大模型=基础模型 (Foundation Model),模型参数为数亿到数十亿。
超大模型:模型参数更大 的大模型,通常有数万亿个参数,因此学习能力更强。
下面从定义、技术背景和应用场景来详细聊聊~

基础模型(Foundation Model,即大模型)
定义
2021年8月,斯坦福大学人类中心人工智能研究所(HAI)发表了一篇研究:On the Opportunities and Risk of Foundation Models,首次提出了Foundation Model的概念:即在多种任务和领域中具有 广泛适用性 的 大型预训练模型 。
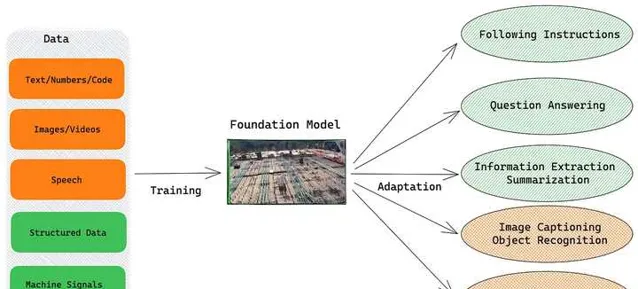
这些模型之所以被称为「基础」,因为它们可以作为许多下游任务的起点,通过微调或进一步训练来适应特定的应用。如图所示,我们可以理解成大模型(基础模型)是一个地基,给它不同的材料(训练数据),就可以搭建不同的房子(应用于不同的场景)。
技术基础
大模型的技术基础主要是深度学习,包括预训练与微调、transformer架构:
1.预训练与微调(Pre-training and Fine-tuning):
预训练: 基础模型首先通过无监督或自监督学习方法,在大规模的数据集上进行预训练。通过与训练,模型能够学习到丰富的特征表示和数据中的潜在结构。
微调: 预训练完成后,模型会针对特定的下游任务进行微调,以提高性能;通常在有标注的数据上进行模型训练(监督学习)和模型性能优化。
2.Transformer架构 :
基础模型通常是在Transformer架构的基础上构建的。
Transformer最早是Google在2017年的Attention Is All You Need论文中提出,解决了传统的序列到序列(sequence-to-sequence,Seq2Seq)模型在处理可变长序列时遇到的问题。
传统的序列模型(如RNN、LSTM)难以捕捉序列的长距离依赖关系,即序列中相隔较远的元素之间的关联。Transformer通过自注意力机制,使得模型能够直接关注序列中任意两个位置,从而有效地捕捉这种长距离依赖。
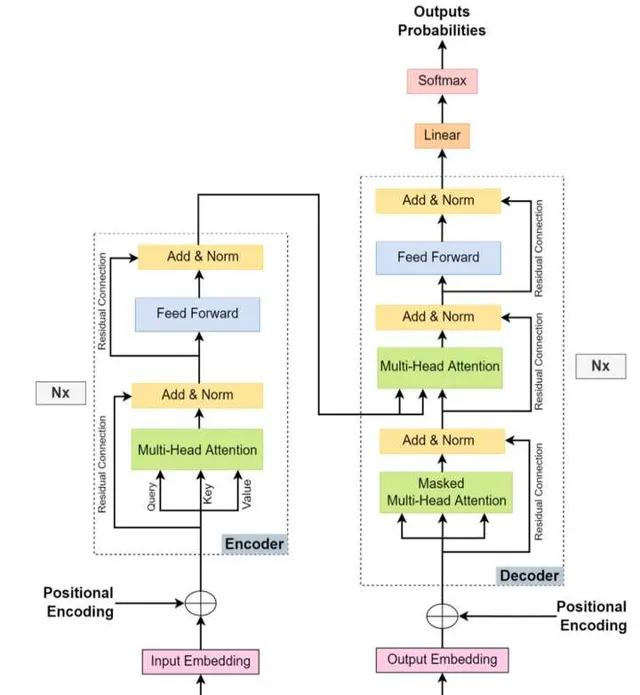
上图是Transformer的组成。左半部分是编码器(Encoder),主要作用是将输入数据编码成计算机能理解的高维抽象表示。它的核心是由多个 自注意力层 和 前馈神经网络 组成的。
右半部分是解码器(Decoder),主要作用是利用高维表示信息生成目标序列。它的结构与编码器大致相同(注意力层+前馈神经网络),不同的点是采用了掩码注意力层(Masked Attention),且中间部分,利用了Encoder的输出结果计算交叉注意力(Cross Attention)。
(如果想详细了解transformer的原理,可以参考我的这篇知乎回答:
)
简而言之,transformer的核心是 注意力机制 ,它解决了传统序列模型处理可变长序列的 遗忘 问题。且它能进行并行计算,能有效提升计算效率,所以被广泛应用于基础模型中。
应用场景
通过预训练和微调,大模型的应用场景非常丰富,在自然语言处理、音频处理、多模态任务处理等均表现出色。
自然语言理解和生成: 在机器翻译、文本摘要、问答系统、聊天机器人等领域,大模型可以生成流畅自然的语言,理解复杂的查询。例如,谷歌推出的BERT-Large模型有3.4亿个参数,它是NLP领域的重要突破。
音频处理: 大模型在语音识别、语音合成、语音翻译等任务中也表现出色。例如DeepMind的WaveNet是一个大型的生成模型,用于生成自然的人声。
多模态任务: 大模型也可以应用在需同时处理文本和图像的任务中,如图像标注和视频理解。OpenAI的CLIP模型是一个大型的多模态模型,它可以理解图像和对应的文本描述。
如今,大模型具有广阔和丰富的应用场景,初创公司和行业巨头也纷纷投入到这场大模型竞赛中,试图通过开发独具特色的大模型来抢占市场份额。对于个人而言,大模型也能成为生产利器,帮助我们成为AI时代的超级个体。
如果你想跟紧时代前沿,把握技术风口,可以参加这门知乎知学堂联合AGI课堂推出的 AI大模型免费公开课 ,特邀圈内技术大佬帮我们全面解读大模型技术 。
在两天的免费课程中,我们可以了解大模型发展历程与训练方法、Prompt Engineering、利用LangChain+Fine-tune定制大模型应用等知识,最终利用大模型为我们赋能。添加助教老师微信还可以 领取大模型资料包、免费无翻墙的大模型工具网址 等资源,不要错过啦~
超大模型(Very Large Model)
超大模型和大模型的主要区别在于 模型参数的差异 :大模型(基础模型)的参数通常在数亿到数十亿参数之间,而超大模型是大模型的扩展,它们通常拥有高达数万亿个参数。这些模型的规模和复杂性带来了更高级的学习能力。
在自然语言处理领域: OpenAI的GPT3.5是一个典型的超大模型,拥有1750亿个参数,它在包括写作、翻译、推理等多种语言任务上展示出了惊人的性能;最新推出的GPT4在更为庞大的训练数据基础上训练,其在生成响应时能够考虑超过 1 万亿个参数。
在音频识别领域: Jukebox是一个能够生成音乐的超大模型,包括旋律、节奏、和声等元素,它可以创作不同风格和艺术家的音乐作品。
在多模态任务上: DALL-E模型是一个超大型的生成模型,它可以根据文本描述生成相应的图像,展示了强大的创造力;GPT-3 with vision模型是一个跨模态的超大模型,它能处理图像输入并生成描述。
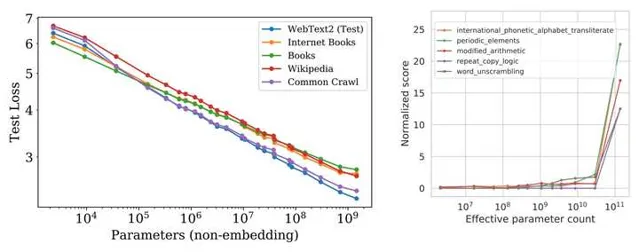
研究表明,随着模型的规模(如参数数量、数据量、计算量)增大,其性能通常会随之提高,(即 缩放定律 ,Scaling Laws);同时模型达到一定的规模时,它会表现出一些在小模型中不曾出现的新能力(如常识推理、创作能力),这些能力不是被特意设计或训练出来的,而模型的规模增长中「涌现」出来的,被称为 涌现能力 (Emergent abilities)。
因此,超大模型通常能在不同任务中取得比大模型更好的表现。例如,GPT4.0能明确鲁迅和周树人是一个人,但GPT3.5却认为他们是两个不同的人。
大模型(基础模型)、超大模型是AI领域中最令人激动的进展,它们正在推动技术的边界,在多个领域中开辟可能性。
人工智能的未来已来,让我们利用大模型改变世界!
我是等壹,毕业于上海交大,现互联网研发。
是个爱旅行,爱阅读,爱写作的文艺青年,也是个热爱学习分享技术的geek~
我会定期分享技术、职场、学习等干货,欢迎关注!
参考文献:
- On the Opportunities and Risks of Foundation Models
- essential-guide-to-foundation-models-and-large-language-models
- https://www. assemblyai.com/blog/eme rgent-abilities-of-large-language-models/
- Scaling Laws for Neural Language Models
- Quantifying and extrapolating the capabilities of language models











