大家好,小鵬汽車又來回答了。
首先先回答一下RL在自動駕駛領域目前的套用現狀:
先說一下行業內大多數主機廠在自動駕駛領域對於RL的套用:
由於強化學習是一種致力於實作通用智能解決復雜問題的方式,其適用於解決時序問題,而自動駕駛作為典型的「工業人工智能」,過程中包含感知、決策、控制三大環節,需要考慮各種極端工況與場景;
其中感知過程中環境要素實在太復雜,且駕駛任務靈活多變,非時序問題很多,RL在其中很難發揮主要作用,更多是DL的天下,如常用的YOLO及其變式等;只有在決策層面,Model Based RL與Rule based相互配合,其中基於規則的構建來應付大部份常見駕駛場景,但需要不斷設計更新;RL來解決規則庫內不適用的極端場景與問題。這也是目前行業內很多家主機廠都很「默契」采用的L3-L4演算法架構。
而對於一些致力於L4解決方案的科技公司來說:
更多是選擇深度強化學習DRL方式,也就是將深度學習DL的感知能力和強化學習RL的決策能力相結合,可以直接根據輸入的資訊進行控制,是一種更接近人類思維方式的人工智能方法,也是更具有潛力的成熟L4級別解決方案。
傳統RL的核心在於根據環境狀態序列,找到一套最優控制策略,以實作最大累計期望獎勵。也就是不斷在環境中試錯,不斷改進,下圖對於RL研究者們應該非常熟悉了,小鵬在此不再贅述基本原理。
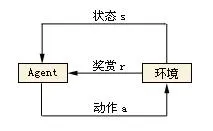
但傳統的RL,在解決自動駕駛問題上面臨一些通用的瓶頸,其根源是「扁平」方法的不適用 。 SF(Sensor Fusion)與行為規劃的輸出是多維度求解問題,而當多維度空間「扁平」後,形成的是一個平坦但非常龐大的狀態空間,使得原有trial and error的路徑非常曲折漫長,反向傳播時,獎勵訊號過於微弱,此時演算法工程師調參的過程必定是煎熬而且「 禿 」兀。
延伸出具體影響如下:
1.樣本效率:尤其是數據生成效率、L4級別專註於極端場景處理,無疑將消耗很多等待時間
2.擴充套件:RL方法解決長序或非常復雜的動作及狀態空間問題將導致維數災難。
3.泛化:解決當前問題獲得最大的累積獎勵的策略,反而會由於過度專一,無法平移解決其他問題
4.抽象:時間與空間的狀態抽象由於SF的幫助,此類問題在自動駕駛中難度有所降低。
為了解決以上問題,深度強化學習(DRL)由然而生。
其將深度學習套用到期望獎勵趨勢預測中,一方面有助於與CV方案的結合可以實作end 2 end方案,另外也可以在未知環境下更好預測規律,並減小期望反饋誤差。
2013年DQN 1在NIPS上由DeepMind 發表1,後續又在Nature 2015提出改進版本,此方式是DRL的起始,其核心思想為以下三點:
- 透過Q-Learning使用reward來構造標簽;
- experience replay(經驗池)的方法來解決相關性及非靜態分布問題
- 使用一個CNN(MainNet)產生當前Q值,使用另外一個CNN(Target)產生Target Q值
2015版本演算法偽代碼如下:

DQN是一種強大的基線智能體,作為初版嘗試,在遊戲領域實作了很好的通用性。但在工程實踐領域,存在無法進行連續動作控制,無法處理長時間記憶(後續加入LSTM改進)和CNN需要精確調參的問題。
後續Deep Mind將A3C(Asynchronous Advantage Actor Critic)和 OpenAI 的同步式變體 A2C 也套用了DQN中(論文連結:https:// arxiv.org/abs/1802.0156 1 ),但仍然沒有很好解決以上問題。
DRL中,使用了深度神經網絡的分層強化學習(HRL)目前備受關註,其致力於將一個復雜的強化學習問題分解成幾個子問題並分別解決,並想相信可以取得比直接解決整個問題更好的效果。理論上核心思想:以HAM、隱藏學習(封建學習),MAXQ為靈感,實作長期信度分配、結構化搜尋與遷移學習,從而使得減少問題搜尋的復雜性;但在自動駕駛實踐中HRL也存在引入額外的超參數,增加了更新層次代理的級別所產生的非平穩性等問題。
最近幾年又出現了幾個基於DRL HRL想法啟發,並在專案實踐中取得了不錯的效果,典型有以下幾篇:
H-DQN [1]
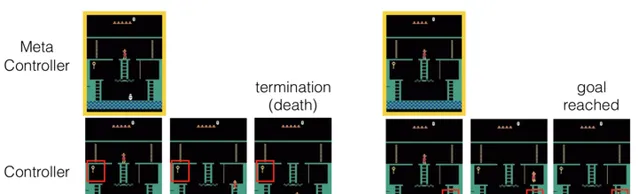
「我們提出分層DQN(h-DQN)的框架,是一個結合分層值函數,在不同的時域尺度運作,有內部激勵的深度強化學習。在最高層的值函數透過內部目標學習策略,較低層的函數透過原子動作學習策略來滿足目標。h-DQN允許靈活的目標指定,例如實體和關系的函數。這為復雜環境的探索提供了一個高效的空間。
我們透過兩個反饋稀疏、延遲的問題證明我們的方法:(1)一種復雜的離散隨機決策過程,(2)雅達利經典遊戲「蒙特蘇馬的復仇」。
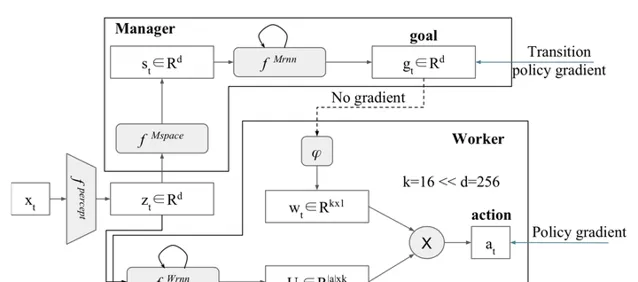
分層強化學習FeUdal網絡(FuN)
FeUdal網絡提出了模組化的結構。受到Hinton的封建強化學習思想的啟發,系統的管理者選擇一個方向進入隱狀態空間,而工人學會透過環境中的動作來實作這個方向。這意味著FuN代表子目標作為隱狀態空間中的方向,然後轉化為有意義的行為原語。論文介紹了一種方法,能獲得更好的長期信度分配,使記憶更易於追蹤。
FuN結構:
H-DRLN [2]

論文主要思想:我們提出了一個終身學習系統,它能將知識從一個任務遷移或重新利用到另一個,同時有效地保留先前學到的知識庫。該系統透過學習可重用的技能來遷移知識,完成Minecraft中的任務。
這些可重用的技能,我們稱之為深度技能網絡,隨後透過兩種技術:(1)深度技能陣列,(2)技能蒸餾,整合到我們提出的分層深度強化學習網絡(H-DRLN)的結構中學習技能。
DDPG(Deep Deterministic Policy Gradient)
這是由DeepMind的Lillicrap 等於 2016 年提出,其核心思想是采用摺積神經網絡作為策略函數μ 和 Q 函數的模擬,即策略網絡和 Q 網絡;然後使用深度學習的方法來訓練上述神經網絡。
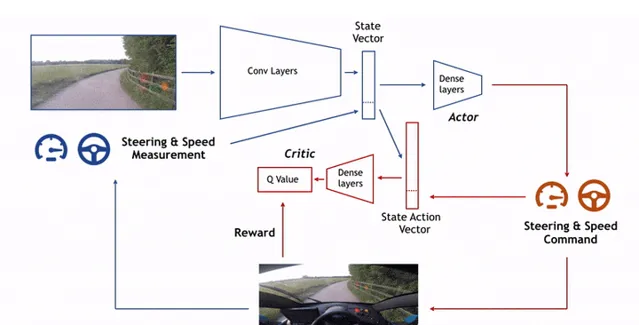
2018- ChauffeurNet [3]
開發並使用了ChauffeurNet處理自動駕駛過程中遇到的極端情況,並且可用避免懲罰不良時間的損失對於激勵的擾動降低,提升數據產生效率。
綜上只是對RL和DRL的研究在自動駕駛領域進行的部份介紹,還有很多空白領域正在等待研究突破。
但是從目前來看,無論是DRL還是RL都取得了在模擬場景(如遊戲領域)取得了令人興奮的成果,自動駕駛領域也基於TORCS與DRL發展出一套成熟可用的自動駕駛仿真系統 [4]
即便仍然存在實際套用過程的瑣碎的矛盾場景和DRL非常難訓練去解決非經典等問題,但相信未來會有更多理論可以開發並套用到自動駕駛場景中,成為L4甚至L5級別無人駕駛主要實作助力。
想了解更多自動駕駛與深度學習相關內容,請關註小鵬汽車知乎官方機構號。
謝謝大家!
參考
- ^ 論文連結 https://arxiv.org/abs/1604.06057
- ^ 論文連結 https://arxiv.org/abs/1604.07255
- ^ Learning to Drive by Imitating the Best and Synthesizing the Worst https://arxiv.org/abs/1812.03079v1
- ^ Deep Reinforcement Learning and Control —— Spring 2017, CMU 10703 https://katefvision.github.io/











