不知道你想問的「理解」是怎樣的理解,也不知道你的「文科背景」是個什麽水平……我就把分幀前前後後的事情都說一下好了。
語音訊號處理常常要達到的一個目標,就是弄清楚語音中 各個頻率成分的分布 。做這件事情的數學工具是 傅立葉變換 。傅立葉變換要求輸入訊號是 平穩 的,當然不平穩的訊號你想硬做也可以,但得到的結果就沒有什麽意義了。而語音在宏觀上來看是不平穩的——你的嘴巴一動,訊號的特征就變了。但是從微觀上來看,在比較短的時間內,嘴巴動得是沒有那麽快的,語音訊號就可以看成平穩的,就可以截取出來做傅立葉變換了。這就是為什麽語音訊號要分幀處理,截取出來的一小段訊號就叫一「幀」。
如下圖:這段語音的前三分之一和後三分之二明顯不一樣,所以整體來看語音訊號不平穩。紅框框出來的部份是一幀,在這一幀內部的訊號可以看成平穩的。

那麽一幀有多長呢?幀長要滿足兩個條件:
這樣,我們就知道了幀長一般取為 20 ~ 50 毫秒,20、25、30、40、50 都是比較常用的數值,甚至還有人用 32(在程式猿眼裏,這是一個比較「整」的數碼)。
取出來的一幀訊號,在做傅立葉變換之前,要先進行「 加窗 」的操作,即與一個「窗函數」相乘,如下圖所示:

加窗的目的是讓一幀訊號的振幅在兩端 漸變 到 0。漸變對傅立葉變換有好處,可以讓頻譜上的各個峰更細,不容易糊在一起(術語叫做 減輕頻譜泄漏 ),具體的數學就不講了。
加窗的代價是一幀訊號兩端的部份被削弱了,沒有像中央的部份那樣得到重視。彌補的辦法是,幀不要背靠背地截取,而是相互重疊一部份。相鄰兩幀的起始位置的時間差叫做 幀移 ,常見的取法是取為 幀長的一半 ,或者固定取為 10 毫秒 。
對一幀訊號做傅立葉變換,得到的結果叫 頻譜 ,它就是下圖中的藍線:
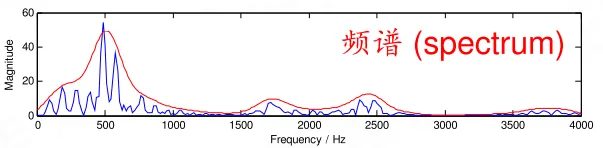
圖中的橫軸是頻率,縱軸是振幅。頻譜上就能看出這幀語音在 480 和 580 赫茲附近的能量比較強。語音的頻譜,常常呈現出「精細結構」和「包絡」兩種模式。「精細結構」就是藍線上的一個個小峰,它們在橫軸上的間距就是 基頻 ,它體現了語音的 音高 ——峰越稀疏,基頻越高,音高也越高。「包絡」則是連線這些小峰峰頂的平滑曲線(紅線),它代表了口型,即發的是哪個音。包絡上的峰叫 共振峰 ,圖中能看出四個,分別在 500、1700、2450、3800 赫茲附近。有經驗的人,根據共振峰的位置,就能看出發的是什麽音。
對每一幀訊號都做這樣的傅立葉變換,就可以知道音高和口型隨時間的變化情況,也就能辨識出一句話說的是什麽了。










