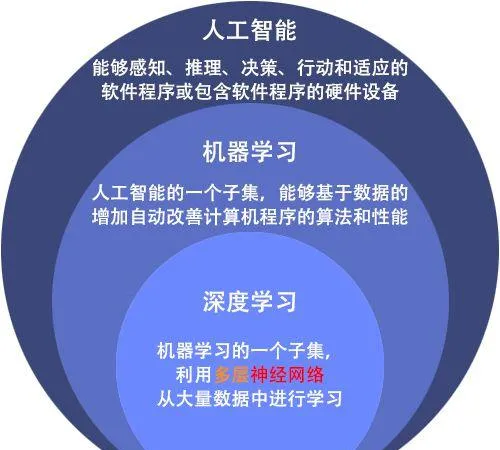
機器學習 (ML) 是人工智能的一個子集,是一個快速發展的領域,越來越多的制藥公司利用它。將ML方法整合到藥物開發過程中,幫助自動化重復的數據處理和分析任務。
機器學習——做出數據驅動的決策
ML 解決方案基於大數據建模 和分析。數據可以來自不同來源(例如,數據儲存庫 、內部實驗和出版物)並且可以在格式有所不同,這使得數據的聚合、儲存和準備具有挑戰性。

ML 訓練系統在沒有任何外部支持的情況下,自主地做出推理和決策。當系統從過去的經驗中學習和改進時,就會做出決定——系統從所提供的數據中學習,並解讀其中包含的相關模式。然後,透過模式辨識 和分析,系統交付「結果」,這可能是一個預測或分類。
機器學習任務大致可以分為三類:監督學習、非監督學習和順序學習。ML 中的數據可以是兩種類別——有標記的和無標記的。

常見的機器學習演算法 包括決策樹(decision tree)、 隨機森林 (random forest)、 支持向量機(support vector machine,SVM),k-最近鄰演算法 (k-nearest neighbor model) 和樸素貝葉斯(Naïve Bayes)演算法。
藥物研發中,ML方法可套用於以下幾個步驟:
機器學習已被用於藥物研發的各個領域,但是人工智能在新藥研發中的套用才剛剛起步,也面臨著諸多挑戰。在藥物研發領域,數據是人工智能的關鍵。因此作為一種資料探勘技術 ,人工智能模型依賴於大數據的積累,並不能無中生有。用來學習的數據很大程度上會影響模型的效能,因此模型是否有效往往取決於數據的質素。若是數據質素不高,即使使用可靠的演算法,也不會獲得良好的結果,反而會浪費大量的資源和時間。目前大多數預測模型來源於參差不齊的數據,因此如何獲得高質素的數據是人工智能面臨的一個主要問題。此外,如何學習訓練數據得到泛化能力強的模型也是人工智能的難點及熱點。
參考資料:
- https://www.technologynetworks.com/drug-discovery/articles/automating-drug-discovery-with-machine-learning-347763
- Hong Ming Chen, et al. The rise of deep learning in drug discovery, Drug Discovery Today.
- Stephenson, Natalie,Survey of Machine Learning Techniques in Drug Discovery, Current Drug Metabolism.
- Vamathevan, Jessica Clark, Dominic Czodrowski, Paul Dunham, Ian Ferran, Edgardo Lee, George Li, Bin Madabhushi, Anant Shah, Parantu Spitzer, Michaela Zhao, Shanrong, Applications of machine learning in drug discovery and development, Nature Reviews Drug Discovery, 2019
- 參考書:圖解機器學習
- https://blog.csdn.net/by4_Luminous/article/details/53341334
- 人工智能在藥物發現中的套用與挑戰










