1. 一个很酷的技术: SpeecpFace [1]
这是一种新的神经网络模型,试图通过某个人的语音来重现其面孔。
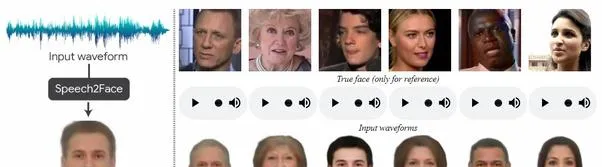
可以看到,虽然结果并不是完美的,但相似之处也是显而易见的。
ta是由麻省理工学院开发的,相关的研究论文 [2] 于2019年5月底发表。利用了数百万来自YouTube和其他来源的视频片段被用来训练这个模型。
如果有足够的数据,计算能力和时间,神经网络可以通过分析视频片段,将声音与面部配对以及找到两者之间的模式和趋势来「学习」如何重建人脸。
模型所生成的脸部会准确地重建鼻子,嘴唇,脸颊和骨骼等结构,除了眼睛之外,其余全部都可以重建。这个ML模型之所以能够work,是因为准确表示的特征在外观和语音之间具有直接相关性。例如,声音较深的人可能比声音较高的人有更宽的鼻子或下巴,而眼睛的形状和大小通常不会对某人的发音产生太大影响,这也是眼睛的重建工作不够准确的原因。
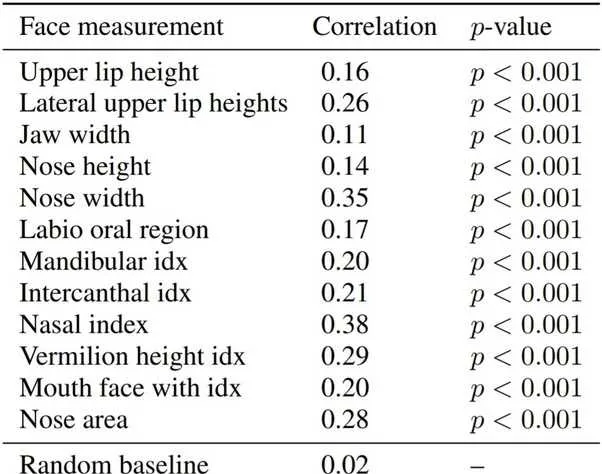
下面是作者列出的所有相关特征。相关性从-1到1,0为不相关,1为绝对相关性:
可以想象这样一个场景,你正在打电话和某个素不相识的妹子交谈。
听着她的轻声细语,你大概率在脑海中脑补出这样一幅场景:一位性格内敛,皮肤白晰,骨骼纤细,柔弱水灵,从小说吴侬软语长大的妹子,正撑着油纸伞走在寂静的雨巷。
与此同时,一幅典型的南方温婉姑娘的长相,想必也早已浮现在你的脑海里。
虽然你脑海中的形象可能与我的有所不同,但重要的是,我们两个都针对具有南方轻柔口音的女生提出了一些通用的「平均」形象。她可能是你平时遇到过或者相识的南方女生形象,或者某几个形象的组合。
这就是目前SpeecpFace的工作方式,但是它有多达数百倍的模式可供考虑。其实我们的大脑已经可以部分完成SpeecpFace的工作,例如能够仅通过声音来识别我们的同学朋友等。
这是SpeecpFace的其他一些结果:

现在有些工作试图将SpeecpFace与Nvidia的GAN [3] (生成对抗网络)结合起来:

上面所有这些面孔都是由GAN生成的,它们都不存在于现实生活中。它们是神经网络输出的结果,该神经网络充分了解了实际人类的常见特征和模式,可以自行创建它们。甚至可以将神经网络的输出发送回输入,以进一步对其自身进行训练,从而为训练提供几乎无限的数据。
GAN可以创建不存在的人类面孔,SpeecpFace可以通过声音来构建面孔。WaveNet [4] 已经可以构建接近真实的人声了,他们的结合现在看来只是时间问题。
也许在不到10年的时间里,我们可能就有能力创造出一个声音和外表都和真实人类一样的人造生命,而且很难分辨出其中的区别,不会有大叔面孔萝莉发音这种事情发生。
2. 另外, GAN (生成对抗网络)必须值得一提
尽管有答主已经介绍过了,但是有一些应用我想再分享一下:
GAN是Ian Goodfellow在2014年提出的深度学习领域中一个相对较新的概念,从那时起,它就动摇了应用于图像,文本和音频的AI。简而言之,GAN是一种神经网络,它会生成与训练集中的数据相同的伪随机变量。例如:
动态肖像:

虚假演讲:

甚至是不存在的人类形象:

3. 还有,Nvidia的 GauGAN 也是一个极其有趣的应用
今年早些时候,Nvidia开发了一种名为GauGAN的AI,它可以通过粗糙的涂鸦来创建逼真的风景。看看下面的示例:
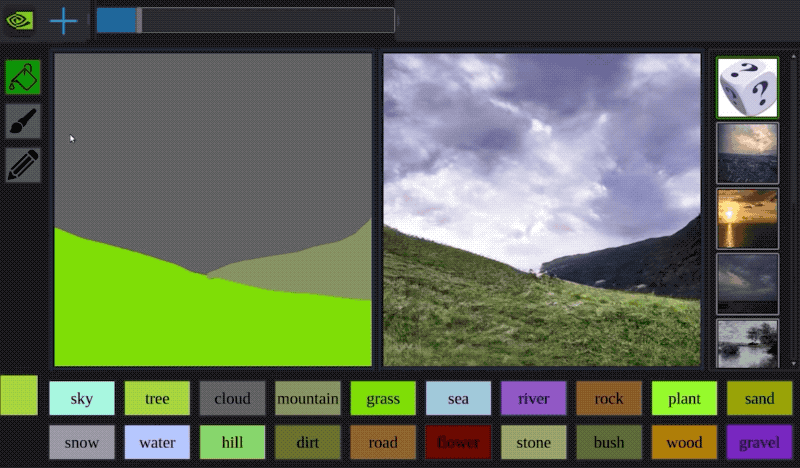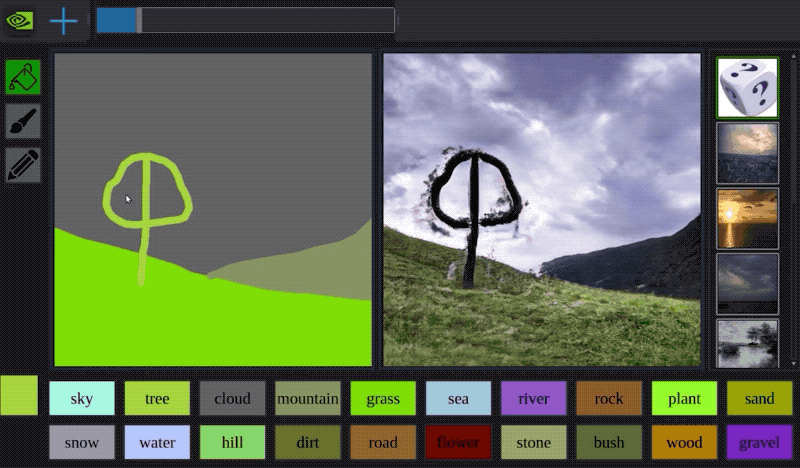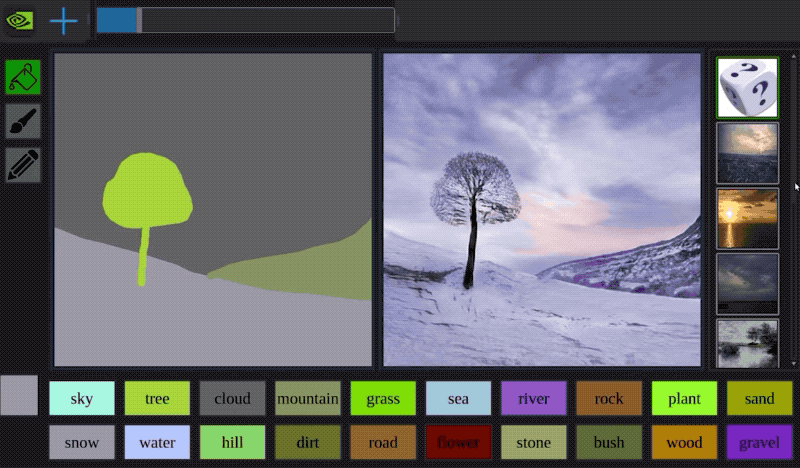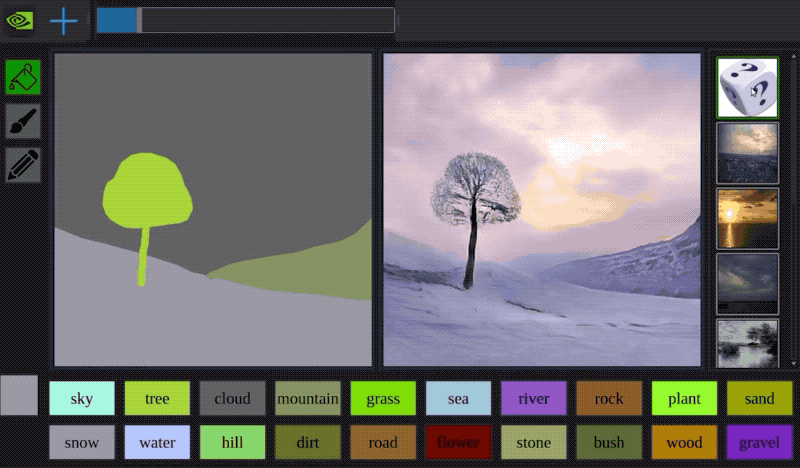
该系统使用生成对抗神经网络将粗糙的分割图转换为真实的世界。
It is like a coloring book picture that describes where a tree is, where the sun is, where the sky is, and then the neural network is able to fill in all of the detail and texture, and the reflections, shadows and colors, based on what it has learned about real images. - -Bryan Catanzaro, NVIDIA此外,创作者还制作了一个自主互动演示:演示地址
以上,谢谢!
参考
- ^ SpeecpFace: Learning the Face Behind a Voice https://speecpface.github.io/
- ^https://arxiv.org/abs/1905.09773
- ^ Progressive Growing of GANs for Improved Quality, Stability, and Variation https://research.nvidia.com/publication/2017-10_Progressive-Growing-of
- ^ WaveNet: A Generative Model for Raw Audio | DeepMind https://deepmind.com/blog/wavenet-generative-model-raw-audio/











