我猜可能是tokenizer导致的
虽然ChatGPT是闭源,但OpenAI的Tokenizer是开源的(Github地址),也可以通过这个网址直接测试Tokenizer: https:// platform.openai.com/tok enizer ,我们对这个问题进行tokenize的话,结果如下
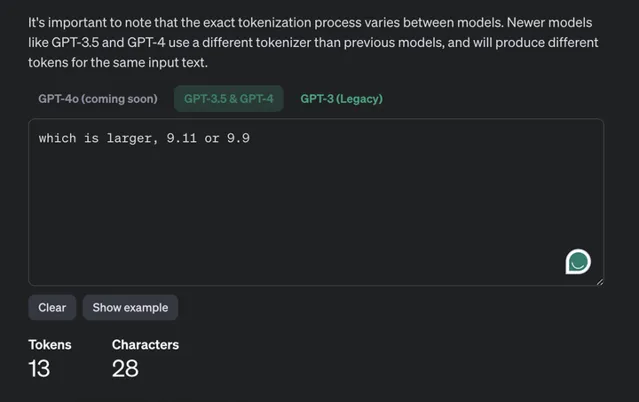
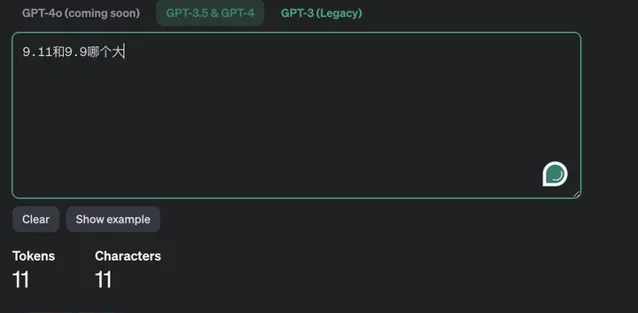
可以看到,9.11被拆成了3个token,结果就导致小数前面的9和9比,小数点后面的9和11比。
同样的,Anthropic Claude的Tokenizer也一样
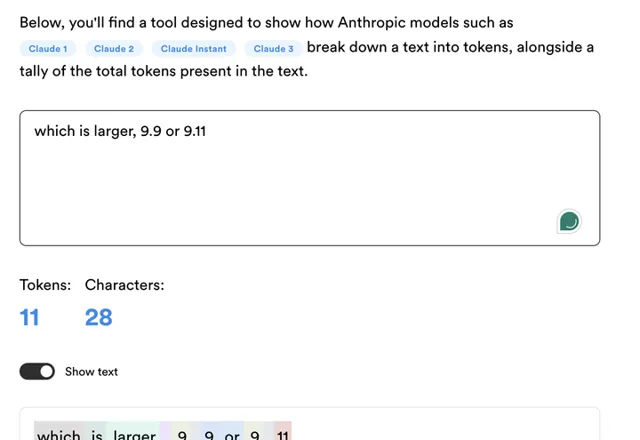
我一个小时前测试时,GPT4, 4o, Claude3.5 sonnet, kimi都翻车了,而通义千问,豆包,文心一言,glm4等大模型都做出了正确的回答,不知道是打了补丁,还是因为中文大模型的Tokenizer不一样?具体结果大家可以看我一小时前发的想法,图太多就不贴进来影响阅读了。
不过换个角度来说,当9.9和9.11代表软件版本号是,确实9.11更大。所以从这个角度来讲,也不











