首先说一下结论:RL 及其相关算法 是 大(语言)模型真正智能的主流赛道。
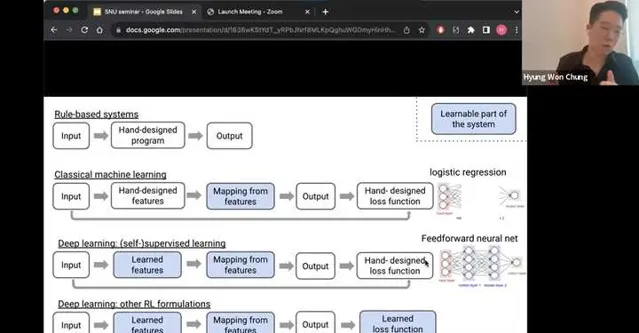
我粘一个图来阐述一下我的李姐,图片来自于Hyung Won Chung (OpenAI)的一个talk,在这个talk的最末尾给出了这么一张图阐述了他对于智能系统的展望。之所以粘贴这个图,是因为我自己也做了一个类似的,但是表达的没有他的清晰。
有兴趣看全集的可以参考这个视频:
RL被引入到自监督学习(SSL)之后,除了增加了就业岗位之外,其实在loss function这一块还是给了更强的通用智能一个很不错的方向的。我们这些年,从深度学习开始爆发开始,智能的演进差不多也经历了这些过程,所谓机器学习真正学习到的是这些:
1. 传统机器学习:收集输入输出,手动设计feature,手动设计loss function,最后让机器学习的是从feature到output的一个mapping 。传统的机器学习,包括了大量feature engineering的内容,同时feature的选择依赖人工经验。
2. 深度(自监督)学习:到了这个阶段,手动的feature设计也被替代了,tokenizer和learnable的embedding成为了大语言模型的标配,模型的大小在数据和AI infra的加持下迅速scale up。
3. 深度(强化)学习:以ChatGPT,Claude,Llama2,Qwen等为代表的RLHF及RLAIF派,把深度自监督学习里的手工loss function也变成了可学习的部分。通过reward model代理表征人类喜好等方式,将学习目标从增强下一个token的likelihood,转变成提升模型有用性&无害性等目标。
如果您赞同这个技术趋势,那么RL确实能够朝着通用智能的方向前进;像我一样的工程师也一定能在艰难求索AI落地的过程中,从行业中分到一杯羹。

这么说当然有为了给市场打气,然后哄抬RLer身价的嫌疑,但是在这个话题下有一些特别fundamental的事情想要和各位讨论,这些事情也是我自己最近一个阶段的职业兴趣所在,欢迎各位点评。
Maximum likelihood is too strong of an inductive biasChatGPT已经出现了一年了,算法工程师的日子不是变好了,而是变坏了,因为本质上算法工程师善于体现价值的领域实际上是图中白色的部分。在大模型时代,留给算法工程师的空间其实主要就是在Input,Output阶段了,不管是在做预训练还是在做有监督微调,大量的时间和工作都贡献给了数据。同时笼罩着的乌云是,采用next token maximum likelihood的方式在打造行业模型,本身就存在很强的bias,非常难以scale到很大的规模,同时难以transfer到不同的领域。如果仅仅坚持在自监督的范式里,整个大模型产业会迅速内卷并且塌陷到原始的AI小作坊时代。
Learning the objective function is a different paradigm and there is a lot of room for improvementRLHF实际上也没有直接解决alignment里的所有问题,首先人类的偏好就是非常noisy的信号,作为一个代理而言很难以表征「智能」这个终极的目标。其次RL的效率问题,我从2021年开始觉得是一个比较大的问题:
从事后来看,Deepmind和OpenAI效率和规模的进步着实实现了RL的「大力出奇迹」,其余业界基本都是follower。当前的LLM中的RLHF实际上和2021年的主流RL框架的MFU差不多,因为整个系统牵涉到了多个模型的训练推理等流转的过程。原理上也是暴力的trail & error方法,不断增加正向reward的probability,降低负向reward的probability。
If something is so principled, we should keep at it until it works基于下一个token的预测到底为什么能创造智能,他的原理是什么,上限在哪里,为什么在语言的层面可以做到这件事,到底能不能够通过自博弈的方式提升语言模型的智能的上限。这些问题都太过于重要,以至于现在的很多工作都不敢挑战这些宏达的命题。通用智能从一个学术界大家都避之不及的话题,到了今天的工业界倾注海量资源,最终作为RLer和AI从业者keep at it until it works也许是一个最好的选择。
最后我再多嘴两句最近提的特别火的 Q* , Q(s,a) 表示的是在给定的状态 s 下,如果采取行动 a 能够获取到的 reward期望。如果一个问题在给定的状态 s 下,可以准确且快速地得到其action space中的行动 a 的奖励,那么就可以通过Q learning的方式从当前步(step)持续优化到未来的所有步,以获得一个最优的policy。那么就有两个问题,一是那些领域的reward值比较好弄到,二是Greg所说的next-step到底表示的是什么呢?












