這類演算法很多。實際上,這些演算法的特點就是往往在工業界實踐裏早就已經大規模在使用了(並且效果也都不錯),但完備的數學理論要很久以後才出現。
一個簡單的例子是分布式最佳化領域裏的很多演算法,比如現在很多人都很熟悉的ADMM演算法(交替方向乘子法),工業界版本早在幾十年前就有人用了,但完善的分析是最近幾年才慢慢出現的。
不過這邊說兩個我個人覺得很有意思的「演算法」,因為它們有著更加生動的工業套用背景,也被歸類於所謂的 營運管理 (Operations Management)問題。
一、流程柔性(Process Flexibility)工藝中的長鏈設計(Long Chain Design)/稀疏結構設計(Sparse Design)
這個問題實際中的套用很好理解,無非是一個制造業公司設計工廠/生產線的問題。比如我們有很多種不同(但可能相近)的產品,如可口可樂的基礎版可樂,無糖可樂,櫻桃味可樂等等。每種不同類別的可樂都有一定的需求。我們的一個決策是:我們的幾家工廠應該如何分工,比如這些工廠基礎的生產線都是生產基礎可樂的, 我們要不要花一些錢添置更多的生產線,讓它們生產更多種類的可樂,以滿足不同地區對不同可樂的需求 ,這也就是所謂的process flexibility design。
也就是說,我們的設計可以抽象看成一個 二分圖 (bipartite graph)。你可以認為 右邊的節點表示顧客對不同產品的需求,而左邊的節點是我們的工廠們 。這裏從左到右的箭頭就表示,這每一條 從工廠x到產品y的arc意味著工廠x有能力生產產品y 。而工業界實踐裏很早就開始用的一種經驗化的稀疏設計便是所謂的 long chain design (見下圖左),即每個工廠的degree都是2(只需要連線2個產品),且最後整體的圖上形成一個閉環(cycle),即long chain是個 closed chain (定義見下右圖)。這也很直觀, 每個廠就生產兩種可樂,每個可樂也由兩個廠來生產 !
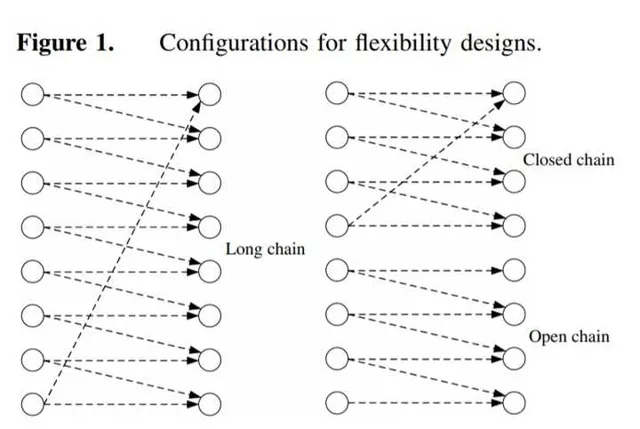
那麽問題就來了,雖然工業界這套「演算法」早就用了幾十年,而且實際上發現在各種情況下這個long chain design相比所謂的full flexibility design(即所有的左右節點全部連起來,當然這個design的造價就很高了)表現差不多, 但理論上其實一直沒有一個很好的模型可以來解釋為啥這個long chain design其實就挺好 。這個問題在理論上第一次在下面的paper裏提出(有個早期版本是91年發表的)。
Jordan, William C., and Stephen C. Graves. "Principles on the benefits of manufacturing process flexibility." Management Science 41.4 (1995): 577-594.
然後過了 20年左右 ,才由下面的paper 第一次在一個嚴格的數學框架下 (和對demand比較mild的假設下) 證明了long chain design在所有2-flexibility design中是漸進最優 (asymptotically optimal)的。這篇paper很核心的一點是利用了flexibility design在bipartite graph上的 supermodular 的。
Simchi-Levi, David, and Yehua Wei. "Understanding the performance of the long chain and sparse designs in process flexibility." Operations research 60.5 (2012): 1125-1141.
這之後,下列paper利用 半正定規劃(SDP)和概率論中的最佳化不等式 的技巧證明了long chain design和full flexibility design 非漸進(non asymptotic)的deviation bound ,並透過數值實驗表明在大多數情況下確實這個bound都很小!
Wang, Xuan, and Jiawei Zhang. "Process flexibility: A distribution-free bound on the performance of k-chain." Operations Research 63.3 (2015): 555-571.
這類模型在隨機模型的queueing model裏也可以有intepretation。比如可見下面的文章。
Tsitsiklis, John N., and Kuang Xu. "On the power of (even a little) resource pooling." Stochastic Systems 2.1 (2012): 1-66.
這類模型實際上包含著非常精彩的數學,從這些研究中你可以看到 概率論與隨機模型,和最佳化理論,組合分析 的優美交叉。也因此在那幾年裏,這個topic成為了運籌學、管理科學的一個熱門研究領域。可惜我感覺知乎上對這些topic感興趣的人不會很多,這裏就先不展開了。
二、基於兩類采購(Dual Sourcing)的庫存管理系統(inventory system)的最優補貨策略
這又是一個物理上非常好理解的數學模型。所謂dual sourcing,就是說你(一般來說是你的角色是個零售商,retailer)的補貨渠道上抽象認為有兩類供應商(supplier), 一類給你補貨的速度快但是收費高 (可以簡單認為是 空運,express order ), 另一類給你補貨的速度慢但是收費低 (可以簡單認為是 陸運、海運,regular order )。這個時候我們為了應對日常的顧客需求 應該如何利用這兩類供應商來進行日常的補貨,使得總體的風險最低(比如斷貨和過多囤貨),獲得最高的收益呢 ?
這個問題可以寫成一個多階段的隨機規劃問題(multi-stage stochastic programming),或者隨機動態規劃(dynamic programming)。然而不幸的是,這個動態規劃的最優策略長的非常奇怪,幾十年中研究者都沒發現有什麽規律。
工業界實踐來說自然不可能等你們學界這麽弄,所以對這個問題也是早有一個 極易實作,著名的啟發式演算法 。這個策略有個好聽的名字,叫做 tailored base-surge policy (TBS 策略)。簡單來說,我們每個period都用 regular order進一個固定數量(constant order) ,作為我們的base,「基本盤」。然後再根據需求預測計算一個 express order的order-up-to level ,即只要我們總的進貨量沒到這個數,就進到這個數,不然就不使用任何express order。也就是說TBS策略你實作的時候 只要每天知道兩個「數」就可以了,兩邊進貨策略完全按照這兩個數來就行 。和前面的long chain design一樣, 這個「演算法」實作起來簡單到看起來都不像個演算法 。
最早關於這類問題理論上的討論可以追溯到:
Whittemore, Alice S., and S. C. Saunders. "Optimal inventory under stochastic demand with two supply options." SIAM Journal on Applied Mathematics 32.2 (1977): 293-305.
而這類TBS策略,經過 40多年的猜想 ,才由如下paper嚴格地證明,在這類隨機動態規劃模型下是 漸進最優 (asymptotically optimal,註意這裏的漸進指訂貨的lead time一直增大)的。
Xin, Linwei, and David A. Goldberg. "Asymptotic optimality of Tailored Base-Surge policies in dual-sourcing inventory systems." Management Science 64.1 (2017): 437-452.
其實我也比較好奇知乎上有多少做OM的同學了,看到評論區冒個泡好麽?對不了解OM這個方向的同學,這兩個例子應該也算是比較生動的科普了。
套用數學也可以很有意思,不是麽?










