
今天给大家分享一个实用的爬虫项目, 批量采集4K壁纸 ,从此壁纸不愁,张张精品。记得点赞收藏哦,话不多说,盘它!(偷笑)
先上地址:pic.netbian.com/
该网站下载图片是需要登录的,因此
cookie
的获取是我们面临的第一个问题。
获取cookie
我们使用
selenium
自动获取
cookie
。
先导入所需要的模块。
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
打开网站首页。
driver = webdriver.Chrome()
driver.get('https://pic.netbian.com/')
F12
打开开发者工具,定位登录标签的位置。
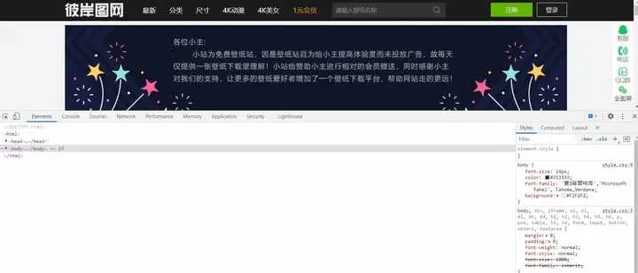
wait = WebDriverWait(driver, 10, 0.5)
wait.until(EC.presence_of_element_located(
(By.XPATH, '/html/body/div[1]/div/div[2]/a[2]')),
message='定位超时').click()
这里
selenium
打开页面速度比较慢,我们可以使用显示等待,每隔0.5s就检测一次元素是否存在,超过10s则抛出异常。
定位QQ登录
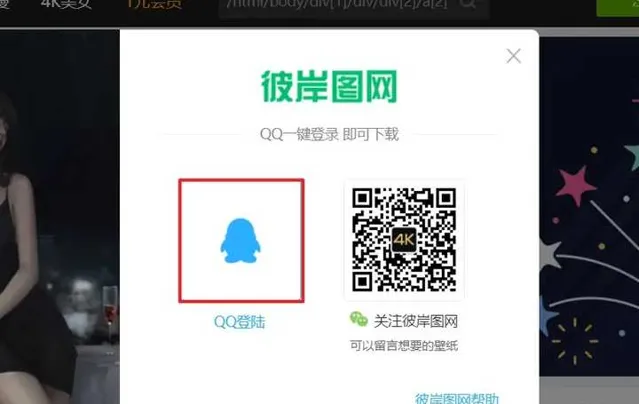
跳转后点击账号密码登录。
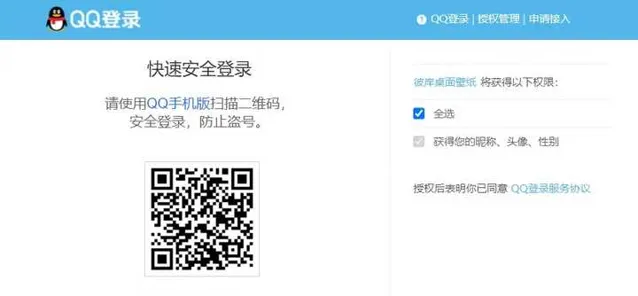
然后定位账号密码,点击登录
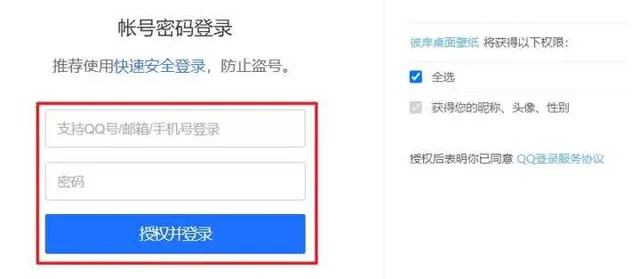
上述步骤代码
driver.find_element(By.XPATH, '/html/body/div[1]/div/div[2]/div[1]/div[3]/ul/li[1]/a/em').click()
# 定位页面标签,判断是否跳转成功
wait.until(EC.presence_of_element_located(
(By.XPATH, '//*[@id="combine_page"]/div[1]/div')),
message='定位超时')
# 切换进入iframe
driver.switch_to.frame('ptlogin_iframe')
# 点击账号密码登录
driver.find_element(By.ID, 'switcher_plogin').click()
# 输入账号
username = driver.find_element(By.ID, 'u')
username.send_keys('账号')
# 输入密码
password = driver.find_element(By.ID, 'p')
password.send_keys('密码')
# 点击登录
driver.find_element(By.ID, 'login_button').click()
下一步,我们判断一下页面是否跳转成功,如果成功,就直接获取页面的
cookie
。
wait.until(EC.presence_of_element_located(
(By.XPATH, '/html/body/div[1]/div/ul/li[2]/a')),
message='定位超时')
cookies = {}
for item in driver.get_cookies():
cookies[item['name']] = item['value']
print(cookies)
图片采集
cookie已经获取到了,现在可以开始图片的采集了。图片有很多分类,这次演示采集的是动漫图片。
首先导入所需的模块。
import requests
import os
import re
from lxml import etree
在当前路径下创建一个文件夹保存图片。
isExists = os.path.exists('./4ktupian')
if not isExists:
os.makedirs('./4ktupian')
我们手动下载一张图片,观察一下下载链接。
https://
pic.netbian.com/downpic
.php?id=25487& classid=66
经对比发现,各个图片下载链接
?
前面的部分都是相同的,
id
是图片的
id
,
classid
为分类
id
,而动漫这个分类的ID就是66。
唯一需要注意的就是图片的id,它可以从图片跳转的链接上面提取。
OK,基本逻辑理清楚了。
采集部分的代码如下,这里共爬取 15 页的图片,300张。
headers = {
'Users-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'
}
for page in range(1, 16):
if (page == 1):
new_url = 'http://pic.netbian.com/4kdongman/'
else:
new_url = format(url % page)
response = requests.get(url=new_url, headers=headers, cookies=cookies)
# 设置获取响应数据的编码格式
response.encoding = 'gbk'
page_text = response.text
# 数据解析
tree = etree.HTML(page_text)
li_list = tree.xpath('//ul[@ class="clearfix"]/li')
img_id_list = []
img_name_list = []
for li in li_list:
img_id = li.xpath('./a/@href')[0]
img_id = re.findall('\d+', img_id)[0]
img_id_list.append(img_id)
img_name_list.append(li.xpath('./a/img/@alt')[0])
# 获取完整图片url
img_url_list = []
for img_url in img_id_list:
img_url_list.append(f'https://pic.netbian.com/downpic.php?id={img_url}& classid=66')
# 提取图片数据
for i in range(len(img_url_list)):
img_data = requests.get(url=img_url_list[i], headers=headers, cookies=cookies).content
filePath = './4ktupian/' + img_name_list[i] + '.jpg'
with open(filePath, 'wb')as fp:
fp.write(img_data)
print('%s,下载成功' % img_name_list[i])
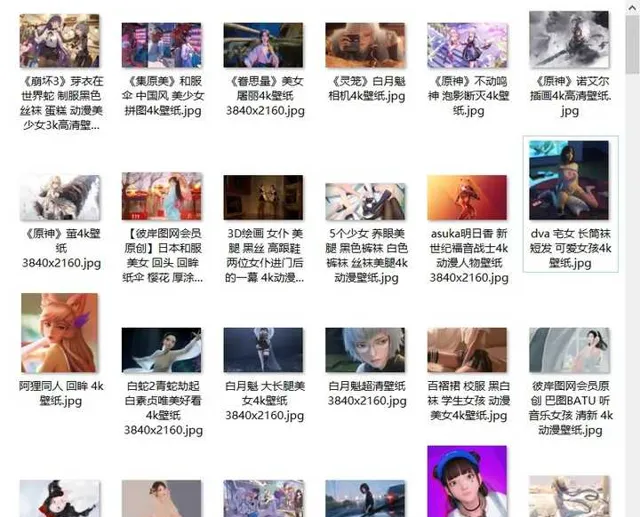
每个图片大小都在2-4M左右,巨清晰。

看到这,大家别高兴得太早,网站提供了会员制,年度会员才能够每日下载200张,所以,上面的代码中理论是下载300张,但实际原画质的只有240张左右,其余图片均无法打开。普通用户,每日提供一张免费下载原图的机会。
考虑到维护一个网站确实不容易,我也赞助了一下,赠送了包年会员,每天200次下载机会,但手动下载200张确实也不现实,所以才有了这篇文章。哈哈,大家全当学技术就好啦。
文中代码已全部整理好,采集的图片,也已经打包好了,有需要话











