作為一個非常有意思的初等面經題,這個問題只要稍微有學那麽一丟丟基礎,應該都不至於答不上來,但出於開題的目的,我還是簡簡單單說一下最為常用的除余法
比如我們又一個數碼n,想要轉為m進制的數
只需要用n不斷地去整除m直到整除結果是0,最後把所有結果的余數從下到上連起來,就可以了,比如10進制的15轉換成2進制
- 15/2=7....1
- 7/2=3.....1
- 3/2=1.....1
- 1/2=0.....1

所以15的二進制就是1111。程式碼寫起來也非常簡單
void
toBinary
(
int
n
)
{
if
(
n
>
1
)
{
toBinary
(
n
/
2
);
}
printf
(
"%d"
,
n
%
2
);
}
但上面這個顯然不夠怎麽「有意思」
如果我們想讓這個題目可玩性變高點,我們可以假設n是一個非常大的數碼,這種進制轉換就可能從一個初等面經題過渡到中等面經題。昨天在Bi站上剛好刷到了這個問題

例如,題目中值為2的1919810次方,這個問題在計算上並不復雜,在二進制中只需要對1向左移位1919810次就可以了,僅僅只是一個數據的表示問題。
而如何把二進制值變為一個超長的十進制,則會復雜的多。但我們還是有一些手段去最佳化計算,例如我們想要計算2的32次方,我們完全可以用
2^{32}=2^{16}*2^{16}
然後
2^{16}=2^{8}*2^{8}
這樣原本32次的乘法只需要5次來完成,也就是說如果不考慮乘法復雜度,我們把原本需要32次的乘法變成了5次。
現在的問題是,按照這個思路如果一個數碼很大,兩個十進制大數相乘我們如何實作呢,我們先舉個簡單點的例子,比如
114*514=?
顯然的,我們可以使用小學就會的豎式計算,比如:
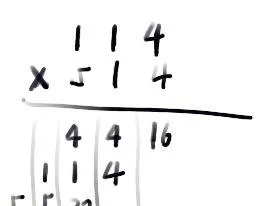
如果你按照這種思路計算,那麽,完成2的1919810次方大概就和開頭的速度差不多, 大約需要50秒的時間。
那麽,還能不能夠快一點。
如果我們觀察上述的計算,我們會發現這不就是離散訊號[1,1,4]和[5,1,4]摺積操作麽。這個時候,課上老師一句重復了無數遍的話又響了起來
"訊號時域的摺積等於頻域的乘積"
你想啊,摺積好算還是乘積好算,當然是乘積好算,要是我們把兩個數看作兩個不同的離散訊號序列,變換到頻域後乘起來,然後再變換回時域,之後不就只要算進位運算了麽。
那怎麽把時域和頻域間互相轉換呢,顯然的,我們首先想到了傅立葉變換,快速傅立葉變換透過蝶形運算可以降低時間復雜度又稱為快速傅立葉變換,所以,兩個大數相乘我們可以按照下面的步驟來:
所以你看,能夠簡化運算的本質上是快速傅立葉變換的蝶形交叉演算法配合復頻域的復數運算性質在起作用,恰好和傅立葉變換撞到了一塊兒,甚至可以說還有其它具有類似演算法性質的非傅立葉時頻變換也可以用來做簡化運算操作。
那麽,原本復雜度為 O(n^2) 的大數乘法運算,透過快速傅立葉變換就變成了 O(nlogn) ,如果你完成這個運算,大概需要0.5秒-1秒左右的時間,快了50-100倍
實際上上面的多項式最佳化,在需要大數運算的數學庫中是相當普遍的做法,如果你是acm,oj黨,應該是多多少少有學過
但是,到這一步仍然只是"有點意思",如果在面試中,仍然達不到震驚面試官一下午的程度。
還能不能夠再快一點?
讓我們回到除余法,現在,讓我們來看看二進制除法

如果你動手試一試,你會發現,在豎式計算中,我們求得十進制其中一位:
本質上不就是除數和被除數之間的減摺積操作麽,被除數就是其中的摺積核,摺積的結果,再用相同的摺積核再次進行摺積。
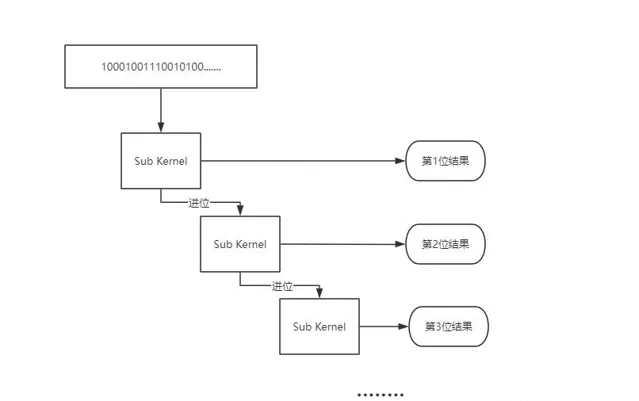
這個時候,我們就把一個簡單的二進制轉換十進制問題,成功過度到電腦組成原理的問題,但是比較遺憾的是CPU體系天生就不適合處理這種摺積操作。
所以,我們得考慮verilog語言來編寫這個摺積核了,觀察下面的硬件處理架構,及Sub Kernel的verilog程式碼
`timescale
1
ns
/
1
ps
module
b2d_cell
(
input
wire
i_wire_clock
,
input
wire
i_wire_resetn
,
input
wire
i_wire_data
,
output
wire
o_wire_data
,
output
wire
[
3
:
0
]
o_wire_dec
);
reg
[
3
:
0
]
reg_data
;
assign
o_wire_data
=
reg_data
>
4
'd4
;
assign
o_wire_dec
=
reg_data
;
always
@(
posedge
i_wire_clock
or
negedge
i_wire_resetn
)
begin
if
(
!
i_wire_resetn
)
reg_data
<=
4
'b0000
;
else
begin
if
(
reg_data
>=
4
'd5
)
reg_data
<=
((
reg_data
<<
1
)
|
i_wire_data
)
-
4
'd10
;
else
begin
reg_data
<=
(
reg_data
<<
1
)
|
i_wire_data
;
end
end
end
endmodule
每一個Sub Kernel都有一個4位元的寄存器,當寄存器的值大於或等於5時(每個時鐘左移位一次),則進行一次減法,並拉高進位寄存器。在頂層模組中,將每個Sub Kernel模組級聯在一起
`timescale 1ns / 1ps
module b2d_top #(
parameter dec_length = 8
)
(
input wire i_wire_clock,
input wire i_wire_resetn,
input wire i_wire_data
);
wire[dec_length-1:0] wire_cell_data;
wire[dec_length-1:0] wire_cell_out_data;
wire[3:0] wire_cell_out_dec[dec_length-1:0];
genvar i;
generate
for(i=0; i<dec_length; i=i+1)
begin : RTL
b2d_cell cell_inst(
.i_wire_clock(i_wire_clock),
.i_wire_resetn(i_wire_resetn),
.i_wire_data(wire_cell_data[i]),
.o_wire_data(wire_cell_out_data[i]),
.o_wire_dec(wire_cell_out_dec[i])
);
if(i==0)
begin
assign wire_cell_data[i] = i_wire_data;
end
else
begin
assign wire_cell_data[i] = wire_cell_out_data[i-1];
end
end
endgenerate
endmodule
最後,我們只需要需要轉換的數據送到頂層模組中,當我們完成所有數據的傳輸後,就可以在下一個時鐘內,從每一個sub kernel中取得十進制各位的bcd碼值了
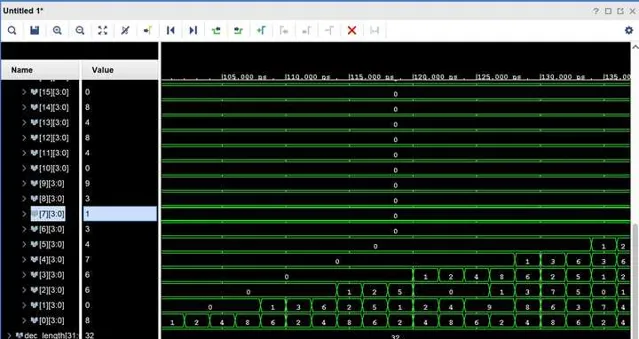
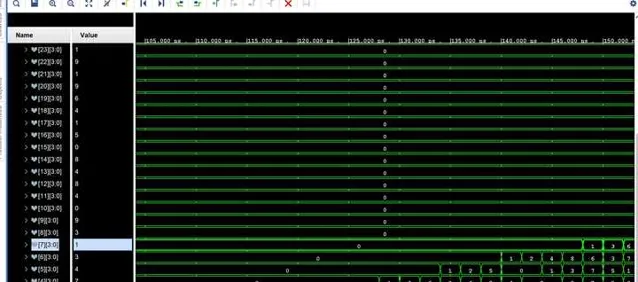
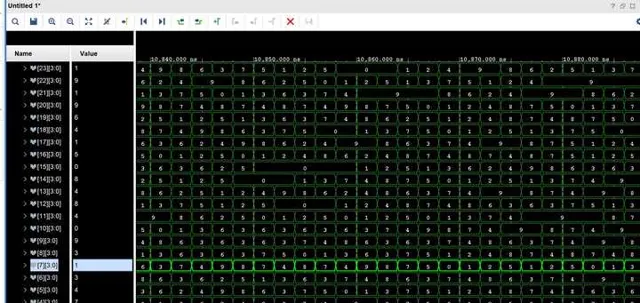
最後,耗時是多少呢?因為每個kernel的時延是確定的,就是1個clock,運算速度幾乎等價於數據傳輸的序列理論頻寬,所以如果按照目前中等效能家用CPU的工作主頻5Ghz來算的話,2的1919810次方的轉換只需要0.00038秒就能夠計算完成,足足比快速傅立葉法快了1000倍,比暴力計算快了100000倍。











