批次處理的方法就是隔一段時間就分批次處理一次積攢的數據。
一般情況下是先把數據存入數據庫裏,隔一段時間就從數據庫獲取數據
批次處理的重點在於要在規定時間內處理所有數據。因此,數據的數量越多,執行處理的機器效能就得越好。
隨著以後萬物互聯時代的來臨,數據量也會成幾何倍數增加。
人們需要處理從數量龐大的器材發來的傳感器數據和影像等大型數據,這被稱為 「大數據」 。不過, 透過使用一種叫作分布式處理平台的平台軟件 , 就能高效地處理數兆、數千兆這種大型數據了 。具有代表性的 分布式處理平台包括Hadoop 和Spark 。
Apache Hadoop
Apache Hadoop 是一個對大規模數據進行分布式處理的開源框架。Hadoop 有一種叫MapReduce 的機制,用來高效處理數據。MapReduce是一種專門用於在分布式環境下高效處理數據的機制,它基本由Map、Shuffle、Reduce 這3 種處理構成
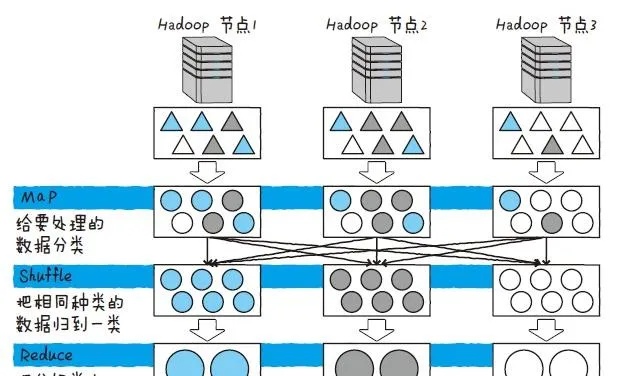
Hadoop 對於每個被稱為節點的伺服器執行 MapReduce ,並統計結果。首先是分割數據,這裏的數據指的是各個伺服器的處理物件。最初負責分割數據的是Map。Map 對於每條數據反復執行同一項處理,透過 Map 而發生變更的數據會被移送到下一項處理,即Shuffle。Shuffle 會跨Hadoop 的節點來把同種類的數據進行分類。最後,Reduce 把分類好的數據匯總。
MapReduce 是一種類似於收集硬幣,按種類給硬幣分類後再點數的方法。
另外,Hadoop 還有一種叫 分布式檔案系統(HDFS)的機制 ,用於在分布式環境下運Hadoop。HDFS 把數據分割並存入多個磁盤裏,讀取數據時,就從多個磁盤裏同時讀取分割好的數據。這樣一來,跟從一台磁盤裏讀出巨大的檔相比,這種方法更能高速地進行讀取。如上所述,如果使用MapReduce 和HDFS 這兩種機制,Hadoop 就能高速處理巨型數據。
Apache Spark
Apache Spark 也和Hadoop 一樣,是一個分布式處理大規模數據的開源框架。Spark 用一種叫作RDD(Resilient Distributed Dataset,彈性分布數據集)的數據結構來處理數據
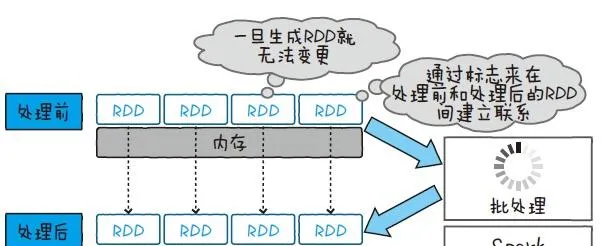
RDD 能夠把數據放在記憶體上,不經過磁盤存取也能處理數據 。而且RDD 使用的記憶體不能被寫入,所以要在新的記憶體上展開處理結果。透過保持記憶體之間的關系,就能從必要的時間點開始計算,即使再次計算也不用從頭算起。根據這些條件, Spark 在反復處理同一數據時(如機器學習等),就能非常高速地執行了。
對物聯網而言,傳輸的數據都是一些像傳感器數據、語音、影像這種比較大的數據。批次處理能夠儲存這些數據,然後匯出當天的器材使用情況,以及透過影像處理從拍攝的影像來調查環境的變化。隨著器材的增加,想必今後這樣的大型數據會越來越多。











