batch size可以說是所有超參數裏最好調的一個,也是應該最早確定下來的超參數。
我的原則是,先選好batch size,再調其他的超參數。
實踐上來說,就兩個原則——batch size別太小,也別太大,其他都行。
聽起來像是廢話,但有時候真理就是這麽簡單。
合適的batch size範圍和訓練數據規模、神經網絡層數、單元數都沒有顯著的關系。
合適的batch size範圍主要和收斂速度、隨機梯度噪音有關。
一,為什麽batch size別太小?
別太小的限制在於, batch size太小,會來不及收斂。
有一篇NeurIPS2019[1]說,「learning rate/batch size比值越大,泛化越好」。
所以文獻裏都這麽說了,那我們是不是一定就應該選盡量小batch size呢?
那當然不是了。你看一下文獻[1]的generalization bound的證明是long-time limit的定態分布和continuous-time approximation下證明的。
當你的batch size太小的時候,在一定的epoch數裏,訓練出來的參數posterior是根本來不及接近long-time limit的定態分布。
所以batch size下限主要受收斂的影響。
所以在常見的setting(~100 epochs),batch size一般不會低於16。
如果你要選更小的batch size,你需要給自己找到很好的理由。
二,為什麽batch size別太大?
batch size別太大的限制在於兩個點,
1)batch size太大,memory容易不夠用。這個很顯然,就不多說了。
2) batch size太大,深度學習的最佳化(training loss降不下去)和泛化(generalization gap很大)都會出問題。
隨機梯度噪音的magnitude在深度學習的continuous-time dynamics裏是 正比於learning rate/batch size。batch size太大,噪音就太小了。
而大家已經知道,隨機梯度噪音對於逃離saddle points [2]和sharp minima [3]都必不可少的作用。前者可以解釋為什麽最佳化出問題,後者則可以解釋為什麽泛化出問題。
所以當你 跑large-batch training的時候,就應該用linear scaling rule [4]。就是保持learning rate/batch size和正常設定一致即可。
這是目前的一些常識。
中文互聯網大多數介紹文章也是到這裏就結束了。
但是還沒完。
linear scaling rule最開始是一條經驗規則,但它還有自己的故事——它其實是可以從Langevin Dynamics推匯出來的。有空我單獨介紹一下怎麽推,其實對懂一些統計物理的人來說很簡單。
總之,可以證明, learning rate/batch size的比值對深度學習是有指數級的影響 [3],所以非常重要,沒事別瞎調。
(關於文獻[3],我有一篇專門的介紹文章:梯度下降法的神經網絡容易收斂到局部最優,為什麽套用廣泛?)
最後,很多人忽略的一點就是, 這個linear scaling rule也有一個尷尬的極限。
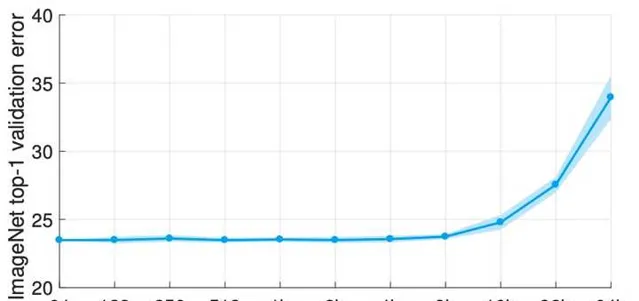
在ImageNet上,batch size達到16K的時候,無論怎麽調learning rate, large-batch training都比正常設定顯著得差。
原因在於large learning rate帶來的訓練誤差太大了,偏偏深度學習small learning rate下的理論很多,而large learning rate下的理論幾乎是空白。所以大家現在對解決這個問題其實是沒什麽有效的思路。
(文獻[5]說自己可以用full-batch training達到minibatch training的效果哦。但是沒完,你仔細看看文獻[5]的minibatch的baseline是沒有用weight decay,比標準的baseline差得遠。)
而在CIFAR上,你甚至不太容易觀察到這個linear scaling rule。因為在常規的200個epoch左右的訓練下,這個linear scaling rule已經接近失效了。
因為,learning rate調大一點,200個epoch甚至就來不及收斂了。這種情況的表現形式是,generalization gap很小,但是training loss降不下來。
所以, 怎麽把large-batch training的極限batch size提高,是一個有很高工業價值和學術價值的課題。
References:
[1] He, F., Liu, T., & Tao, D. (2019). Control batch size and learning rate to generalize well: Theoretical and empirical evidence. In International Conference on Neural Information Processing Systems .
[2] Jin, C., Ge, R., Netrapalli, P., Kakade, S. M., & Jordan, M. I. (2017, July). How to escape saddle points efficiently. In International Conference on Machine Learning (pp. 1724-1732). PMLR.
[3] Xie, Z., Sato, I., & Sugiyama, M. (2020). A diffusion theory for deep learning dynamics: Stochastic gradient descent exponentially favors flat minima. In International Conference on Representation Learning .
[4] Goyal, P., Dollár, P., Girshick, R., Noordhuis, P., Wesolowski, L., Kyrola, A., ... & He, K. (2017). Accurate, large minibatch sgd: Training imagenet in 1 hour. arXiv preprint arXiv:1706.02677 .
[5] Wu, J., Hu, W., Xiong, H., Huan, J., Braverman, V., & Zhu, Z. (2020, November). On the noisy gradient descent that generalizes as sgd. In International Conference on Machine Learning (pp. 10367-10376). PMLR.











