩水 192.
当然我不指望那些一天到晚口嗨的喷子有买 M3 Pro MBP 的念头.
但从技术工程的角度看, M3 Pro 缩带宽本质上是 M3 Pro 芯片独立设计的结果, 使得芯片的面积相较 M2 Pro 大幅度下降, 只不过性能提升幅度不大, 但换来的是更好的能效, 以及小得多的封装.
所以就有传闻说 M3 Pro 会登陆 14 寸 iPad Pro. 我个人觉得上 15 寸 MacBook Air 也只是时间问题, 毕竟功耗低了, 但会不会上风扇就不好说.











