節省視訊記憶體方面,歡迎關註我們團隊最近開源的工作:
個人認為這個工作把單卡訓練,或者是數據並列下的視訊記憶體節省做到極致了~
這裏主要介紹一下單機訓練上的思路。
隨著模型越來越大,GPU 逐漸從一個計算單元變成一個儲存單元了,視訊記憶體的大小限制了能夠訓練的模型大小。微軟的 DeepSpeed 團隊提出我們其實可以把最佳化器狀態(Adam 的 momentum 和 variance)放在 CPU 上,用一個實作的比較快的 CPU Adam 來做更新,這樣既不會變慢很多,也可以明顯省出來很多空間。我們把這個思想再往前推一步,我們是不是可以只把需要計算的模型參數放在 GPU 上,其余的模型參數,最佳化器狀態都放在 CPU 上,這樣就可以盡最大能力降低對視訊記憶體的需求,讓 GPU 回歸它計算單元的本色。
為了達成這樣的效果,我們就需要一個動態的視訊記憶體排程——相對於 DeepSpeed 在訓練前就規定好哪些放在 CPU 上,哪些放在 GPU 上,我們需要在訓練過程中即時把下一步需要的模型參數拿到 GPU 上來。利用 pytorch 的 module hook 可以讓我們在每個
nn.Module
前後呼叫回呼函式,從而動態把參數從 CPU 拿到 GPU,或者放回去。
但是,相信大家能夠想象到,如果每次都執行到一個 submodule 前,再現把參數傳上來,肯定就很慢,因為計算得等著 CPU-GPU 的傳輸。為了解決計算效率的問題,我們提出了 chunk-based management。這是什麽意思呢?就是我們把參數按照呼叫的順序儲存在了固定大小的 chunk 裏(一般是 64M 左右),讓記憶體/視訊記憶體的排程以 chunk 為單位,第一次想把某個 chunk 中的參數放到 GPU 來的時候,就會直接把整個 chunk 搬到 GPU,這意味著雖然這一次的傳輸可能需要等待,但是在計算下一個 submodule 的時候,因為連著的 module 的參數都是存在一個 chunk 裏的,這些參數已經被傳到 GPU 上來了,從而實作了 prefetch,明顯提升了計算效率。同時,因為 torch 的 allocator 會緩存之前分配的視訊記憶體,固定大小的 chunk 可以更高效利用這一機制,提升視訊記憶體利用效率。
在 chunk 的幫助下,我們的模型可以做到,CPU 記憶體加 GPU 視訊記憶體有多大,模型就能訓多大。和 DeepSpeed 相比,在同等環境下模型規模可以提升 50%,計算效率(Tflops)也更高。
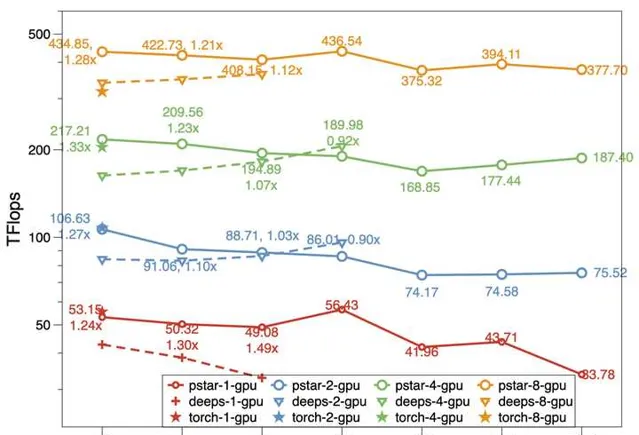
對於多卡的數據並列場景,我們擴充套件了上述方法,可以做到多卡中只有 1 整份模型,1 整份最佳化器狀態,同時具備了數據並列的易用性和模型並列的視訊記憶體使用效率。如果想了解多卡訓練的方案,以及更詳細的一些最佳化,也歡迎來看看我們的論文:
以上。











