摘 要
介紹基於自然語言處理技術的ChatGPT的基本構成和自然語言生成與理解方面的優勢,探討其在博物館策展、講解導覽、藏品管理、文創開發、研究咨詢等方面的適用場景。針對實際套用場景,將ChatGPT的表現與人類員工的表現進行對比實驗,論證該技術的穩定性和適用性,分析和闡述以ChatGPT為代表的自然語言處理技術在博物館領域中的發展潛力和未來前景,以及如何應對技術挑戰和限制,有助於推動博物館的高質素發展。
引 言
1
研究背景
隨著人工智能技術的不斷發展,越來越多的機構和行業開始整合AI技術以改進業務流程和提升效率。自然語言處理(Natural Language Processing, NLP)是電腦科學領域與人工智能領域的重要方向,其利用NLP技術代替人類與電腦之間的互動,為使用者提供高效、個人化的服務[1]。
在博物館領域,傳統的聊天機器人只能按照預設的語法和回答模式進行互動,受到限制較大。而以ChatGPT為代表的新一代NLP技術能夠實作博物館藏品、文化和數據等內容的自然語言解析和推理,並構建與使用者的高效、流暢和個人化的互動[2]。同時,新一代NLP技術還具有自主學習和最佳化的能力,能夠不斷提升自身的語言處理能力。因此,對其在博物館領域的套用場景進行研究勢在必行。
2
研究意義
智慧博物館是當前博物館發展的重要趨勢,而NLP技術正是實作博物館數碼化轉型的核心技術之一,可以為博物館提供高效的資訊處理和管理手段。研究NLP技術在博物館領域的套用場景,有助於推動博物館的智能化行程,提升文化傳播的服務品質和效率,為公眾提供更為友好的互動場景,為研究人員提供更便利的檢索條件,為管理者提供更為高效的管理手段。此外,博物館領域的NLP技術套用也是文旅領域中NLP技術套用的重要場景之一。研究博物館領域NLP技術的套用前景,不僅有助於推動博物館數碼化轉型和智能化升級,也為文旅領域其他方面的NLP技術套用和普及提供了借鑒和參考。
自然語言處理技術的技術原理和特點
1
自然語言處理技術概述
自然語言處理(Natural Language Processing, NLP)技術是研究人機互動方式的關鍵技術之一,主要套用於電腦對自然語言文本的處理和理解方面。其核心目標是使電腦能夠像人類一樣理解、分析、處理和生成自然語言文本,實作對文本的語意分析、分類、標註、命名實體辨識、機器轉譯、情感分析、自動文摘、語音辨識等多種功能[3]。NLP技術的發展使得機器更加智能化,能夠處理人類語言互動帶來的復雜性,大大提高了電腦處理文本資訊的能力,在文本挖掘、搜尋引擎、智能客服、語音辨識、聊天機器人等諸多領域獲得了廣泛的套用[4]。
2
ChatGPT的基本架構
基於NLP技術的語言模型有很多。例如,由Google開發的BERT,由微軟開發的DEBERTA,由百度開發的文心一言等,這其中最著名的莫過於由OpenAI開發的ChatGPT。它是一種基於Transformer模型的自然語言處理技術,在自然語言生成方面表現非常出色,能夠根據輸入的語言文本生成有意義、通順、自然的新文本。同時,在使用者進行追問時,會結合之前的語境改善自己的回答(見圖1)。
ChatGPT之所以能夠實作連貫性的生成自然語言,是因為它的架構中包含了多個編碼器和解碼器層,每一層都可以對文本進行理解和生成。此外,它還透過無監督學習技術,在處理大量自然語言文本時,學習了語言規律和隱藏資訊,從而大大提高其自然語言文本的生成能力。現時,ChatGPT已廣泛套用於文本自動生成、檔處理和高效生產工具套用等方面,成為NLP領域的重要突破。

圖1 ChatGPT能生成並改善回答
ChatGPT是一個人工智能聊天機器人,其底層原理和實作方式如下:
ChatGPT使用了生成式預訓練變換器(Generative Pre-trained Transformer)的技術,即利用大量的文本數據進行無監督的預訓練,然後根據不同的任務進行微調。
ChatGPT的模型結構是一個深度神經網絡,由多層自註意力機制(Self-Attention)和前饋神經網絡(Feed-Forward Neural Network)組成。它使用了Transformer-XL的技術,即透過相對位置編碼(Relative Position Encoding)和分段重復(Segment Recurrence)來增強長期記憶能力。
ChatGPT的輸入是一個文本序列,由使用者的訊息和機器人的回復組成。它的輸出也是一個文本序列,即機器人的下一句回復。它使用了自回歸(Autoregressive)的方式,即逐詞生成輸出,並利用掩碼(Mask)來避免看到未來的詞。
ChatGPT使用了交叉熵(Cross Entropy)作為損失函數,即最小化預測詞和真實詞之間的差異。它使用Adam最佳化器(Adam Optimizer)來更新模型參數,並使用學習率衰減(Learning Rate Decay)和梯度裁剪(Gradient Clipping)等技巧來提高訓練效率和穩定性。
3
ChatGPT與傳統聊天機器人的區別與優勢
與傳統的聊天機器人相比,ChatGPT在自然語言生成和理解方面具備更高的準確性和流暢度,同時具有更強的上下文感知和理解使用者意圖的能力[5]。
具體來說,
一是模型生成方式的不同。傳統的聊天機器人往往采用事先定義好的規則和樣版來生成回復;而ChatGPT是基於大規模數據的神經網絡模型,可以在沒有人工設定的情況下自主學習和生成回復。
二是理解使用者意圖的能力不同。ChatGPT可以準確地理解使用者的意圖,並回答使用者的問題或根據使用者的語意生成內容,從而提高了互動的質素和效率。
三是上下文感知能力不同。傳統的聊天機器人往往難以獲取並理解對話的上下文資訊,而ChatGPT可以在對話的過程中感知上下文資訊,從而更好地理解使用者需求並生成更準確的回復。
自然語言處理技術在博物館領域的套用場景
1
客戶咨詢場景
傳統的博物館觀眾咨詢服務通常需要大量的人力資源和器材支持,經濟成本和對人員素質的要求都很高。而使用ChatGPT或類似的NLP技術則能自動處理和回復各種問題,提供準確和快速的解答,降低人力成本、最佳化使用者體驗、提高觀眾滿意度。此外,NLP技術可以輔助博物館進行推廣宣傳,不僅可以產出背景調研、推廣建議、推廣方案的內容,也可以協助網絡資源、宣傳資料、創意文案、語言轉譯等工作。
例如,結合博物館相關數據,NLP技術可以回答使用者關於基礎資訊(博物館地址、開放時間、門票價格、預約方式)、展覽資訊(當前或即將開展的展覽名稱、主題、內容、時間)、藏品資訊(具體藏品名稱、年代、來源、材料、尺寸)、背景故事(藏品背後故事、歷史文化價值)等詳細問題。
為了評估ChatGPT與人工客服的表現,我們收集了一批問題,讓ChatGPT和人工客服分別對其作出回答。例如,以下兩個問題(見圖2),人工的回復為「每日9:00—17:00(16:00停止入場),每周一閉館(除國家法定節假日外)。觀眾攜帶身份證可免費參觀,可以透過官網或者微信公眾號等方式進行預約。遺址博物館的發展優勢主要為:有利於提升訪客觀感;有利於做好遺址安全工作;有利於帶動周邊產業。制約遺址博物館發展的瓶頸問題主要為:受制於遺址的知名度和影響力;受制於遺址看點對公眾的吸重力;受制於遺址研究水平的高低。」
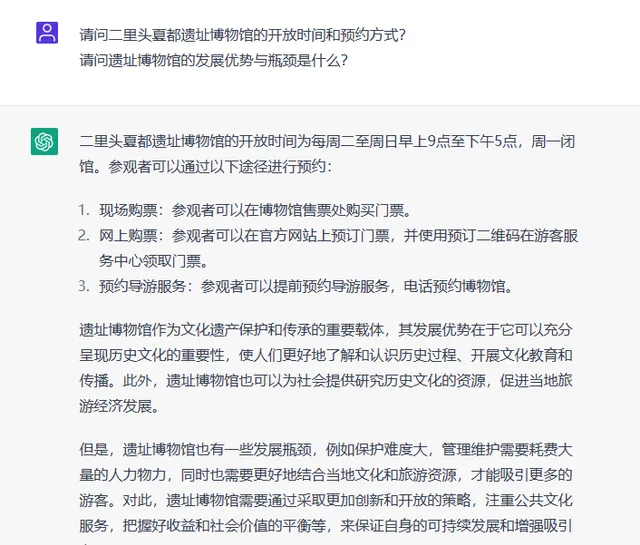
圖2 ChatGPT輸出的問題回復
結果顯示(見表1),與人工客服相比,ChatGPT的回復速度非常快,可以較為準確地回復使用者簡單的咨詢問題,縮短使用者的等待時間,在情感交流和語意表達方面,也具有一定優勢。但在處理復雜、冷門、敏感的問題時,存在一些錯誤,尤其是容易出現捏造事實的情況,導致使用者被誤導。因此,考慮到不同情境下的需求,NLP技術和人工客服可以相互結合,才能實作更好的服務效果。
表1 客戶咨詢評價表
| 評價指標 | 評價物件 | |
| ChatGPT | 人工客服 | |
| 回復速度 | 快 | 慢 |
| 情感交流 | 優 | 優 |
| 語意表達 | 優 | 良 |
| 準確率 | 良 | 優 |
| 事實闡述 | 差 | 優 |
2
導覽講解場景
NLP技術的超強互動性,可以極大拓展博物館陳列展覽的知識邊界,甚至在一定程度上取代傳統的講解員崗位。具體來說,NLP技術在展覽裏可以實作以下3個方面的套用。
1)個人化導覽。
透過使用NLP技術,可以分析觀眾在博物館中的語言、情感和興趣,進而實作個人化展品推薦。觀眾可以透過對話方式告訴系統自己的興趣愛好和需求,系統再根據這些資訊給出相應的推薦展品或路線,甚至直接為觀眾建立一個互動式的探索遊戲。這些個人化的導覽服務可以更好地滿足觀眾需求,提高展覽的互動性。
2)智能化講解。
透過在展廳內設定NLP系統,觀眾不僅可以看到基於展品的關鍵詞和歷史資訊的文本描述,還可以與展品進行互動。NLP技術可根據博物館提供的資訊,生成智能化的講解語音或虛擬人,自動提供更加深入、細致的文物解說。此外,NLP技術可以根據觀眾的需求和興趣,提供個人化客製的講解資訊,例如使用嚴肅或幽默的語氣介紹藏品背後的故事,從而增強觀眾的參觀體驗感。
3)多語種支持。
博物館藏品涉及不同地區的語言和文化,NLP技術可以使講解裝置適應不同的語言和文化背景,以滿足不同地域、國籍觀眾的需求,提高互動的質素和效率。透過NLP技術的支持,觀眾可以更詳細地了解博物館中的藏品,同時也可以更深入地感受文化多樣性帶來的魅力。
讓ChatGPT與具有相關專業知識的博物館講解員分別對同一批文物或展品進行描述。
例如,對於「鑲嵌綠松石獸面紋銅牌飾」這件文物,講解員的標準描述為「器身以青銅鑄出主體框架,呈四角鈍圓,略呈亞腰形,兩側各有對稱環紐。其上以數百片綠松石拼合鑲嵌出獸面紋,加工精巧,絲絲入扣。雖歷經三、四千年無一松動脫落。出土時安放在墓主人胸部,從兩側有對稱的穿孔鈕可見,穿綴系於主人胸前,應作為溝通天、地、神、人等的重要載體。」 ChatGPT的描述如下(見圖3)。

圖3 ChatGPT所作文物描述
對輸出結果進行比較和評估,發現ChatGPT的撰寫速度非常快,語言表達流暢且通俗易懂,也能較為全面地介紹文物的相關資訊。但是專業性較為欠缺,最重要的是出現了與事實不符的情況(見表2)。因此,結合兩者的優點來提供博物館導覽講解服務可能更加有效。
ChatGPT可以作為追問式的答疑工具,可以解決一些簡單、常見的問題,而導覽講解員則可以提供更加深入、全面的解說服務,為遊客提供更加個人化、客製化的導覽體驗。這種以NLP技術和人工服務為結合的方式,可以更好地提高博物館導覽講解的質素和服務效率,為遊客帶來更加豐富、深入的文化體驗。
表2 文物講解對比表
| 任務 | 評價物件 | |
| ChatGPT | 人工 | |
| 撰寫速度 | 快 | 慢 |
| 通俗性 | 優 | 良 |
| 全面性 | 良 | 優 |
| 專業性 | 差 | 優 |
| 事實闡述 | 差 | 優 |
3
展覽策劃場景
傳統的展覽編排和大綱編制需要策展人大量閱讀和處理各種文獻資料,耗費大量時間。NLP技術可以透過文本挖掘、主題提取等技術,快速高效地分析並提取與展覽主題相關的資訊,自動化生成展覽大綱,從而大大提高策劃效率。NLP技術還可以參與到博物館的展覽測評中,根據測評模型生成展覽的測評結果並給出相關建議,輔助策展人提升最佳化展覽。
例如,使用ChatGPT描述策展人的需求,AI會給出展覽思路(見圖4)。在AI給出思路的基礎上,策展人可以不斷豐富和改善需求,透過向AI提出更精準的描述詞,讓AI生成更符合策展人理念的展覽大綱。

圖4 ChatGPT給出的展覽思路
雖然ChatGPT在分析和處理展覽相關資訊方面具有較高的智能性和自動化程度,能夠顯著提高策展初期的效率,但AI缺乏人類的審美,也難以匹配策展人意圖,如果涉及到復雜的展覽主題和專業性強的內容,仍然需要額外的人工處理。策展人需要結合自身的判斷和經驗,制定更完整和創新的展覽計劃。
4
藏品管理場景
NLP技術可以根據研究人員輸入的文物名稱、年代、來源、材料、尺寸等描述資訊,透過自動資訊提取、數據標準化、數據分類等多個環節,整理出清晰、準確的文物數據類別,確保文物資訊的唯一性和標準化。對歸類清晰的文物資訊,NLP技術可以進行智能分類,如不同文物類別的分類、不同年代的分類、不同材質的分類等,以實作文物資訊的有序管理,這些整理後的文物照片、文字資訊、音訊和影片資料等豐富的資訊,可以為博物館的藏品保護工作提供重要的資料支持。
透過NLP技術與人工處理文物資訊的對比試驗,例如提取一批文物清單中的綠松石器。人工的回答為:綠松石龍形器、綠松石珠、綠松石獸。ChatGPT則將鑲嵌綠松石獸面紋銅牌飾和龍形牙璋也列為綠松石器,且事實上,龍形牙璋並沒有鑲嵌綠松石裝飾(見圖5)。
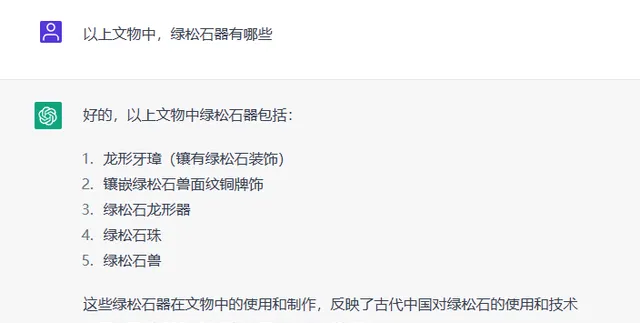
圖5 ChatGPT給出的文物資訊回答
結果顯示,由於文物資訊的復雜性和多樣性,目前ChatGPT在處理文物的基本任務上,並不能夠取得人工相當的準確度和穩定性,更不用說涉及到文物的復雜資訊處理。因此,依然需要人工幹預和稽核,才能確保文物資訊的準確性和可靠性。未來的藏品管理,NLP技術和人工的深入結合是必要的,需要不斷最佳化和改進相應的系統和工作流程,以提升藏品管理的效率和品質。
5
文創開發場景
NLP技術可幫助文創產品開發者快速處理大量背景資訊,包括文物和藏品資訊、歷史故事等等,從而提供更多資訊支持,挖掘歷史文化內涵,為文創產品開發提供了可靠的依據,提升文創產品的文化品位和創新。同時,利用自然語言生成和影像辨識等技術,實作對文物和藏品的多維度呈現,為博物館文創產品設計提供新的靈感和思路,從而打造具有品位和差異化的文創產品。
透過NLP技術與人工設計師做文創產品概念構思相關的對比試驗,例如以「鑲嵌綠松石獸面紋銅牌飾」為主題設計一款生活家居類的文創產品(見圖6)。
人工設計師的設計思路為:首先要了解文物相關的歷史和文化背景,同時結合現代生活和消費者需求,打造出故事性和富有意義的文創產品。利用綠松石和銅這兩種本身具有天然美感的材料,將它們套用於各種生活家居用品中,比如玻璃器皿、地毯、收納盒等等。融合現代和傳統元素,透過一些新穎的造型設計來打造該文創產品。

圖6 ChatGPT的文創產品設計思路
透過對比,可以發現ChatGPT僅能透過語言輸入和輸出來與使用者進行互動,並沒有實際的設計能力和手工創作能力。與之相比,人工設計師擁有更加專業的設計技巧和多樣化的設計思路,可以根據博物館藏品的特點和需求,設計更加創新和個人化的文創產品。
但是,NLP技術在分析文化資訊、提取文化元素和創意元素等任務上,仍可以為設計師提供一些靈感和建議,在文化元素的選取、數據過濾和概念構思方面,仍然需要人工來確保最終的產品品質和文化價值。因此,NLP技術在文創開發方面的套用仍需要結合人工智能與設計師的智慧,才能全面提高文創產品的創意度和滿意度。
6
文博科研場景
NLP技術為文博科研方面的資訊整合和研究提供了一種高效的方法。NLP技術有助於建立語意關系和知識圖譜,以更深入、更全面地研究文物、遺址和文化等資訊。透過智能分析和語意關聯技術,構建資訊的知識圖譜,將相關資訊視覺化呈現,更清晰展示資訊之間的關系。
此外,NLP技術可以自動辨識文物、遺址和文化資訊之間的聯系,並自動套用到文物研究領域。NLP技術可以將藏品的內容資訊之間相互的聯系和影響進行自動整合,提高研究人員對藏品理解的深度和精度,進一步豐富博物館文物研究領域的相關知識。
透過對NLP技術與人工研究員處理文獻資料的對比試驗。例如關於「二裏頭遺址與殷墟遺址的共同之處」這個話題(見圖7),人工研究員的回答為:兩個遺址都建設有道路,二裏頭遺址的規劃道路最寬處20米左右,相當於現代的4車道公路,發現了中國最早的車轍。從宮殿和道路建設看,兩個遺址繼承關系明顯。
結果顯示,NLP技術在分析資訊和提取重點等任務上,能夠取得相當不錯的穩定性、準確性和全面性,從而極大提升研究的效率。但是還是免不了出現一些錯誤,因此,只有借助人工的智慧進行處理和分析已有資料,以確保最終研究結果的嚴謹性和創新性。
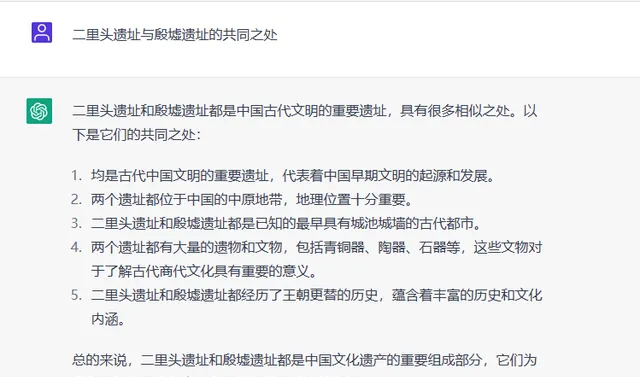
圖7 文獻資料對比回答
自然語言處理技術在博物館領域的未來與挑戰
1
與AIGC其他領域的融匯
AIGC(AI generated content)技術是指在人工智能技術的支持下,透過演算法生成各種形式的內容,如文字、影像、聲音等。它的實作依賴於深度學習、自然語言處理、電腦視覺、音訊處理等各種AI技術[6]。
例如,Runway公司推出的Gen-2,可以透過打字描述,制作出逼真的合成影片,任何你能想像到的東西都可以被創造出來。Stability AI公司推出的Stable Diffusion,提供將手繪草圖轉換為逼真而精致的數碼影像服務。
在不遠的未來,NLP技術和AIGC其他領域技術的結合可以為博物館帶來更多新的機遇和變革,尤其是在虛擬現實(VR)和增強現實(AR)等領域中,可以實作更加真實和沈浸式的體驗。
例如,結合NLP和影像生成技術,將自然語言文本轉換為影像的描述語言,然後影像生成技術可以利用這些描述生成與文本相關的影像。這種方法可以套用於許多領域,如自然場景的虛擬現實體驗、電影和遊戲中的富有想像力的特效等。最重要的是,這種技術可以套用在展覽策劃與設計中,為更高效便捷地貫徹策展人意圖發揮重要作用。
2
可能的技術挑戰和解決方案
NLP技術在博物館領域的套用也面臨著一些技術挑戰,這些挑戰可能會對技術進步和套用帶來一些限制性作用。主要包括以下方面。
1)專業性較強 。博物館領域的資訊量非常龐大,包括藏品的各種文獻資料、文物鑒定、文物科技分析、文物修復、文物考古發掘等等。這些資訊只有專業人士才能理解和解讀。因此,使用NLP技術在博物館領域進行文本處理和資訊抽取時,需要考慮領域知識本身的復雜性,以及領域專業性對模型訓練和演算法驗證的要求。需要將NLP相關技術與博物館的領域專業知識結合起來,才能夠提高抽取的準確度。
2)精度要求高 。博物館承擔著社會教育功能,在觀眾眼中,博物館代表了權威的解釋。因此,如果在博物館領域套用NLP技術,需要對NLP生成的數據質素和精度準確性進行嚴格的監控和驗證,確保所提供的資訊和解釋符合歷史事實和文化價值,並且有效避免錯誤的資訊對文物和社會造成負面影響。這也需要與業務領域專業人士進行緊密合作,明確數據處理的具體目標和要求,並逐步提高數據質素和準確性,以提高全域性和可靠性。
3)藏品數據安全 。由於博物館領域所涉及的部份數據可能涉及機密敏感性資訊,比如文物資訊、拍賣記錄、修復記錄、移交記錄等,因此在進行NLP技術套用的過程中需要註意數據安全性,並采取合適的安全措施,如加密、許可權設定、網絡防護等。此外,還要註重遵循相關法規和政策,確保文物數據的私密和安全。
為了應對這些技術挑戰,可能需要采取以下解決方案。
1)構建博物館領域知識庫
知識庫是一種儲存結構化或半結構化知識的數據庫,可以為NLP技術提供豐富而準確的領域知識。透過從博物館相關的文獻資料、網站、數據庫等來源中抽取實體(entity)、內容(attribute)和關系(relation),並進行清洗、整合、消歧等操作,可以構建一個包含博物館領域各類概念、例項、規則等知識的知識庫。知識庫可以幫助NLP技術進行語意理解(semantic understanding)、語意推理(semantic reasoning)和語意生成(semantic generation),提高NLP技術在博物館領域的效果。
2)利用深度學習方法最佳化模型訓練和演算法驗證
深度學習是一種基於多層神經網絡的機器學習方法,可以從大量數據中自動學習特征表示,提高模型泛化能力和魯棒性(robustness)。傳統的機器學習方法通常需要人工設計特征和使用先驗知識,這在博物館領域可能受到專業性和復雜性的限制。相比之下,深度學習法可以更好地捕捉博物館領域文本中的語意資訊和語境資訊,並進行有效的分類、抽取、生成等任務。例如,可以利用大規模語言模型(large language model,LLM)和微調(fine-tune)技術定向訓練博物館套用場景的NLP機器人。
3)采用多模態數據融合技術增強數據安全性
多模態數據融合是指將不同類別或來源的數據進行整合、分析和利用的過程,可以提高數據利用效率和價值。在博物館領域,除了文本數據外,還有影像、影片、音訊等多種類別的數據,這些數據可以相互補充、驗證和加密,提高數據安全性。例如,在對文物資訊進行抽取時,可以同時利用文本描述、影像特征、影片內容等多種資料來源進行交叉驗證,避免單一資料來源被篡改或泄露;在對文物資訊進行生成時,可以同時利用文本描述、影像特征、影片內容等多種資料來源進行加密處理,防止敏感資訊被竊取或破解。
3
NLP技術在博物館領域套用的限制因素
NLP技術在博物館領域套用方面,雖然具有很大的潛力,但也面臨一些特定的限制因素,主要包括計算資源和效能問題、數據管理和推薦效果、誤解和歧義問題等3個方面。
1.計算資源和效能問題
NLP系統在博物館自媒體或網站套用中,需要處理大量的文本和語音資訊,為使用者提供智能的問答、推薦、轉譯等服務。這些服務對計算資源的需求很高,如果面對龐大的存取量,可能會出現計算資源不足的問題,導致服務質素下降。為了解決這個問題,需要采用分布式計算(Distributed Computing)和低延遲服務(Low Latency Service)等技術,在最佳化演算法和模型參數的同時,提高模型的處理速度和效能,以提高NLP系統的可延伸性和處理效率。此外,在訓練過程中也需要較高的算力資源和穩定的數據中心環境等因素支持,否則可能會影響訓練效果和模型質素。
2.數據管理和推薦效果
博物館中的文物資訊涉及多個領域,如歷史、文化、藝術、科學等,每個領域又有不同的分類和內容。這些資訊構成了博物館的知識庫,是NLP系統數據管理和推薦效果的基礎。NLP系統需要能夠對這些資訊進行有效的組織、儲存、檢索和分析,以便為使用者提供最合適的資訊。同時,NLP系統也需要能夠根據使用者的興趣、偏好、需求等因素,進行個人化的推薦,以增加使用者的滿意度和參與度。例如,ChatGPT在博物館中主要套用於對話生成和問答系統等場景,利用大規模的對話數據集進行預訓練(Pre-training),然後根據不同的任務進行微調,以生成自然、流暢、有邏輯的對話。為了提高ChatGPT的表現效果,選擇合適的數據集規模、質素、分布等因素是關鍵。
3.誤解和歧義問題
一些文物資訊的含義和解釋會因為文化的不同、歷史的變遷等原因,存在誤解和歧義問題。這些問題會給NLP系統在理解和表達文物資訊時帶來困難和挑戰。NLP系統在處理這些問題時,需要更多的人工監督和互動溝通,以保證系統的理解和表達的準確性。同時,需要采用一些現有的技術來進行辨識和消除歧義,如多義詞(Polysemy)和語境分析(Context Analysis)等。
結論和展望
自然語言處理技術在博物館領域的套用具有廣泛的前景和套用場景,特別是ChatGPT的出現為博物館的資訊管理、文物解說和咨詢提供了強有力的工具支持。
本文分析了ChatGPT的技術原理和特點,並從實際套用的角度,論述了其在博物館中的多種套用場景,包括文物解說、自動化咨詢解答、資訊管理和研究等方面。針對不同的套用場景,在比較 ChatGPT與人工的表現差異時,可以發現ChatGPT在資訊處理方面具有極高的效率,在常識表述和提出策略方面具有優勢,但在準確性和事實闡釋方面明顯需要改進。
NLP技術在博物館領域中具有多方面的套用潛力和價值,可結合博物館的展覽講解員、客服、策展人、藏品管理人員、文創開發人員、文博科研人員等多種博物館服務角色,為提升博物館服務水平、提高社會文化素質和推動文化遺產的保護和傳承做出貢獻。
本文也提出了未來可能的研究方向和技術挑戰,如多模態資訊處理、開放領域問答系統、個人化推薦系統等。在未來的研究中,需要進一步開展交叉學科的研究和創新,將自然語言處理技術與其他技術結合起來,探索更多適合博物館套用的智能化技術,如影像處理、人工智能和大數據等。
此外,還需要考慮安全和私密等方面的因素,在保護使用者資訊保安的同時,提高博物館觀眾體驗和管理效率。總之,自然語言處理技術在博物館領域的套用是一個不斷創新和探索的領域,透過不斷探索和改進,將為博物館提供更加智能、便捷、高效的服務,為觀眾提供更為便捷的文化旅遊體驗。
原標題:自然語言處理技術在博物館領域的套用前景研究,以ChatGPT為例
作者:周鼎凱(二裏頭夏都遺址博物館)張楓林(浙江省博物館)丁治國(中國博物館協會)陳雨菲(故宮博物院)毛若寒(浙江大學)
1* 本文為2023年文化和旅遊部部級社科研究專案「元宇宙賦能博物館新業態發展的機制與模式研究」之階段性成果(專案批準號:23DY31) ↑
來源:【科學教育與博物館】











