「國際象棋電腦程式想要在人類大師級(Master)選手中贏得一場比賽的唯一可能,是等到這位大師喝得爛醉、同時在下著50盤棋、並且犯下一個他一年才可能犯一次的錯誤時。」
上面這段話是1976年一位高級國際象棋大師(Senior Master)對當時的國際象棋程式所作出的評價。(這種說法是不是聽起來很耳熟?20年前,人們差不多也是這麽評價圍棋電腦程式的。)
但在接下來的20年中,隨著電腦演算法和硬件的不斷升級,電腦程式在與人類選手的比賽中戰績越來越好,國際象棋大師們對電腦程式的評價也在一次次改變:
「電腦永遠也不可能擊敗特級大師(Grand Master)。」
「電腦永遠也不可能擊敗 實力強勁 的特級大師。」
「也許電腦可以擊敗實力強勁的特級大師,但它永遠也無法擊敗國際象棋世界冠軍卡斯巴羅夫。」
1996年2月,世界冠軍卡斯巴羅夫作為人類棋手的最後一道防線在美國費城迎戰IBM的「深藍」電腦,雙方一共進行了六局的較量。在比賽的第一天,深藍在第一局中擊敗了卡斯巴羅夫,這也是電腦第一次在標準比賽規則下戰勝世界冠軍。
在第一局比賽結束的當晚,卡斯巴羅夫和他的助手在費城的街道上一直散步到深夜。期間,心煩意亂的卡斯巴羅夫曾經問他的助手「如果那玩意兒是不可戰勝的,那怎麽辦?」
不過,在次日進行的第二局比賽中,卡斯巴羅夫扳回了一局。在比賽結束後的采訪中,他對深藍做出了很高的評價:「在某些局面中,它(深藍)看得非常深,就像上帝在下棋。」
在隨後的四局比賽中,卡斯巴羅夫兩勝兩平,最終以4:2的總比分擊敗了深藍,捍衛了人類象棋大師的尊嚴。雖然深藍失敗了,但4:2的比分讓深藍的制造者們心裏很清楚,用電腦程式戰勝世界排名第一的人類棋手將只是一個時間問題了。
要想明白在這20年內人們是如何將國際象棋程式的水平提高到足以跟世界冠軍較量的,我們得先來看一下電腦程式下棋的原理。
電腦下棋的基本原理其實一點都不復雜,在這裏我們用簡單的井字棋(Tic-Tac-Toe)來舉例說明:

井字棋是一種非常簡單的二人棋類遊戲。棋盤上一共有九個格子,對戰的雙方依次在格子中畫下圓圈或者叉叉。當一方的三個棋子以橫、豎或對角的方式連成一條線時即為勝利。
想要讓電腦下井字棋,最簡單的方法就是讓它對所有可能的走法逐個推演一遍。比如說對於井字棋來說,第一步一共有三種走法,分別是下在角落上、邊上和棋盤中間。對於這三種走法中的每一種,對手又會各有數種應對走法,從而形成更多數量的局面。電腦所要做的就是一步步計算下去,把每一種局面都推演一遍:

上面這張圖片中顯示了電腦推演過程的前兩步。其中叉叉選手一共有三種開局,分別顯示在圖片的第二行中。圖片的第三行中顯示的是圈圈選手的應對走法。對於叉叉畫在在中間的開局,圈圈選手一共有兩種應對方法。對於另外兩種開局,圈圈選手各有五種對應的走法。
這種推演每多推演一步,我們得到的不同局面就會越來越多。上面圖片中只推演了兩步,或者說兩「層」(Ply)。由於井字棋最多也只能下上9步,並且每步的變化都十分有限。從第一步下到最後一步,井字棋一共只有26830種不同的棋局。電腦可以很容易地將每一種情況都推演到底並記錄下輸贏結果,下面的圖片是一個簡化的示意圖:

在上面的圖片裏,最後一行中藍點代表的是選手一獲勝的結局,紅點代表的是選手二獲勝的結果。對於可以直接「看穿」每一步棋的最終結果的電腦來說,在和人類下棋時只要盡量選擇自己顏色獲勝的分支去下就可以了。如果雙方都按照最優方案去下,將永遠是和棋的結果。
讓電腦下國際象棋的基本思路其實和下井字棋是一樣的。但其中一個重要的區別是國際象棋的變化要比井字棋多得多。在國際象棋的中局階段,平均每一步都有30-40種不同的選擇,這意味著電腦往下推演一個回合(雙方各走一步)就要計算一千種可能的情況,並且每多推演一個回合計算量就會增加一千倍。推演兩個回合就要計算一百萬種情況,四個回合就是一萬億種,八個回合就是一億億億種……
由於計算量隨著推演回合數的增多呈指數式的增長,電腦是無法像面對井字棋那樣直接計算到最後一步的。人們只好做出一定程度的妥協,讓電腦在推演到一定數量的回合數就停止計算。由於無法直接推演到分出勝負,所以人們又在電腦程式中增加了評分系統,好讓電腦從千千萬萬個推演結果中選出最優的一個。例如人們可以在評分系統中設定皇後=9分、車=5分、象=5分、兵=1分等等,然後再根據棋子的不同位置對得分進行修正。電腦程式會按照這個評分系統對推演出的每一個局面進行評分。
接下來要做的事情顯然是根據推演結果來選擇下一步要走的棋了。假設電腦剛剛往下推演了兩個回合,一共產生了一百萬個可能的局面,並對它們一一進行了評分。我們現在是不是應該直接找出評分最高的那個局面,然後向上倒推出我們下一步應該要走的棋呢?
當然不是。
別忘了,在這兩個回合一共四步棋中,只有兩步是由電腦程式這一方來走的,還有兩步是由對手來走的。對手走出的這兩步棋一定是會盡力讓電腦一方的評分降低的,所以電腦計算出的最優局面很可能只是存在於理論上而已,對手才不會乖乖地配合你走出這樣一個局面。
在計算出N個回合後的所有局面後,我們需要用到一個特殊的演算法來確定下一步要走的棋。下面的圖片中是一個非常清晰的簡化範例:

在上面的例子中,電腦一共進行了兩個回合共四步棋的推演,得到了9個可能的局面,也就是第4行中的9個圓圈。圓圈中的數碼是電腦對於這個局面的評分,正無窮大為電腦獲勝,負無窮大為對手獲勝。
在得到第4行的九個推演結果並對它們進行評分後,我們需要根據這個評分對第3行的局面評分(圖片中紅色箭頭)。在這個過程中,我們需要把第3行中每個方框的評分值 取為它下面所有結局評分中的最小值 。這很容易理解,因為從第三行局面變為第四行局面的 這一步是由對手來走的 。對手當然會選擇讓我們的分值最小化的走法。所以第3行最左邊的方框被賦予了10的評分,因為對手不可能在這個局面下配合你走出下一步讓你取勝的棋,它下面的那個正無窮大局面也是根本不可能發生。
在對第3行完成評分之後,我們接下來要根據第3行的評分對2行進行評分。請註意從第2行局面變為第3行局面的 這一步是由我方來走的 ,所以第2行中的每個圓圈的評分值 取為它下面所有評分中的最大值 。按照這種方法依次類推,我們可以得到對第1行兩種走法的評分,分別是-10分和-7分。這兩個評分的意義是,如果我們選擇左邊的走法,四步之後得到的最好結果將是-10分,如果選擇右邊的,四步之後得到的最好結果將是-7分。根據這個推演結果,我們當然選擇右邊的走法(圖中藍色箭頭)。
由於這個演算法對於每一行的評分輪流進行最小和最大取值,所以被叫做Minimax演算法(Minimax Algorithm)。
有了
搜尋系統
和
評分系統
這兩個最核心的模組後,電腦就可以開始下象棋了。電腦用兩個步驟來決定自己的下一步棋:
雖然可以下棋了,但這時的電腦搜尋效率很低,完全無望戰勝人類的大師級選手。
為了讓電腦在相同的時間內達到更大的搜尋深度,人們又想出很多方法來改進象棋程式的搜尋系統。例如用剪枝演算法(alpha-beta pruning)來切除那些顯然不是最優解的路徑以節省計算資源,或者把一些搜尋結果儲存起來(transpostion table)供以後呼叫……等等等等。
除了改進演算法以外,另一個更加粗暴的方法就是直接提高電腦的運算速度。同樣的一個象棋程式在普通電腦上執行時可能只相當於人類 class C的水平,但放到超級電腦上執行時立刻會上升到人類 class A的水平( class A選手對 class C選手有90%以上的勝率)。這是因為超級電腦可以使得象棋程式在同樣的時間內完成更大的搜尋深度,即「看到」更多回合後的情況。
電腦象棋程式以上面的兩種方式發展了20年後,實力已經越來越接近人類頂尖棋手的水平。等到開發深藍的時候,IBM團隊中技術人員的象棋水平已經根本無法跟上深藍的水平了。於是IBM又特意雇了一位國際象棋特級大師Joel Benjamin,讓他來與深藍進行對戰練習,並對深藍的參數進行修正。
在IBM團隊研制深藍之前,其實電腦已經在一些方面顯示出了超越人類的勢頭。一個叫做Ken Tompson的人在80年代利用電腦對國際象棋的殘局進行了研究。對於雙方棋子總數少於5個的殘局,由於變化相對較少,Ken幹脆用電腦對這些殘局進行了暴力破解(即把雙方所有可能的走法窮盡一遍)。
在得到結果後,他驚訝地發現,對於一些人類長期以來認為是和棋的殘局,電腦竟然找到了需要走50步以上的獲勝方法。在這些殘局中取勝的步驟中包括一些看起來完全沒有任何意義的走法,這已經徹底超越了人類在國際象棋上的思考能力,更不要提後來電腦又找到了一些需要走500步以上才能取勝的殘局。
2005年,人們用電腦暴力破解了雙方棋子總數不超過6個的所有殘局,生成的數據大小有1200G。2012年,人們又暴力破解了雙方棋子總數不超過7個的所有殘局,生成的數據大小為140000G。
用Ken的話來說,這意味著現在當人類和電腦對弈到雙方棋子總數不超過7個的時候,人類等於是和上帝在下棋。
在科技人員和象棋特級大師的共同努力下,1996年的深藍雖然輸給了卡斯巴羅夫,但已經具有人類頂尖棋手的實力。僅僅一年後,經過升級後的深藍就又向卡斯巴羅夫發出了第二次挑戰。升級後的深藍可以評估出6個回合內的所有走法,對於部份重要的路徑則可以計算到20個回合以後。
在雙方1997年的第二次交鋒中,深藍以3.5:2.5的比分戰勝了人類的世界冠軍卡斯巴羅夫,創造了歷史。

上面這張圖片是卡斯巴羅夫在1997年對陣深藍的最後一場比賽時的情景。
電腦象棋程式第一次戰勝人類世界冠軍在1997年的中國也是一個大新聞,各大中文媒體都進行了報道,印象中答主就是那個時候才第一次聽說IBM這家公司。但奇怪的是,在當時很多中文媒體的報道中,講完這條新聞後都會話鋒一轉強調說雖然電腦在國際象棋上戰勝了人類,但下圍棋是絕對下不贏人類的。文章的最後通常會附上一些論述得意洋洋地證明中國人發明圍棋比國際象棋要復雜得多。答主當時正在讀中學,思想有一點中二,對當時的報道非常失望,覺得為什麽沒有一篇報道鼓勵中國人搶在西方人之前先攻克這個難題,為什麽這些人只盯著幾千年前的歷史而不想著去創造新的歷史。
當然,讓電腦下圍棋確實要比下國際象棋困難得多。前面講過的國際象棋中兩個最核心的模組「搜尋系統」和「評分系統」在面對圍棋時都會遇到很大的挑戰。
這些困難當然每個人都知道,只不過一些人看到這些困難就直接放棄了,而另外一些人會努力找到各種方法來克服這些困難。
讓李世石和Alphago之間的圍棋人機大戰成為現實的,正是這群「另外一些人」。
鑒於套用在象棋程式上的演算法無法被直接使用在圍棋程式上,開發圍棋程式的人又想出了一些新的辦法,例如蒙地卡羅樹搜尋(Monte Carlo Tree Search)。大家不要被這個逼格滿滿的名詞嚇到,蒙地卡羅是世界三大賭城之一,所以「蒙地卡羅」這個詞在這裏就是隨機的意思。
在蒙地卡羅方法中,圍棋程式在下棋時會首先判斷出下一步可能的走法,假設有A和B兩種。接下來,對於A和B兩種走法,程式會分別按照 隨機的 走法繼續把這盤棋一直下到底,然後記錄輸贏結果。
假設程式在A之後按照隨機的走法模擬下完了100局棋,贏了50盤。然後程式又在B之後按照隨機的走法模擬下完了100局棋,贏了60盤。根據這個結果程式會得出結論: 雖然都是隨機亂走,在走了B之後亂走的勝率比走了A之後亂走的勝率要高那麽一點點,那麽想必B這步棋是比A要好那麽一點點的。
這種演算法乍一看有點詭異,但它很好地避開了前面提到的電腦程式下圍棋中最大的兩個困難。第一,這種方法不需要對某一層的可能下法進行窮盡計算,而只是隨機選取一些路徑進行模擬,因此大大減少了計算量。第二,這種演算法在模擬中會直接將整盤棋下到最後分出勝負,然後再根據勝率來判斷一步棋的優劣,因此也不需要設計任何評分系統對未結束的局面進行評分。
雖然這種演算法可以繞開圍棋程式中一些難以克服的困難,但一開始人們用這種演算法編制的圍棋程式水平也很爛,只能可憐兮兮地在9X9的棋盤上下棋。但隨著技術人員的耐心改進,圍棋程式的水平也一直在緩慢地提高。
2010年,圍棋程式MogoTW與職業五段選手Catalin Taranu在全尺寸棋盤上對陣,在受讓7子的情況下依然落敗。
2012年和2013年,圍棋程式Zen和Crazy Stone分別在受讓4子的情況下戰勝了職業九段選手。
2015年10月,谷歌的Alphago又把圍棋程式提高到了一個新的高度,在沒有讓子的情況下以5:0的比分戰勝了職業二段選手。
從網上幾篇非常有限的報道來看(Nature的那篇文章我看不到,看到估計也看不懂),谷歌的Alphago的大概工作原理是這樣的(下面的內容來自於這篇報道How AlphaGo Works):
在Alphago中有兩個模組,第一個是「落子選擇器」。谷歌的在落子選擇器中輸入了上百萬人類對弈的棋譜供它學習。在完成學習後,當你往這個落子選擇器中輸入一個新的局面時,它可以預測人類棋手在這種情況下會在哪個位置落子。
下面這張圖片顯示的就是這個模組對於下一步落子位置的預測,以概率表示:
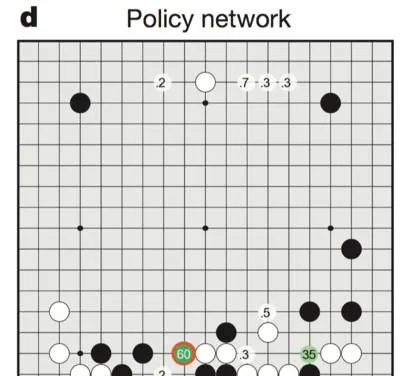
在這裏請大家註意這個落子選擇器除了「猜測」下一步棋的位置之外,並不會做其他的事情。但是如果有兩個版本的落子選擇器來交替猜測黑白方的下一步棋時,它們之間就可以進行對戰了,然後再根據的勝負結果修正自己的預測。這也就是很多報道裏講到的Alphago可以透過與自己對弈不斷提高水平。
Alphago中的另一個模組是「棋局評估器」。根據Alphago自己和自己對弈的無數棋局的結果,谷歌的工程師可以訓練「棋局評估器」對一個局面的黑白勝面進行評估。換句話說,透過學習海量的棋局,谷歌開發出了一個相對靠譜的圍棋的評分系統。
有了上面的兩個模組,Alphago在對戰中透過一下步驟來決定下一步棋的位置:
在谷歌釋出的影片中,谷歌的工程師在接收采訪時表示對三月份的比賽很有信心。他表示李世石是一名很強大的對手,但是人類與電腦相比也有其自身的弱點(還記得前面講過的電腦發現的需要走500步以上才能取勝的國際象棋殘局嗎?)。在影片的最後,這位研發人員說:「李世石每年可以下多少盤棋作為練習?也許一千盤?Alphago可以下一百萬盤……每天。」
==========賽後更新==========
3月9日,第一場比賽結束,Alphago 1:0 領先。
各方反應:
Deepmind的CEO Demis Hassabis發表了推文:「Alphago贏了!!!我們登月成功了。為我們的團隊感到自豪!當然李世石也棒棒噠~~」
李世石在賽後接受采訪時說:「我很吃驚。我從來沒有想過我會輸……即使在落後的時候。我沒想到它能下出這麽精彩的棋……我聽說Demis Hassabis將我視作值得尊敬的棋手。我同樣也非常尊重制作出這個程式的人們。」
最後,李世石表示他十分期待接下來的比賽。
3月10日,第二場比賽結束,Alphago 2:0 領先。
比賽的懸念由賽前的「Alphago是否能至少贏下一局」迅速變成了「李世石是否能至少贏下一局」。
3月12日,第三場比賽結束,Alphago 3:0 領先。
在2016年前,人們說:
「圍棋是一種極其復雜的遊戲,它的變化比宇宙中的原子數還多,所以電腦是不可能贏過人類的。」
在2016年之後,人們可能說:
「圍棋是一種極其復雜的遊戲,它的變化比宇宙中的原子數還多,所以人類是不可能贏過電腦的。」
3月13日,第四場比賽結束,李世石奮力扳回一局,Alphago 3:1 領先。
今天李世石九段成功逆襲,戰勝了Alphago!今天的比賽可謂是這場人機大戰之中的莫斯科保衛戰,打破了Alphago不可戰勝的神話。
==========分割線==========
今天(3月9日)在微博上看到不少人說Alphago贏了李世石之後就會繼續挑戰擊敗了李世石的中國棋手柯潔。我認為這幾乎肯定不會發生。如果Alphago真的在後面的比賽中擊敗了李世石,谷歌很有可能會對繼續開發任何圍棋程式徹底失去興趣,因為他們已經在全世界的鎂光燈下證明了自己的程式可以擊敗人類頂尖高手,也證明了自己的技術是全世界最牛逼的。
卡斯巴羅夫1997年輸給深藍之後,曾經提出過要復賽,但IBM根本就沒有興趣。
柯潔可能永遠都沒有機會了。
最後,歡迎大家關註我的微信公眾號「十一點半講歷史」,閱讀更多原創文章。











