首先和很多人的直觀感覺相反, 如今 PC DDR5 不是 64bit 單鍊結位寬, M1 系列也不是 128bit 位寬.
包括 DDR5 的 UDIMM 就從 64bit 單鍊結變成了 32bit 雙鍊結.
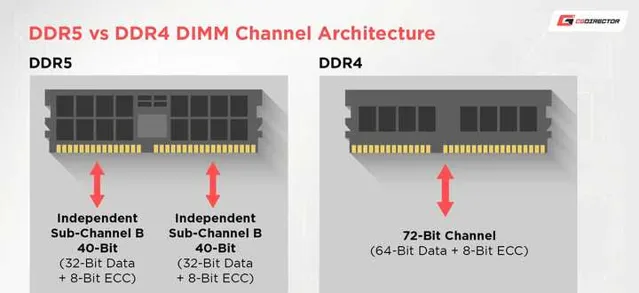
細心的朋友可以發現, 上面圖裏放的其實是邊帶 ECC DIMM.
而因為 DDR5 拆成兩條通道, 因此每個通道的 ECC bit 都要獨立開來, 而每個通道為了實作 ECC 加一顆 chip等於加 8bit.
因此 DDR5 ECC 的物理位寬是 de facto 更寬的.
但這樣做除了實作雙鍊結, 並不會帶來更好的 ECC 效果(仍然是1bit糾錯/2bit報告), 記憶體和 PHY 成本上升是紮紮實實的.
所以部份伺服器 DDR5 記憶體還是 72bit, 這樣少一顆顆粒, 大規模的場景下的降本可以想象有多少.

至於手機平台的話, 一個 LPDDR4/5 的 chip 實際上有兩個 16bit 通道, 因此能組成不同的組合. 不同的組合需要的引腳、效能、功耗都有所不同.
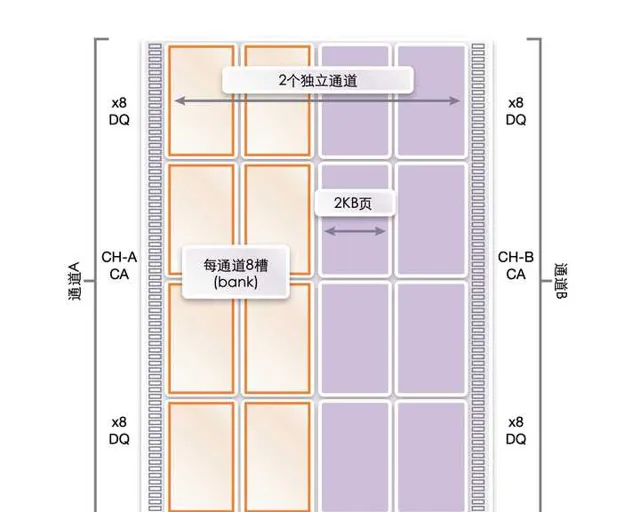
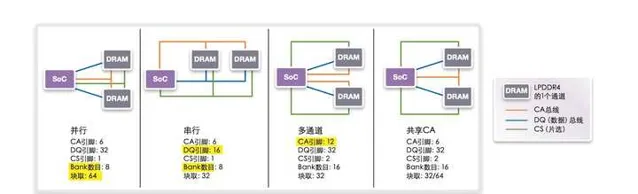
特別是流動平台有待機休眠的需求, 移動 SoC 上的記憶體布局通常都是不對稱多通道, 某一個通道會專門放待機會存取的內容(意味著這部份的頻寬其實是很低的), 其他部份休眠的時候就可以進入自重新整理.
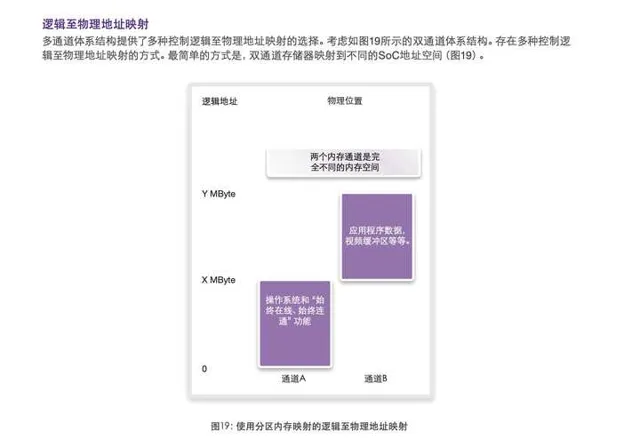
回到 PC 這邊的話, 回答為什麽不做更寬.
那很顯然, 如果芯片要做更寬的記憶體, 就意味著更大的記憶體控制器, which 吃面積.
同時需要更多的記憶體顆粒去滿足這些位寬, 對主機板布局有挑戰, 同時需要更厚的板層數量、更高質素的工藝實作更好的訊號完整性.
那就很容易碰到一個矛盾:
高位寬需要更多芯片和更高訊號完整性, 更高訊號完整性意味著記憶體越靠近芯片, 而芯片邊上一圈的空間是有限的, 那意味著犧牲容量.
以及, 更貴.
以及CPU通常延遲的重要性大於頻寬, 除非核心足夠多.
更不用說又不是人均 7950X 會碰到頻寬瓶頸, 用 R5/i5 的一堆, 而現在的 i5 本質上是 8+16 的 die 切出來的, 不可能為此繼續增加通道/改變主機板.
因此超過128bit位寬的 CPU 只有在 HEDT(如Threadripper, 以前的 X 系主機板+Extreme) 平台才能見到, 其實就是伺服器下放.
那有的人說, 筆記本上核顯卡需要頻寬, 為什麽 x86 平台還是 128bit 封頂.
這就要提到剛才說的, 記憶體控制器+PHY 要吃面積.
而通常 128bit 的移動 SoC 還要兼任嵌入式 SoC, 要上 ECC 記憶體, 然後起碼得同時相容 DDR5/LPDDR5(以前是相容 DDR4/LPDDR4X, Intel 得相容 LPDDR5/DDR4/DDR5).
仔細看的話可以發現 AMD SoC PHY 部份有些類似 IOD 上的 2x72bit 設計, 但實際再放大看, 似乎 LPDDR4/DDR4 的 PHY 分開的, DDR4 部份是 (4+5)x16bit, 而 LPDDR4 是 8*16bit)
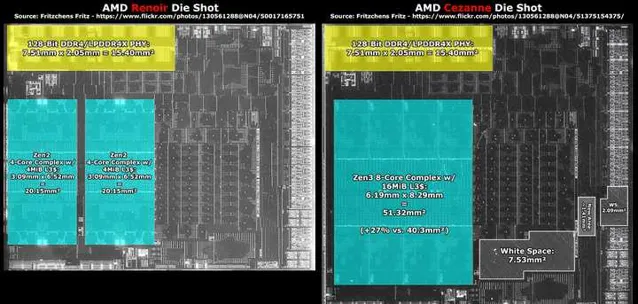
對於筆記本的產品經理來說, 不同的產品線可能會用不同的記憶體, 因此 SoC 就有必要同時相容多種記憶體(雖然不同記憶體類別的 SoC 會用不同的封裝, 比如 fp7 和 fp7r2, 以及主機板設計不相容)
當然這麽做的代價, 就是單位面積的能做的頻寬會更低.
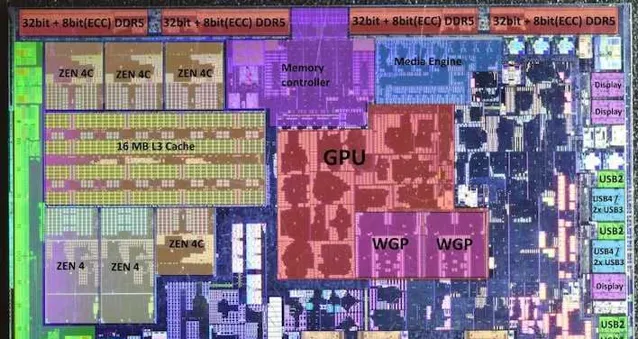
因此如果要降低成本的話, 就不能盲目支持很多種類的記憶體, 這就是為什麽 AM5 平台只支持 DDR5, 而 AMD 給 Chromebook NetBook用的 Mendocino 只支持 2x32bit LPDDR5, 就是為了省錢(當然 LPDDR5 因為手機的出貨量, 496ball Mobile LPDDR5 模組其實挺便宜的, 有不少山寨筆記本用了手機記憶體上 12-24GB, 甚至是讓 LPDDR5X 降級執行在 LPDDR5 上)

包括大家熟知的 Steam Deck 的 SoC 應該也只支持 LPDDR5, 新款用了和 M2 類似的 64bit 顆粒. 而且可以註意到尺寸顯著縮小.

另外一個問題就是電氣完整性.
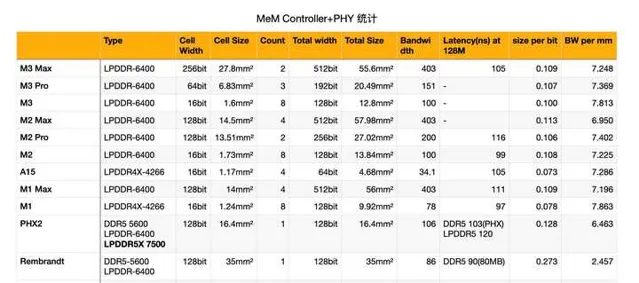
就如下圖的統計, 7nm 的 CZE 記憶體控制器的密度僅為 3.7bit/mm2, 而 M1 只支持 LPDDR4X 的情況下為 7.8. 雖然說 M1 是 5nm 工藝不是很公平, 但是可以看 Rembarndt 的 6nm 上了 DDR5/LPDDR5 之後, 記憶體控制器的面積效率相比 CZE 進一步倒車, 密度遠遠落後於 M2.
同樣, M2 相比 M1 的記憶體控制器面積效率也是倒車的, 因為 LPDDR5 的記憶體控制器更復雜. A15-A16 也體現了這種變化.
之所以 AMD 這邊記憶體控制器密度這麽低, 除了剛才提到的相容的種類多(特別是 ECC 需要多加 DQ), 工藝老(當然先進工藝對 PHY/SRAM 密度幫助不是很大, 這就是為什麽 RDNA3 用特殊的 6nm 做了 MCD), 更重要的原因是:
為了實作更高的電氣完整性, PHY 的驅動能力有了很大加強.
這就是為什麽 RMB 能實作 10 層板上 6400 記憶體, 而 Intel 這邊 12 代只能透過 HDI 上 6000 頻率, 但代價就是記憶體 PHY 面積. 但 RMB 的記憶體控制器密度低的感人, 只有蘋果主流水平的 1/3.
PHX 上倒是上了 AMD 自研的 IP, 可以發現每平方毫米位寬做到了 6.5, 算是比較可以了.
但是就這個水平的話, 做 128bit 可能還好, 但要堆到 256bit 的話, 那在 4nm 下 PHY 的記憶體控制器面積就要高達 33mm2.
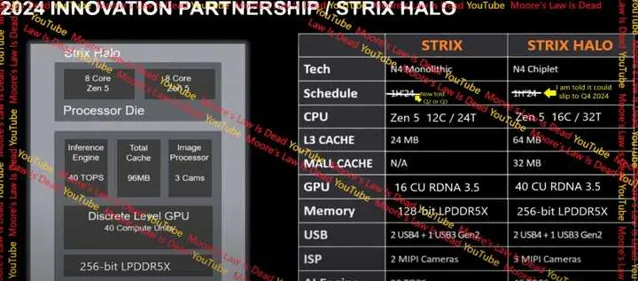
因此 256bit 位寬 Strix Halo 將確定只支持 LPDDR5/5X 記憶體.
包括 AGX Orin 也做了 64GB/256bit 位寬, 盛惠 2000 刀. 讓老黃教育下在座什麽叫黃金記憶體.
所以, MSDT/LP PC 做超過 128bit 只是時間問題, 且服務的還是 GPU.
接著再回到這張圖
可以發現, 蘋果單位面積實作的位寬一直是領先的. 這是一定程度上是因為 MoP 封裝帶來了更好的電氣完整性, 降低了驅動力的要求.
在同代之間, Max 的記憶體控制器的密度都是相對偏低的.
而 M2 Pro 的記憶體控制器密度反倒是反超了 M2, 畢竟同樣的 64bit 顆粒, 卻只需要 32GB 封頂, 而 M2 需要支持 24GB 的版本.

這種變化應該還是記憶體PHY驅動力導致的. 因為 Max/Ultra 要支持更大的記憶體, 比如 M3 Max 上史無前例的 128bit 寬單顆粒 32GB, 應該是 A17 Pro 的同款 16gb DUV D1beta die. 要知道這個 package 裏面有 16 片 chip(2x8層), 相對需要高一些的驅動力.
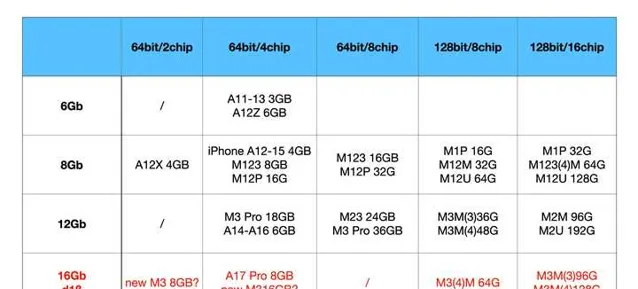
另外一件大家知道的事情就是, M3 Pro 位寬從 256 縮水 192.
當然我不指望那些一天到晚口嗨的噴子有買 M3 Pro MBP 的念頭.
但從技術工程的角度看, M3 Pro 縮頻寬本質上是 M3 Pro 芯片獨立設計的結果, 使得芯片的面積相較 M2 Pro 大振幅下降, 只不過效能提升振幅不大, 但換來的是更好的能效, 以及小得多的封裝.
所以就有傳聞說 M3 Pro 會登陸 14 寸 iPad Pro. 我個人覺得上 15 寸 MacBook Air 也只是時間問題, 畢竟功耗低了, 但會不會上風扇就不好說.











