谢邀。先说结论,多核CPU和多CPU的区别主要在于性能和成本。多核CPU性能最好,但成本最高;多CPU成本小,便宜,但性能相对较差。我们来看一个例子:如果我们需要组成一个48核的计算机,我们可以有这么三种选择:
- 把48个核全部做到一个大Die上,Die很大。这个Die加上一些外围电路组成一个单Die多核CPU。
- 弄4个小Die,每个Die 12个内核,每个Die很小。把这4个Die,加上互联总线和外围电路,全部封装(Packaging)到 一个 多Die多核CPU中。
- 还是弄4个Die,每个Die 12个内核,每个Die很小。每个Die加上外围电路封装成一个单独的CPU,4个CPU再通过总线组成一个多路(way/socket)系统。
我们来看看他们的性能差距和成本差距。
性能差距
为了很好的理解三者之间的区别,我们通过一个生活中的场景分别指代三种方式。 我们想像每个Die是一栋大楼,Die里面的内核们,内存控制器们、PCIe控制器们和其他功能模块是其中的一个个房间。数据流和指令流在它们之间的流动看作房间里面的人们互相串门,这种串门的方便程度和走廊宽度决定了人们愿不愿意和多少人可以同时串门,也就指代了数据的延迟和带宽 。
好了,有了这种方便的比喻,我们来看看三种情况分别是什么。
48核的大Die是Intel至强系列的标准做法:

这种方法就是既然需要这么多房间,业主有钱,就建一个大楼,每层都是 超级大平层 :
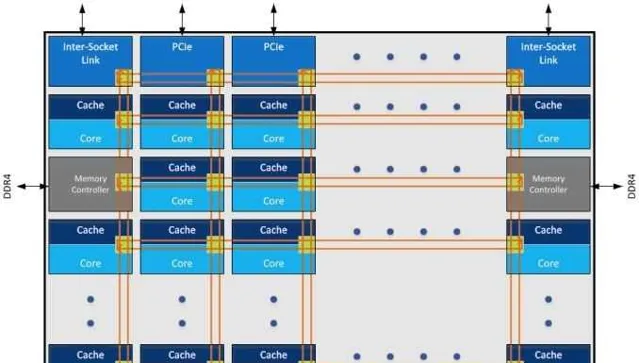
走廊众多,这里堵了,换个路过去,反正方向对了就行,总能到的。所以人们可以很方便的串门,也可以有很多人同时串门。所以延迟小,带宽高。
一个CPU pacakge里面包了4个小Die的做法是AMD的标准做法,也有部分Intel也这样:

这种做法可以看作业主没钱搞大平层,但也要这么多房间,怎么办呢?在原地 相邻得建4个小高层 ,再把小高层连起来,房间数目不变。怎么把它们连起来呢?比较现代的做法有两种:
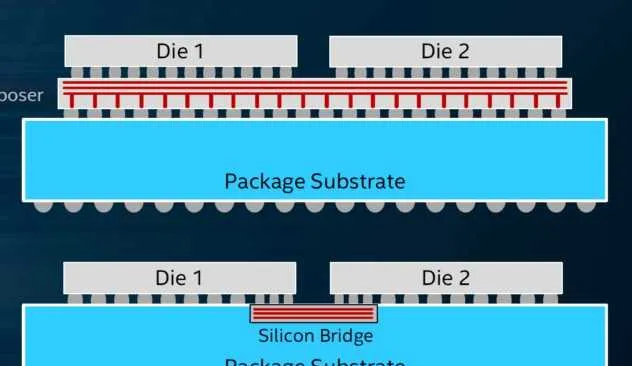
这种做法也叫做MCM(Multi-Chip-Module),详细内容可以看我的这篇文章:
其中AMD采用硅中介(Interposer),也就是上面那种;Intel采用 EMIB(Embedded Multi-die Interconnect Bridge), 是下面那种。
硅中介的做法可以看作为了两个楼互通,我们把地下都挖空了,搞了个换乘大厅。而EMIB可以看成在两个楼之间挖了一个地下通道。显然挖通道更省钱省力,但因为通道是两两互联的,如果大楼多了,还不如换乘大厅方便。
好了,那我们的串门问题怎么解决呢?因为楼和楼(Die和Die)之间只有地下互通,要串门的人都要做电梯到地下一层,通过地道或者换乘大厅到另一个大楼地下,再做电梯去想要的楼层。路途遥远,好多人都不想串门了,同时如果串门人太多,会挤爆电梯,不得不串门联系工作的人们在电梯口排起了长队。显然,建筑四个相邻小高层的办法,延迟和带宽都比较差。
那么多CPU呢?

还是没钱盖大平层,这次更惨,因为4层小高层间隔比较远,为了方便人们串门,不得不在园区里面搞了班车,用于跨楼通勤。因为班车开停需要时间,人们串门更加麻烦了。
借助这个比喻,我们应该能够得出结论,这三种方式提供48核的算力,延迟和带宽是依次下降的。下降的幅度和需要进行的work load有关,不能一概而论。大家可以借助一个工具 [1] 来具体测量一下内存的延迟:

在这个例子里面看出,本大楼的访问延迟比跨大楼的访问延迟低了一倍!
成本差距
既然大平层这么好,为什么还有人盖小高层呢?存在都是合理的,当然是成本高了。我在这篇文章中讲述了为什么Die大了成本就高:
简单来说,晶圆在制造过程中总是避免不了缺陷,这些缺陷就像撒芝麻粒,分布在整个Wafer上:

如果考虑缺陷,Die的大小会严重影响良率:
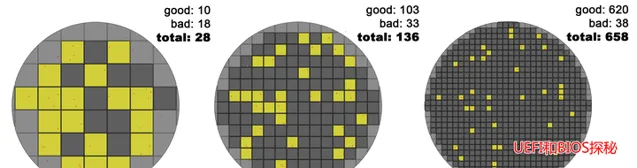
上图大家可以点开看(图比较大),其中不太清楚的红色小点是晶圆的缺陷,在Die很大时,有很大概率它的范围内会缺陷,而只要有缺陷该Die就报废了(简化处理);在Die比较小的时候,它含有缺陷的可能性就大大降低了。如图中,随着Die的减小,良率从第一个的35.7%提高到了95.2%!我们举个极端的例子,整个Wafer就一个Die,那么良率只有0%了,生产一个报废一个。谁还干这么傻的事!
这种成本增加不是线性的,而是指数性增加,具体的数字是厂商的核心机密,不为外人道。但总的来说,结合前面的例子来说就是:
1个大Die成本 > 4个小Die+互联线路总成本
那么方式2和方式3成本谁高呢?实际上方式2节约了主板上大量布线和VR等成本,总成本更低,也是主板和服务器厂商喜闻乐见的形式;而方式3往往用于堆出更多的内核和需要更多内存的情况。
结论
相信读到这里,同学们已经有了答案,结论开头已经说明,就不再赘述了。多核CPU和多Die乃至多路CPU,对操作系统等来看,区别不大,BIOS都报告了同样多的很多CPU供他们调度。区别主要在于性能上面,大Die多核性能最好,也最贵。多Die性能下降,但经济实惠。最后要注意,这些性能区别有些是操作系统可以感知的,如通过NUMA等方式:
操作系统可以具体做出优化。但也有部分是操作系统不能够知道的,只有通过各种真实的workload,用户那里才会感觉有明显的不同。
最后推荐11代内核的NUC,很好用
BIOS培训云课堂 :
其他CPU硬件文章:
欢迎大家关注我的专栏和用微信扫描下方二维码加入微信公众号"UEFIBlog",在那里有最新的文章。

参考
- ^ Intel Performance Checker https://software.intel.com/en-us/articles/intelr-memory-latency-checker











