作为萌新小透明,笔者自然是和 @永唯 这种大佬比不了的,不过还是先放一下年度成就:

大概是2019年9月左右,【爱上火车】系列作品的主笔进行豹老师在征集包括东风4型等在内的一系列铁路车辆的风笛声。但是笔者考虑到原版DF4已经几乎绝迹,可遇而不可求,于是便在丹水池站附近录制了担任武汉地区路内交通车次本务的资阳厂DF4B型的鸣笛,并在进行了合规检查以及简单后期后提交。
当时笔者也并未抱太大希望,并且在一年多以后也渐渐淡忘了此事。但是在上个月初,笔者在观看【爱上火车】系列衍生番剧【铁路浪漫谭】第10集(约01:50处),发现其中所用的鸣笛声意外熟悉。果不其然,在第11集的时候,笔者便在结尾处看到了自己的ID(因为该部番剧素材相关致谢列表较长,所以笔者这类素材提供者的列表都是「分卷」的,每一集放一部分,故要等到第11集才轮到笔者)。
以下为出镜的西瓜:


以下为配音(超大雾):

除此之外,笔者通过各种渠道购买了一系列【爱上火车】系列相关的原声音乐集合(实体版、数字版、大陆版、日版均有),但是这些音乐文件都有一个逼死强迫症的问题:无论是光盘还是数字文件,均缺少相关元数据(或者元数据乱码,对说的就是DLsite你)。原本笔者计划利用空余时间自行整理相关文件,但是在听闻Lose社团决定停止活动后,出于纪念的考虑,笔者便将整理好的文件元数据信息登记到了MusicBrainz数据库(需要注意的是,MusicBrainz并非音乐分享平台,而是类似CDDB与Discogs的音乐元数据与索引数据库):
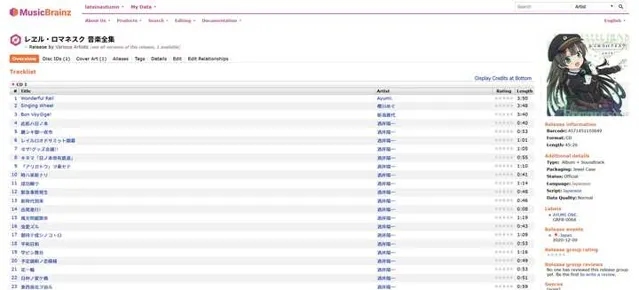
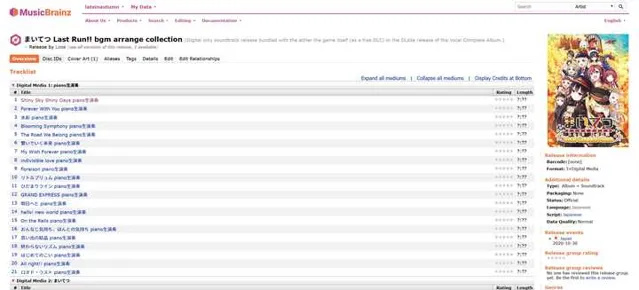
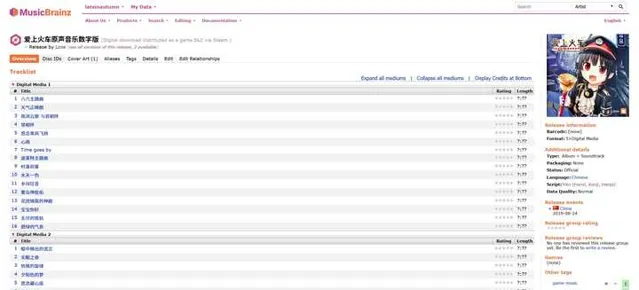
现在,手上持有相关CD或者文件者,便可以通过支持MusicBrainz数据库的软件(如EAC、Picard、Mp3Tag等)批量整理与标记相关音频文件了:
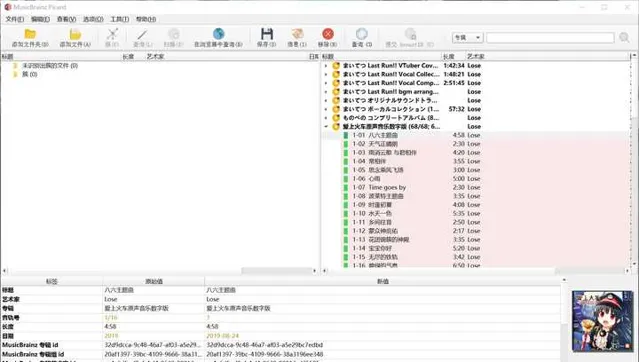
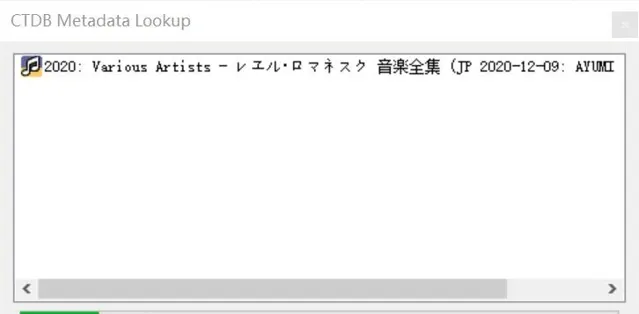
目前,笔者还缺少【爱上火车】(原作)国版的Disc ID. 由于笔者的国版CD套装被留在了武汉,因此暂时无法将其记录至MusicBrainz. 预计笔者将与友人联系,由友人协助进行登记。
最近笔者误入了一个国际同好群,并且群内的英美友人受到Lose停止活动的影响,考虑自立更生,自行翻译【爱上火车Last Run】。于是笔者便开了个协助翻译为主、扩展阅读为辅的大型读书笔记坑:

目前已经完成了两条最麻烦的线路的笔记,剩下的在与英美友人确认优先级与粒度以后,预计可以在两到三周内完成。
最后之外,虽然与【爱上火车】系列不直接相关,但是笔者在去年11月末南加州地区再次全面封锁前,专程抽出了一天前往南加州铁道博物馆,近距离观摩1922年出厂的鲍尔温蒸汽机车的复活(而笔者通常对蒸汽机车并没有太大的兴趣,主要还是关注内燃与电力机车):









(光速逃
一天下来居然过百赞了,萌新实在是不敢当。承蒙厚爱,吐槽一下大战DLsite的经历:
DLsite下载的音频文件,大多数是没有任何元数据的WAV格式:

对于WAV文件,笔者所进行的第一步操作便是将其转换成有着较好的元数据支持的格式(如FLAC或者WavPack等,笔者使用了自购的dBpoweramp进行批量转换),再进行元数据编辑(WAV本身也可以使用ID3v1标签,但是问题较多,不推荐)。
如果文件本身并不包含元数据,笔者一般使用Mp3Tag的文件名解析功能进行解析,再对解析结果进行微调:
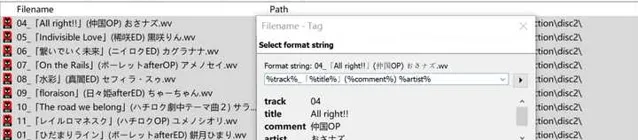
完成标签编辑以后,便可以使用Mp3Tag的批量重命名功能,规范化文件名:

最后在目录内执行
dir /b
或者
ls
命令,获取文件列表,稍加编辑后即为可直接喂给MusicBrainz编辑器曲目列表。
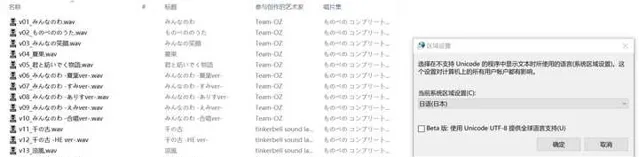
然而部分来自DLsite的WAV文件虽然包含元数据,却因为ID3标签规范设计和日系软件非标准默认行为等原因,往往会乱码:


当然对于此类文件,也可以通过解析文件名的方式来填写标签。但是考虑到文件本身已经包含元数据,更为理想的方式自然是对乱码进行「抢救」。而抢救乱码则很大程度上靠猜。
对于日本来源的文件,首先考虑Shift JIS编码(代码页932):
可以看到,对于【茂伸奇谈】的原声专辑,该猜测是正确的。但是对于【爱上火车Last Run】的DLsite限定BGM合集,代码页932并不能解出正确的标签信息。于是笔者便灵机一动继续尝试:
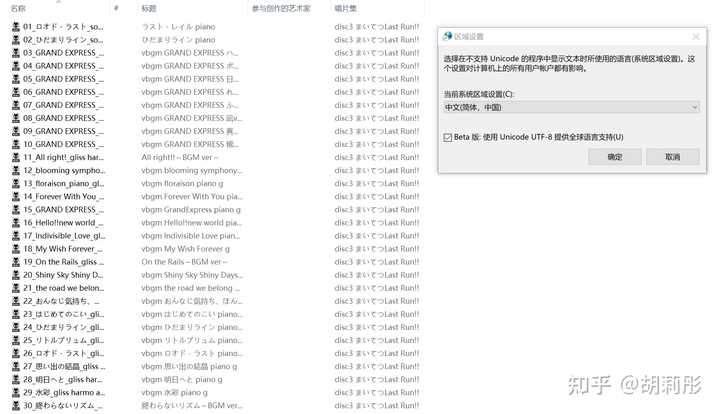
不讲武德,居然在ID3v1标签里面用UTF-8, 大意了啊没有闪。
解码出正确的标签以后,要立刻批量转换成合适的格式。再参照前面的例子,使用Mp3Tag完善与微调标签,并将文件批量重命名。之后便可以将按照同样的方式,生成曲目列表,并喂给MusicBrainz.











