向您介紹 MedPeer」文件對話「功能 ,我們深耕於生物醫學科研 領域多年,透過人工智能大語言模型 ,提供基於文獻內容的互動式問答對話,幫助科研人員快速閱讀 文獻、理解要點,高效篩選、套用文獻,徹底解決文獻相關三大痛點。
痛點1 讀不完
閱讀文獻是搞科研的基本日常,一篇博士畢業論文 中的參考文獻 都可達上百篇。但閱讀文獻費時費力,有時甚至花了大量時間卻毫無收獲。很多研究生 階段的科研新手甚至不具備讀文獻的能力,常常讀到後面卻發現已經忘了前面的內容。這樣看文獻無異於猴子 掰玉米,達不到預期效果,對於撰寫論文也幫助不大。
MedPeer「文件對話」提供與文獻高效「溝通」的渠道,您只要會聊天,透過與AI進行基於文件內容的即時問答 ,就能快速讀懂文獻。
在「文件對話 」模組首頁拖入或選擇要解讀的PDF文件(不多於50頁、不大於30MB),點選「建立對話」,即出現解讀頁面,左邊是上傳的文件,右邊用於和AI對話。首先, AI會根據文件名稱、內文關鍵詞等快速分析 出文件內容的大致方向 ,以此為依據提供多個推薦提問。
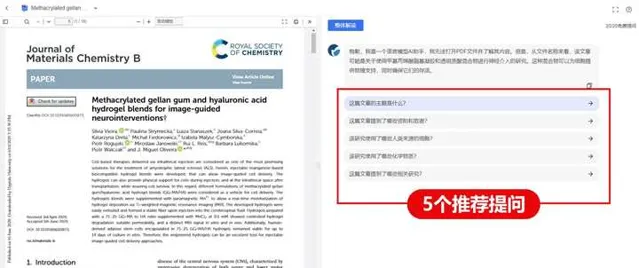
比如,對於一篇標題為「Methacrylated gellan gum and hyaluronic acid hydrogel blends for image-guided neurointerventions 」的文章,AI透過標題初步判斷文章可能是關於使用甲基丙烯酸酯基凝膠 和透明質酸混合物進行神經介入的研究,於是提供「這篇文章的主題是什麽?」「該研究使用了哪些人類來源的細胞?」等5個推薦提問。
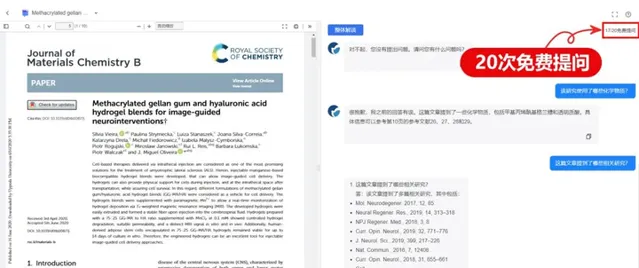
對於上述文件,當詢問該研究使用了哪些化學物質時,AI一一列出了文中提到的化學物質,包括甲基丙烯酰基格蘭糖 和透明質酸,並提醒「具體資訊可以參考第10頁的參考文獻26、27、28和29」。
痛點2 看不懂
面前擺著一篇業界大咖的論文,但是從文章概念到結構,或許是由於基礎知識薄弱,或許是專業名詞太多搞不懂,總之讀起來都很費勁,深深的挫敗感襲來……
MedPeer文件對話功能的一大目標就是幫助科研人員讀懂文獻。借助先進的人工智能大語言模型 , 系統能夠精準解析文件,為您節省閱讀和理解的大量時間。
在解析一篇題為「A Comprehensive and Scientifically Accurate Pharmaceutical Knowledge Ontology based on Multi-Source Data」的文獻時,系統解析後快速得出結論:「該文章介紹了一個基於多源數據的藥物知識本體論 ,旨在提供藥物資訊的標準化表示,包括活性和非活性成分、臨床試驗、文獻、專利、靶點、治療和生物分子 等方面。」
痛點3 想不透
科研的靈魂是創新 ,僅僅記住別人做的研究是遠遠不夠的,看完並記住成千上萬篇文獻卻想不透,做不出好的研究,那就純粹是浪費時間。因此,MedPeer文件對話的誕生,不只是為了幫您看完、讀懂文獻, 我們的終極目標是:助您開拓思路,激發創新。
「文件對話」還內建了獨特的整體解讀功能,目前版本支持Journal Article(研究型論文)、Review(專業綜述)、Clinical Trial(臨床試驗)、Meta-analysis(薈萃分析)、Case Report(病例報告)類別的文獻, 解讀內容包括三個方面:對文章內容的整體概括 ;文中提煉出的研究方法 ;結論和對文章的評價,如創新點和不足。
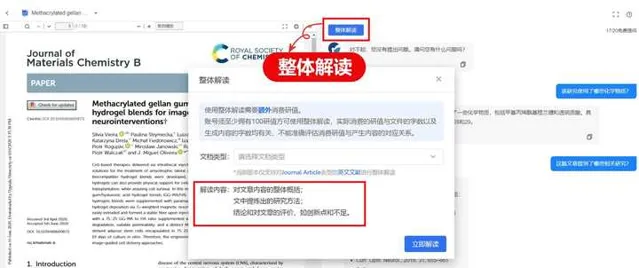

這樣的全方位解讀同時從多角度對文章進行深度評價,能夠有效地幫助您在看完一篇文獻後「靈光一閃」, 提出問題、產生新的想法,甚至找到創新研究 方向。
事實上,無論您是否是科研工作者,只要想深入鉆研某個領域,有閱讀文獻的需求,都可以用MedPeer文件對話功能當幫手,以便高效理解和掌握學術文獻。您會發現, MedPeer使用的人工智能大語言模型不局限於生物醫療科研領域,它其實很全能。











