最優解不知道,反正是最終解,因為不可能靠程式碼的不斷擴充去cover所有工況,最終一定會走向大模型。
2024年,端到端的自動駕駛解決方案怎麽樣
同系列文章請移步:
AI「湧現」,大模型與自動駕駛
為什麽國內不能用FSD?L3車輛上路需要哪些準備?
2024年了,端到端的自動駕駛解決方案怎麽樣了
城市NOA與開城,2024自動駕駛首個必爭之地
2024年了,各家都在用什麽智駕演算法
特斯拉 AP (autopilot)和FSD(Full Self-Drive)
從最近炒得火熱的「幽靈剎車」AEB想到說...
1 什麽是端到端的自動駕駛解決方案
「端到端」是深度學習中的概念,英文為「End-to-End(E2E)」,指的是一個AI模型,只要輸入原始數據就可以輸出最終結果。
比如最近很火的ChatGPT,就是一個典型的端到端模型,輸入文字語句,直接就能得到回答。

那對於智能駕駛來說,「最終結果」指的是什麽?智能駕駛其實就是讓車輛自動從A點到B點。這需要車做些什麽呢?跟人開車是一樣的:踩油門剎車、打方向盤。踩油門還是踩剎車?方向盤向左打還是向右打?這就是智能駕駛AI模型應該輸出的「最終結果」。
2023年馬斯克在描述FSD Beta v12 時,就提到了它可以實作輸入影像,輸出轉向、剎車、加速等車輛控制訊號的能力,因此說它是「端到端」的。

像特斯拉FSD Beta v12 這種「端到端」,其實還有一種說法,叫做「感知決策一體化」,也就是將「感知」和「決策」融合到一個模型中。
2 端對端有優勢嗎
目前已量產的智能駕駛,絕大多數采用的是模組化架構,就是把智能駕駛拆分成一個個典型任務,然後將這些任務交由專門的AI模型或模組來處理,比如說感知、預測、規劃等等。
感知模型的任務就是輸入網絡攝影機等傳感器資訊,然後在裏面找到車輛周圍的障礙物、車輛、車道線、紅綠燈等一切與駕駛相關的元素,然後把感知資訊匯總給規劃模型,規劃模型就會根據得到的資訊規劃出車輛的最佳行駛路線,再交給控制模組(控制模組一般並非AI模型),實作車輛最終的控制。
在這種架構中,每個大的模組下,又可能是以多種模型組合而來的,例如感知,其中可能包含了分類、追蹤、定位等AI模型,各司其職。
也就是說,一個智能駕駛系統裏,可能包含了很多很多個模型。
這種架構的弱勢在於,
1)每個模型都要專門進行訓練、最佳化、叠代,隨著模型的不斷前進演化,參數量提高,所需的研發人員也水漲船高,研發投入極高。
2)模組化架構可以看做是一種流水線,很多模型的輸入參數,其實是前級模型的輸出結果。如果前級模型輸出的結果有誤差,就會影響下一級模型的輸出,導致級聯誤差的出現,最終影響整套系統的效能。

而端到端架構,則是透過一個模型實作了以上多種模型的功能。在自動駕駛的端到端方法中,一個深度神經網絡模型通常被用來學習輸入和輸出之間的復雜對映關系。該模型可以接收傳感器數據(如影像、激光雷達數據等)作為輸入,並輸出車輛的控制指令(如方向盤角度、剎車和加速等)。透過大規模的數據集和適當的訓練演算法,模型能夠學習從感知到控制的完整駕駛策略。
1)研發人員只需要針對這一個模型進行整體訓練、調整最佳化,即可實作效能上的提升,因此可以更好地集中資源,實作功能聚焦。
2)輸入傳感器訊號後可以直接輸出車控訊號,大大降低了級聯誤差的概率,也因此大大提升了系統效能的上限。
3 端對端解決方案的實作有什麽難點
進行端到端智能駕駛技術的研發的除了特斯拉外,還有輝達、comma.ai等廠商。2016年的時候,輝達就提出了利用CNN(摺積神經網絡)直接將車載網絡攝影機的影像對映到方向盤轉角的方法,這種自動駕駛行為其實是一種模仿學習(或者叫行為複制),需要事先收集人類開車時的影像以及這幅圖所對應的方向盤轉角,然後透過監督學習學習的方法讓CNN去擬合一個從影像到方向盤轉角的對映。
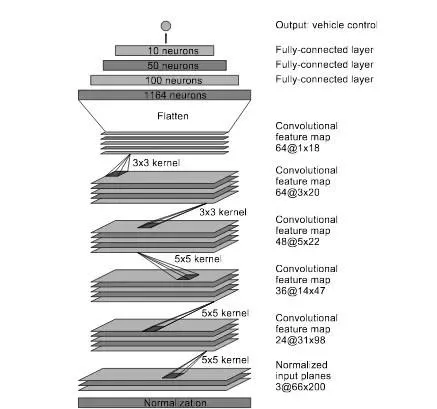
在量產車上看,模組化架構依然是目前智能駕駛的絕對主流,可見端到端架構依然存在一些關鍵的問題未能解決。
1)可解釋性低
一個模型,如果可解釋性好,說明人們對這個模型的運作邏輯是能理解的,也就能更細致且有目的地來對模型進行調整。
端到端智能駕駛是個黑盒子,即便出了差錯,研究人員也不知道它為什麽會出差錯,到底是哪一部份出了問題,又該如何去避免。只能透過不斷的訓練、調參、增加參數量,來盡可能地提高模型的準確率,但最終能否達到100%的安全,還是要打一個問號。
2)訓練難
傳統的感知模型訓練時,需要的是經過標註的圖片,這是一種比較容易獲得的素材。
而端到端智能駕駛,它需要學習的是駕駛行為,因此需要大量標註有駕駛行為的影片才能進行進行訓練。素材采集和標註都很困難。
2023年7月的特斯拉Q2財報電話會議上,馬斯克曾經介紹過端到端FSD的訓練規模:
「特斯拉花了大約一個季度的時間完成了1000萬個影片片段的訓練。訓練了100萬個影片case,勉強可以工作;200萬個,稍好一些;300萬個,就會感到Wow;到了1000萬個,它的表現就變得難以置信了。」