旅行商問題的近似最優解(局部搜尋、模擬退火、遺傳演算法)
★ 關鍵字:旅行商問題,TSP,局部搜尋,模擬退火,遺傳演算法」
TSP問題(Traveling Salesman Problem)是一個組合最佳化問題。該問題可以被證明具有NPC計算復雜性。
迄今為止,這類問題中沒有一個找到有效演算法。
也就是說,沒有一個演算法能夠在多項式時間內解得TSP問題的最優解,所以只能透過我們介紹的方法,即遺傳演算法、模擬退火演算法、局部搜尋,來尋求近似最優解。
遺傳演算法
遺傳演算法(Genetic Algorithm, GA)起源於對生物系統所進行的電腦模擬研究。
它是模仿自然界生物前進演化機制發展起來的隨機全域搜尋和最佳化方法,借鑒了達爾文的進化論和孟德爾的遺傳學說。
其本質是一種高效、並列、全域搜尋的方法,能在搜尋過程中自動獲取和積累有關搜尋空間的知識,並自適應地控制搜尋過程以求得最佳解。
private double fitness; // 適應度
private double selectedRate; // 被選中的概率,歸一化處理
@Override
public int compareTo(Species o) {
if (getRouteLength() < o.getRouteLength()) {
return -1;
} else if (getRouteLength() == o.getRouteLength()) {
return 0;
} else {
return 1;
}
}
對個體的操作有可能會影響到適應度,所以在關鍵操作之前必須更新適應度。
由於距離越短,表現越好,那麽適應度就越高,所以可以定義適應度為距離的倒數。
/**
* 獲得適應度
* @return 適應度
*/
public double getFitness() {
updateFiness(); // 返回之前必須先更新(如果需要)
return fitness;
}
/**
* 計算並設定適應度
*/
private void calculateAndSetFitness() {
updateLength(); // 計算適應度之前必須更新長度
this.fitness = 1.0 / getRouteLength();
}
後面用到輪盤賭,被選中的概率必須歸一化處理。
/**
* 設定被選中的概率,歸一化處理
* @param selectedRate 被選擇的概率,歸一化處理
*/
public void setSelectedRate(double selectedRate) {
this.selectedRate = selectedRate;
}
後面用到變異,設計到一個逆轉給定區間,即1-2-3-4,逆轉2-3,就變成1-3-2-4。為方便起見,封裝成了一個方法。
/**
* 逆轉給定區間
* @param left 左端點(包含)
* @param right 右端點(包含)
*/
public void reverse(int left, int right) {
// 逆轉
while (left < right) {
City c = routeList.get(left);
routeList.set(left, routeList.get(right));
routeList.set(right, c);
++left;
--right;
}
雜交和變異都是以一定概率進行的,下面省略隨機數生成和比較的部份,只給出核心程式碼,完整程式碼參見第4部份。
隨機選擇一對父母,隨機選擇一段基因。
直接把這一段父親的基因復制到孩子對應的部份,孩子缺少的基因從母親那裏拿,已經重復的基因跳過。
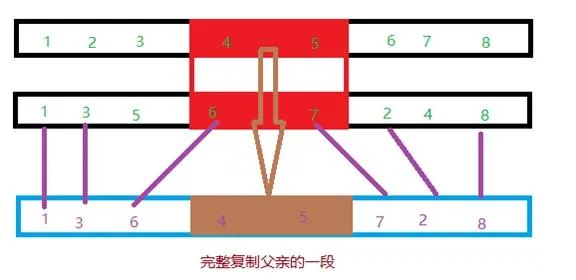
那麽可以得到核心部份的程式碼。
// 直接把這一段父親的基因復制到孩子對應的部份
for (int i = beginIndex; i < endIndex; ++i)
list.set(i, father.get(i));
// 孩子缺少的基因從母親那裏拿
int i = 0;
// 從頭開始遍歷母親的基因
for (int j = 0; j < size; ++j) {
if (i == beginIndex)
i = endIndex; // 跳過父親那一段
City c = mother.get(j); // 獲取母親的基因
// 如果母親的基因已經在孩子身上,就跳過,否則加入
if (!list.contains(c)) {
list.set(i, c);
i++;
}
}
在實作的過程中,需要保證父母不是同一個個體,需要保證隨機一段的序列左端點小於右端點……
得到了孩子的序列以後,構造一個物件,加入到族群中。
變異對每一個個體都有概率,以一定的概率變異
這裏的處理有很多種方法,例如,隨機交換任意兩個城市的位置,又如,隨機逆序一段路徑,再如,隨機選擇若幹個奇數位的城市重新隨機打亂以後按順序放回……
這裏采用了隨機逆序一段路徑的方法。
事實上,也僅對收尾2個城市(4段路徑)影響較大。
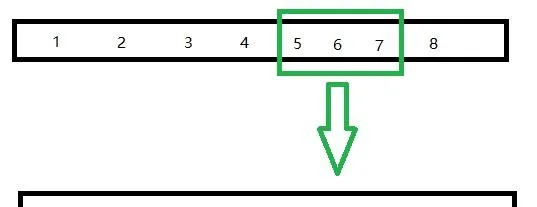
同樣,可以得到核心程式碼。
// 隨機選擇一段基因,逆序
int left = (int) (Math.random() * sp.size());
int right = (int) (Math.random() * sp.size());
if (left > right) {
int tmp = left;
left = right;
right = tmp;
}
sp.reverse(left, right);
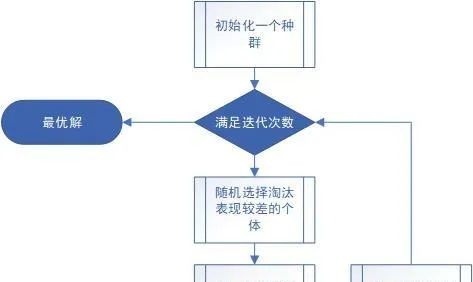
物競天擇,適者生存。
所有表現不好的個體都應該被淘汰。
考慮到表現越好,意味著路徑長度越短,那麽容易想到的是,把族群中所有的個體拿出來看看,按照路徑長度排個序,取最短的若幹名,其他淘汰。
由於個體Species已經實作了Comparable介面,所以直接放進優先級佇列PriorityQueue,然後一個個取出來,要麽取到取完,要麽取到族群最大容量。
// 直接把個體丟掉優先級佇列中,由於個體實作了Comparable介面,所以距離短的方案表現好,優先級高
PriorityQueue<Species> pq = new PriorityQueue<Species>();
pq.addAll(group);
// 清空族群,然後按照個體的表現從好到差放到族群中
group.clear();
while (!pq.isEmpty()) { // 要麽放完
group.add(pq.poll());
if (group.size() == capacity) // 要麽超過了最大容量就不放了
break;
為方便起見,我采用的是這樣的方法,並且實踐證明效果能夠接受。
其主要思想是,表現越好的個體越有可能活著(當然也可能會被淘汰,只是概率太低了以至於可以認為小概率事件不發生),而表現差的個體存活的可能性就小,極有可能被淘汰(當然也可能活著)。
具體的做法是,隨機選擇一個概率,然後看是不是滿足這個個體被選中的概率,如果是,那麽就把這個個體放入到新的族群中,如果不是,就用歸一化的概率減去隨機概率,用新的概率檢查下一個個體。
所有個體檢查完,如果仍沒有放滿族群容量,就再次迴圈,再比較每一個個體,於是,表現較好的個體就可能會被放入新族群2次、3次甚至更多次,直到族群容量滿了。
事實上,更常見的做法是輪盤賭。
下面給出核心部份程式碼。
double rate = Math.random() / 100.0;
Species oldPoint = origin.get(i);
while (oldPoint != null && !oldPoint.equals(best))
{
if (rate <= oldPoint.getSelectedRate()) {
group.add(oldPoint);
break;
} else {
rate = rate - oldPoint.getSelectedRate();
}
}
這樣有可能會走到兩個極端。
第一個極端,很有可能表現最好的個體被淘汰了。
盡管表現最好的個體存活的概率非常非常大,但是如果不幸發生小概率事件,把表現最好的個體淘汰了,那麽就會遺失最優解。
當迴圈次數足夠多的時候,原來的表現第二的個體會在若幹次的雜交和變異中變得越來越好,並進一步優於原來表現最好的個體。
但是這樣明顯會使程式工作效率下降,並且,很可能若幹次以後表現最好的個體再次被淘汰。
我們希望的是,表現最好的那一個,或者那兩個,以1的概率一定存活。
第二個極端,表現最好的個體存活概率很大,後面的個體大多數都被淘汰了,那麽整個新族群就可能會出現90%甚至更多的都是來自最好的那一個或者那兩個個體,後面10%是第三、第五、第十表現好的個體。
這樣就會導致其實很多時候父親和母親都是一樣的,或者說,就是自交而不是雜交,會明顯地降低效率。
綜合上面這兩個極端,可以給出一種妥協的方案——表現最好的個體以1的概率一定存活,但是,最多不能超過新族群的四分之一,剩下的部份按照標準輪盤賭的方案進行,但是當輪盤賭了若幹次以後還沒有填滿族群,不再反復進行,而是直接用表現最差的個體補滿剩下的若幹個位置。
這樣妥協的方案可以有效解決上面兩個極端,且測試效果良好。
for (int i = 1; i <= talentNum; i++) {
group.add(best);// 復制物種至新表
if (oldPoint == null || oldPoint.equals(best))
group.add(origin.getLast());
由於從優先級佇列取出的時候,每個個體只被取出一次,所以不會出現上面說的第二個極端,且由於優先級佇列出隊的順序保證了表現最好的個體一定會在新族群中,所以不會出現上面說的第一個極端。
這樣,在每一次叠代中,表現最優的個體只會越來越好,也就是說,最短路徑的長度只可能變短,不可能邊長,最壞的情況就是不變。
只不過這樣其實就只是按照從好倒壞的順序保留存活,超過族群數量的就直接認為是表現過差,被淘汰。
事實上,在測試的過程中,族群數量在200的時候,表現第200的已經足夠差了,所以這個族群包含了各種情況的樣本,可以認為是完備了。所以超過200的,雖然更差,但是同時也失去了意義,可以直接淘汰。
模擬退火演算法
模擬退火演算法(Simulated Annealing,SA)最早的思想是由N. Metropolis [1] 等人於1953年提出。
模擬退火演算法來源於固體退火原理,將固體加溫至充分高,再讓其徐徐冷卻,加溫時,固體內部粒子隨溫升變為無序狀,內能增大,而徐徐冷卻時粒子漸趨有序,在每個溫度都達到平衡態,最後在常溫時達到基態,內能減為最小。
模擬退火演算法從某一較高初溫出發,伴隨溫度參數的不斷下降,結合概率突跳特性在解空間中隨機尋找目標函數的全域最優解,即在局部最優解能概率性地跳出並最終趨於全域最優。
模擬退火演算法是透過賦予搜尋過程一種時變且最終趨於零的概率突跳性,從而可有效避免陷入局部極小並最終趨於全域最優的序列結構的最佳化演算法。
根據Metropolis準則,粒子在溫度T時趨於平衡的概率為e(-ΔE/(kT))。
其中E為溫度T時的內能,ΔE為其改變量,k為Boltzmann常數。
用固體退火模擬組合最佳化問題,將內能E模擬為目標函數值f,溫度T演化成控制參數t,即得到解組合最佳化問題的模擬退火演算法。
/**
* MetroPolis準則
*
* @param bestRoute
* 最優解
* @param currentRoute
* 當前解
* @param currentTemperature
* 當前溫度
* @return MetroPolis準則的評估值
*/
private static double metropolis(Route bestRoute, Route currentRoute, double currentTemperature) {
double ret = Math.exp(-(currentRoute.getRouteLength() - bestRoute.getRouteLength()) / currentTemperature);
return ret;
}
當溫度較高的時候,接受劣解的概率比較大,在初始高溫下,幾乎以100%的概率接受劣解。
隨著溫度的下降,接受劣解的概率逐漸減少。
直到當溫度趨於0時,接受劣解的概率也同時趨於0。
這樣將有利於演算法從局部最優解中跳出,求得問題的全域最優解。
/**
* 能夠接受劣解的概率
*
* @param currentTemperature
* 當前溫度
* @return 能夠接受劣解的概率
*/
private static double getProbabilityToAcceptWorseRoute(double currentTemperature) {
return (currentTemperature - ConstantValue.CHILLING_TEMPERATURE)
/ (ConstantValue.INITIAL_TEMPERATURE - ConstantValue.CHILLING_TEMPERATURE);
}
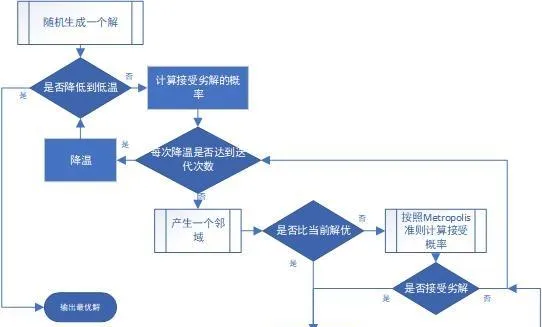
// 用shuffle隨機一條路徑作為初始解,並復制一份作為初始最優解
while (ConstantValue.CHILLING_TEMPERATURE < currentTemperature) {
double p = getProbabilityToAcceptWorseRoute(currentTemperature);
for (int i = 0; i < ConstantValue.SIMULATE_ANNEA_ITERATION_TIMES; i++)
// 產生鄰域
if (neighbourRoute.getRouteLength() <= bestRoute.getRouteLength()) {
// 如果新解比當前解優,接受
} else if (metropolis(bestRoute, neighbourRoute, currentTemperature) > p) {
// 否則按照Metropolis準則確定接受的概率
}
}
// 按照給定的速率降溫
}
局部搜尋
與模擬退火方法類似,區別在於若且唯若新解比當前解更優的時候接受新解。
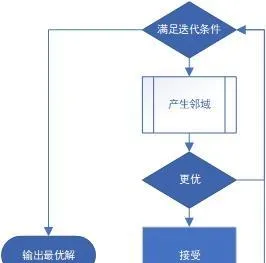
while (successfullyChanged != 0 && changed != 0) {
Route neighbour = route.generateNeighbour();
if (neighbour.getRouteLength() <= route.getRouteLength()) {
route = neighbour;
successfullyChanged--;
}
changed--;
}
演算法測試
正確性測試
考慮僅有4個城市的情況。
這4個城市分別位於(1,0)、(2,0)、(1,1)、(2,1)。
顯然只有2種走法,起路徑長度分別為4和4.828。
三種演算法都能求得正確的最優解。
遺傳演算法:
City [index=2, x=2, y=0] -> City [index=4, x=2, y=1] -> City [index=3, x=1, y=1] -> City [index=1, x=1, y=0] ->
RouteLength = 4.0
局部搜尋:
City [index=3, x=1, y=1] -> City [index=1, x=1, y=0] -> City [index=2, x=2, y=0] -> City [index=4, x=2, y=1] ->
RouteLength = 4.0
模擬退火演算法:
City [index=4, x=2, y=1] -> City [index=2, x=2, y=0] -> City [index=1, x=1, y=0] -> City [index=3, x=1, y=1] ->
RouteLength = 4.0
大規模數據
下面給出10個城市的執行結果。

下面給出144個城市的執行結果。
演算法比較
首先給出10個城市的數據。
10
1 0 0
2 12 32
3 5 25
4 8 45
5 33 17
6 25 7
7 15 15
8 15 25
9 25 15
10 41 12
這組數據的真正最優解是147.34。
下面嘗試使用遺傳演算法執行這組數據,分別執行10次,取這10次結果的平均值和最小值。
這10次結果分別為:147.3408465677464、147.3408465677464、171.87473677989576、147.3408465677464、147.3408465677464、147.3408465677464、147.3408465677464、162.19167266106012、147.3408465677464、147.3408465677464。
這10次結果的最小值是147.34,完全命中最優解。
事實上,有80%的概率命中了最優解。
剩下的2次,一次是162,一次是171,誤差較大。
但是從全域考慮,10組數據的平均值是150.9,也足夠接近最優解了。
同樣,使用局部搜尋和模擬退火演算法,對這組數據進行測試,得到了下面這張表格。
| 演算法 | 10次測試最小值 | 10次測試平均值 |
|---|---|---|
| 遺傳演算法 | 147.34 | 150.9 |
| 模擬退火演算法 | 167 | 197 |
| 局部搜尋 | 147.34 | 148.9 |
從這張表中可以看到,在小數據規模的時候,模擬退火的演算法準確度是最低的。
這可能是由於模擬退火是接受劣解導致的,所以在小數據規模上會出現不在最優解的可能。
下面給出更大數據規模的測試,並且下表僅列出各種演算法在10次測試中出現的最小值。
| 演算法 | 10次測試最小值 | 城市數與理論最優解 |
|---|---|---|
| 遺傳演算法 | 871 | 20個城市,最優解870 |
| 模擬退火演算法 | 871 | 20個城市,最優解870 |
| 局部搜尋 | 918 | 20個城市,最優解870 |
| 遺傳演算法 | 15414 | 31個城市,最優解14700 |
| 模擬退火演算法 | 15380 | 31個城市,最優解14700 |
| 局部搜尋 | 16916 | 31個城市,最優解14700 |
| 遺傳演算法 | 32284 | 144個城市,最優解略小於32000 |
| 模擬退火演算法 | 37333 | 144個城市,最優解略小於32000 |
| 局部搜尋 | 49311 | 144個城市,最優解略小於32000 |
可以看到,數據規模較大的時候,三種演算法都能夠比較接近最優解。
但是由於數值變大,所以絕對誤差也隨之增加。如果計算相對誤差,可以看到相對誤差仍舊處於一個很小的範圍。
同時可以看到,模擬退火的準確度高於了局部搜尋,局部搜尋在大數據下顯得誤差最大,這是由於局部搜尋是最原始的,難以跳出局部最優解,而模擬退火等演算法能夠從局部最優解中跳出。
采用與上面相同的方法,對三種演算法進行測試,得到下表。
同樣的,每組數據,分別對每種演算法執行10次,取10次中執行時間最快的,單位為毫秒。
| 數據規模 | 演算法 | 10次測試最小值(毫秒) |
|---|---|---|
| 10個城市 | 遺傳演算法 | 955 |
| 10個城市 | 模擬退火演算法 | 995 |
| 10個城市 | 局部搜尋 | 230 |
| 20個城市 | 遺傳演算法 | 16595 |
| 20個城市 | 模擬退火演算法 | 918 |
| 20個城市 | 局部搜尋 | 232 |
| 31個城市 | 遺傳演算法 | 2286 |
| 31個城市 | 模擬退火演算法 | 1048 |
| 31個城市 | 局部搜尋 | 235 |
| 144個城市 | 遺傳演算法 | 10080 |
| 144個城市 | 模擬退火演算法 | 1441 |
| 144個城市 | 局部搜尋 | 351 |
完整程式碼











