從數碼電路的角度來看,如果CPU沒有流水線,那麽整個CPU的邏輯全部都是組合邏輯。
組合邏輯最大的問題就是如果一個tick(頻率的倒數,也叫周期)涉及到的邏輯門很多,那麽訊號傳輸的路徑就會很長,我們把對這個tick能跑多快影響最大,最長的那條路徑叫做「關鍵路徑」。
這條路徑的長度越長,他所要經過的邏輯門個數越多,那麽訊號在這條路徑上傳輸的延時就會變長。那麽當頻率太快的時候,可能前一個訊號還在邏輯門裏面跑,後一個訊號馬上又輸入進了邏輯門,導致無法正常工作。所以組合邏輯的頻率就不能跑的太快。
流水線就不一樣了,由於流水線將一條很大的組合邏輯路線切割成了多個小Module來跑,每個Module之間的狀態透過Register和Wire來傳輸。這樣做的話,從單個訊號來看,反而要跑的路徑變長了,因為要多走一些Register和Wire。所以從這裏可以看出題主的命題【CPU流水線設計的級越長,完成一條指令的速度就越快】是錯誤的。
我們平時用電腦,肯定不是開機之後只執行一條指令就關機了,而是有非常多的任務要做。那麽這時候每個Module就可以在不同的時間針對不同的任務使用,而不是單周期裏面一個組合邏輯裏面的一個訊號走完,在走下一個訊號進去。所以從多工處理來看,流水線增大了吞吐量,也就是每秒可執行的任務數量。
從這裏還可以看出一個事實,就是加入了流水線機制之後,所需要的Register和Wire會增多,這些部件會直接增大IC芯片的制造成本。增大功耗和發熱量。所以流水線是典型的用空間,功耗,發熱換取較快的執行速度(主頻)。
我們在用Intel(Altera)的FPGA芯片,在Quartus II開發套件裏面有個工具叫做TimeQuest,它可以幫助我們做STA靜態時序分析。時序約束的意思就是檢查我們當前的數碼電路設計,當一個訊號走完整個top module(頂層設計模組)的時候,還剩多少slack(時間余量)。
當這個值為正的時候,說明在當前頻率下,這個設計是沒問題的,但是如果再超一點頻的話,可能導致這個頻率周期內,訊號無法走完整個組合邏輯,就會導致slack為負數,顯然這個設計是不太穩定的,雖然可能極端情況下(例如如果工作溫度過高或者過低,FPGA供電電壓上下波動影響,可能導致訊號建立速度變快)可以正常工作,但是一般情況下仍然有失敗,當機,數據錯亂的風險。
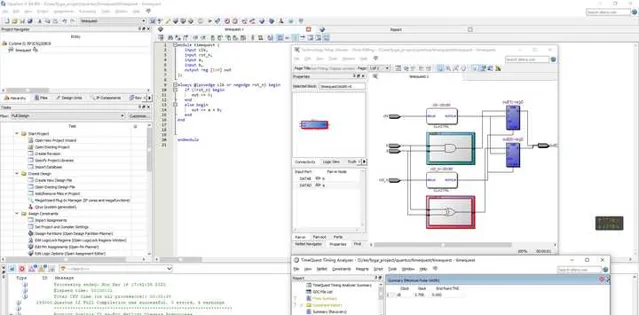
如圖所示就是一個最簡單的1 bit全加器在set clock為100MHz的情況下,在Intel(Altera) Cyclone II FPGA下的時序約束報告,slack報告時間余量還有7.758ns,說明我們約束這個器件在100MHz的主頻下工作是OK的。也就是意味著這個加法器的設計在Cyclone II這款器件上是可以成功跑在100MHz的。
我們平時對CPU超頻,其實和做STA靜態時序分析差不多,例如利用BIOS這樣的程式不斷調整倍頻,就像Quartus II裏面不斷調整PLL鎖相環的倍頻參數一樣。然後開機跑各種烤雞測試軟件判斷CPU執行各種任務是否正常,就相當於TimeQuest去驗證每條路徑的slack是否為正。因為執行一些普通Office等辦公軟件,可能只會用到一些整數操作指令,這些指令所涉及到的CPU芯片裏面的組合邏輯電路比較少所以時間余量很大可以正常工作,而烤雞軟件烤FPU,烤SSE,AVX各種擴充套件指令集,這些電路因為頻寬大,可能比較復雜,相當於把一些關鍵路徑時序很惡劣的電路也去執行一遍,檢查這些時序最惡劣的路徑的時間余量是否充足。這也證明了為什麽有些時候超頻可以正常開機,但是開遊戲或者影片轉碼就當機。
最終透過不斷挑戰試探,找出這塊CPU裏面關鍵路徑的slack的最小值能到多少,也就是主頻可以超到多高。
最後你問的問題【為什麽不整合更多的擴充套件指令集呢。】
事實上RISC的目的就是用更少的指令集做更多的事情,所以整合更多指令集和設計理念是相反的。
指令集分為基礎指令集和擴充套件指令集。基礎指令集就是X86,比如mov,jmp那些的,擴充套件指令集是一些SSE,AVX指令集,這些指令集只有在處理向量,媒體計算才需要用到。即使用不到,他也會在CPU裏面占用面積和制造成本,還有靜態功耗。
RISC-V這個ISA指令集架構裏面的基礎指令集甚至只有I型整數加減計算指令,其他乘除法,浮點運算單元全部都作為擴充套件指令集來處理,這樣的好處就是最大化相容性。因為編譯器和程式設計師只要相容基礎指令就好了。事實上從宏觀統計來看,嵌入式領域的乘除法或者浮點運算用的都很少,或者計算量很小可以改成用基礎指令集裏面的加減法來模擬(乘法用多個加法模擬,除法用多個減法模擬)。
至於X86的CPU我研究的不是很多,但是我猜也是類似的思想。(Intel統計過基礎指令集和現有指令集能覆蓋50%以上的套用場景,所以剩下不到一半的那些本應該做進擴充套件指令集的指令都透過顯卡GPGPU通用計算或者USB硬件加速卡或者PCI-E接入FPGA硬件加速卡來解決了)











