作为RL研究从业者,我认为RL的潜力还远远未被开发。一个真正的AI Agent应该有应对真实世界方方面面各种挑战的能力,特别是得要有planning和reasoning的能力,而不只是有对于下一个语言token预测的能力。
现有RL能力的结合和落地
先说一下应用现有的RL理论和技术,在实际生活中能做到什么。我们最近其实一直着力于开发能够帮助AI从业人员在现有RL理论和技术下开发真正拥有在实际环境下有用的RL Agent,并且最近开源了Pearl,我的团队最新开发的开源RL AI Agent框架(首日上线就拿到了540星,目前已经近1400星,感觉大家对RL还是有热情的)。先上Github链接(其中有包括网站和ArXiv论文):
我们认为实际落地场景中有用的RL Agent,不能局限于只有最大化cumulative reward的能力,而需要覆盖以下的多个方向并且能够在同一个Agent中加入任意以下能力的子集:
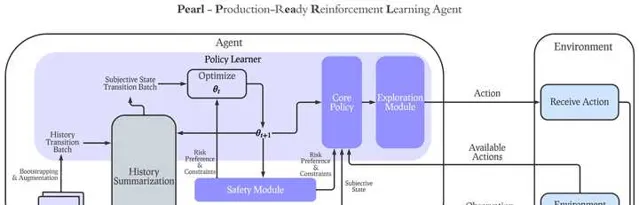
1. Dynamic Action Space (动态变化的行动空间):在真实环境中,大多数情况下每一步决策可采取的行动都是动态的,而不会在同一个问题中永远有一样的行动空间。比如,在推荐系统中,不可能在每一步给用户的可推荐内容集都是一样的。因此,在Pearl的设计中,我们着重支持了每一步的动态行动空间,并特殊设计了replay buffer,value-based算法和actor-critic算法来支持动态行动空间下的policy learning。
2. Offline RL transition to Online RL(线下强化学习向线上强化学习的转变):多数的现有算法只能顾及Offline和Online RL其中之一,而不能帮助Agent在完成Offline RL Pre-training之后做Online RL来和环境交互,从而真正学到optimal policy。Pearl的offline RL设计可以让我们的Agent在完成offline RL后用一个参数就完成到online RL到转变,从而帮助Agent从offline转至online。
3. Intelligent Exploration(智能探索):很多RL Agent设计的时候都用了最最常规的epsilon-greedy或者softmax的exploration,这种情况下,RL Agent并没有针对性地去收集他自身不确定性最高的state action的数据。这导致了很多线上收集的数据是浪费了的。在智能探索的能力下,Agent能够最大化在每一次线上交互收集到的数据中能学到的信息,从而提升sample-efficiency。在智能探索的能力下,我们设计了同时对neural contextual bandit和RL问题的支持。
4. Safe Decision Making (安全决策):安全一般分为两类,一类是限制,另一类是风险。限制性的安全决策指的是在Agent的决策全过程中,总的限制性指标不能超过某个阈值。一般情况下会用CMDP相关的理论方向来解决,在Pearl的设计中,我们引进了RCPO算法将其和任意actor-critic算法结合,便可以保证环境设定中的限制性指标不会超过阈值。而风险性指标指的是针对在一个policy之下可能收到的总的reward的分布,来限制Agent所需要接受的风险。比如,如果需要设计一个相对比较保守的Agent,那就会取总的reward的分布的相对比较低的percentile,而如果设计的是激进的Agent,就可以相反取比较高的percentile。我们将这种风险性的安全决策和分布强化学习结合(QRDQN),来满足相应的风险安全需求。
5. History Summarization for Partial Observability (针对部分可观测性的历史总结):大多数实际应用场景中,Agent的观测都是部分观测,而不能知道真正实际产品或者用户的真实状态。因此,能够从长时间的过往观测和Agent已经采取的行动中,估计真正的state,是对于RL实际应用至关重要的。我们在Pearl的设计中引进了sequence model来完成对过往历史的总结,并且用巧妙的工程技巧使得任意的history summarization可以和任意policy learning的算法结合,完成两个模块的同时学习。
最重要的一点是,在真实的应用场景中,我们希望以上的每一个Agent能力都是模块化的。也就是说,Agent的设计者可以在他们的场景中,结合以上的能力中的任意子集和常规policy learning的算法(比如value-based或者actor-critic)结合,来完成一个真正能够切合实际应用场景的RL-based AI Agent。
在我们的RL落地过程中,以上的RL能力以及他们的模块化结合对于最后的成功落地至关重要。
未来的RL展望
再讲讲对于未来的可能方向。
第一,我自己觉得将RL的planning能力和LLM还有diffusion model的结合,应该是下一个重要的突破口,问题在于action space的设计将会在什么程度上完成并且如何设计基于这些能力下的RL Agent的目标,会是一个很有意思的事情。
第二,multi-agent会是一个重头戏,因为当AI Agent慢慢变得普遍化之后,如何完成de-centralized agent training会是非常重要的一环。在之后的真实环境中,随机的环境变量可能不只是人类,可能还有agent本身带来的随机性。
第三,一个最近没有那么火的方向,但我还是觉得极其重要的,是Auxiliary Task。一般的真实环境中都会有超过一个目标需要完成,那planning就需要兼顾多个目标,这就是Auxiliary Task在RL中的作用。目前在学术界,这个方向还处于相对早期,有待更多研究的开发。
第四,Hierarchical RL可能是一个突破口。像我上文所说,在真实世界中,行动空间一般都是动态的,并且很多时候是完全没有重合的。比如一个机器人需要去帮你扫地和帮你做饭,这些事情可能没有任何的重合的行动空间,但是却需要统筹安排时间,比如在炖汤的时候去扫地,来完成效率最大化,这种问题都可以用到Hierarchical RL来解,但目前Hierarchical RL理论还没有那么成熟。
总结
RL还处于起步阶段。虽然很多人质疑RL的有效性,我还是会觉得RL是在我目前看来,带目的性的人工智能设计中最普适也最有可能成功的。最后附上一个看到的github上给Pearl的一个issue
希望Pearl能够帮助大家开发能够符合实际场景需求的RL Agent并且孵化出一个超越Q*的真正智能。











