最方便的是直接用现有的数据集。
IMDb 官方发布的有数据集:
数据集的官网链接如下,
(但是官方给出的是简要数据集,似乎不包含题主所说的Technical Spec)。所以这里需要从官方的数据集出发去爬所需要的条目
数据的格式是TSV
可以用excel预览一下
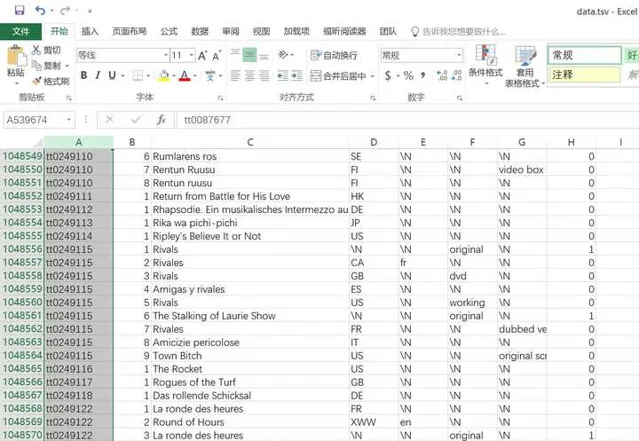
A列是电影的唯一标识ID,每个电影对应唯一一个ID
C列是电影的名字
官方数据集每天更新,所以无需担心数据中不包含新电影
也就是说在这里官方已经提供了一个完整的id集合。
这看起来是一个非常【爬虫友好的网站】,都不用自己抓索引,自己就把所有索引直接给出了。
回到题主所需要的 Technical Spec 栏目
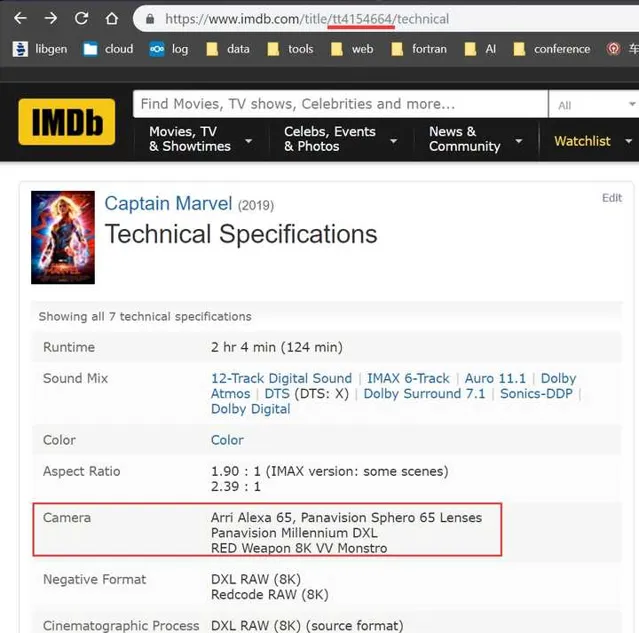
打开某个电影的Technical Spec页面,无需登录,地址栏里面t开头的字段就是ID,改变ID就可以访问不同电影的Technical Spec。
所以这个爬虫的思路非常简单,遍历所有ID,把每个ID下的Technical Spec 页面里的Camera保存下来就OK
这里需要使用urllib来获取网页,然后使用re来正则表达式解析网页找到我们需要的内容。
回到网页按下F12打开开发者模式
查看对应内容是如何组织标签的:
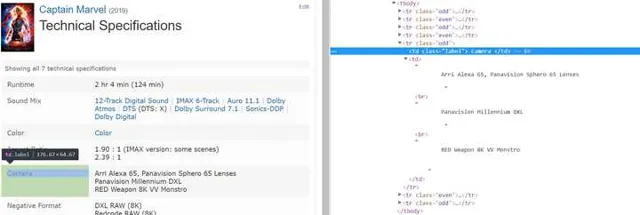
以上面这个电影的ID为例,用正则表达式来提取这几行里的有用信息(正则表达式是一种从字符串中寻找特定特征的字串的方法,具体可以参考Python 正则表达式 | 菜鸟教程):
import
urllib.request
as
urlreq
import
re
id_str
=
'tt4154664'
x
=
urlreq
.
urlopen
(
"https://www.imdb.com/title/tt4154664/technical"
)
content_url
=
x
.
read
()
.
decode
(
'utf-8'
)
a
=
re
.
search
(
r
'<td class=\"label\"> Camera </td>.*?</td>'
,
content_url
,
re
.
S
)
res
=
re
.
sub
(
'<td.*?>|</td>|<br>'
,
''
,
a
.
group
())
print
(
res
)
代码中前两行引入urllib用于网页请求,引入re用于正则表达式匹配。5-6行请求网页,直接请求下来的网页html是这样的,需要从中提取有用信息
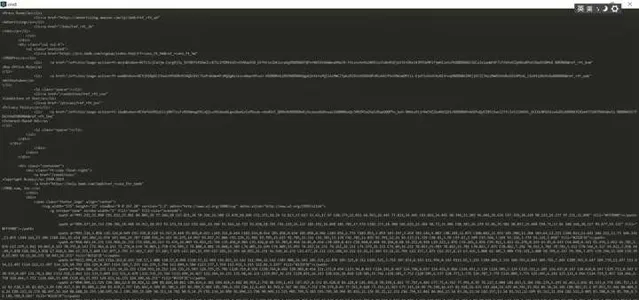
第7行使用re寻找所需要的内容,第八行整理一下,去掉<td>|</td>|<br> 这些标签。
得到的内容应该是题主想要的Camera内容
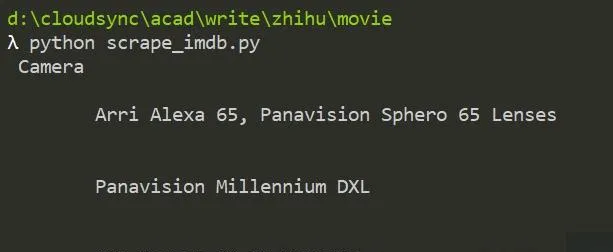
对于这一条成功的获取了所需要的信息。
接下来就是遍历官方提供的整个大列表,收集所有电影的camera信息,存入一个TSV或者CSV或者whatever。方便搜索就行。
注:
根据IMDb官方条款,使用机器人批量收集信息是违规的(来源: Conditions of Use - IMDb )
Robots and Screen Scraping: You may not use data mining, robots, screen scraping, or similar data gathering and extraction tools on this site, except with our express written consent as noted below.所以这里不展开讲如何改变user_agent,调节抓取间隔,使用代理,以及分布式抓取的方法
几个电影相关的数据集
(IMDb的API许可非常的贵,爬虫抓全站又违规,所以这里列出几个电影相关的现成数据集)
比较有名的是Kaggle里的几个:
IMDB 5000 Movie Dataset
IMDB Movies Dataset
IMDb官方提供的乞丐版也算上吧: - IMDb,https:// datasets.imdbws.com/
OMDb,一个提供开放API的电影数据库 The Open Movie Database
=========
Pjer内容分类:
精选 射电 编程 科研&工具 太阳物理










