我猜可能是tokenizer導致的
雖然ChatGPT是閉源,但OpenAI的Tokenizer是開源的(Github地址),也可以透過這個網址直接測試Tokenizer: https:// platform.openai.com/tok enizer ,我們對這個問題進行tokenize的話,結果如下
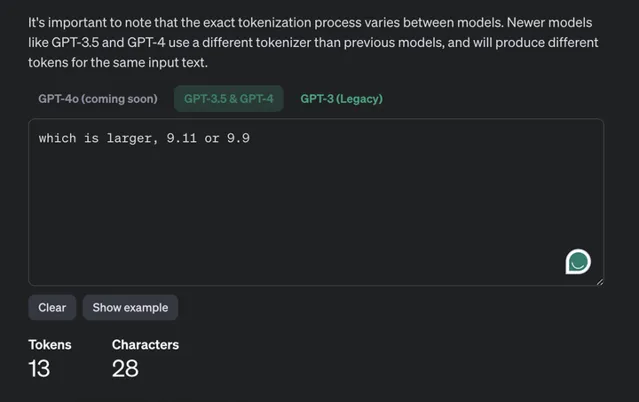
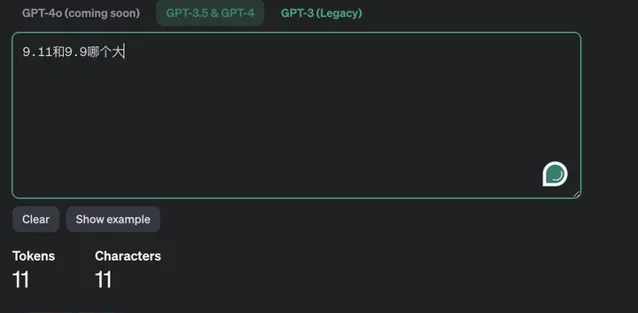
可以看到,9.11被拆成了3個token,結果就導致小數前面的9和9比,小數點後面的9和11比。
同樣的,Anthropic Claude的Tokenizer也一樣
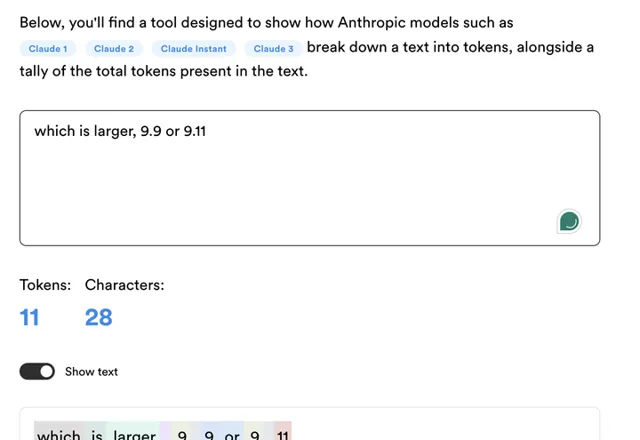
我一個小時前測試時,GPT4, 4o, Claude3.5 sonnet, kimi都翻車了,而通義千問,豆包,文心一言,glm4等大模型都做出了正確的回答,不知道是打了修補程式,還是因為中文大模型的Tokenizer不一樣?具體結果大家可以看我一小時前發的想法,圖太多就不貼進來影響閱讀了。
不過換個角度來說,當9.9和9.11代表軟件版本號是,確實9.11更大。所以從這個角度來講,也不











