大家好,小鹏汽车又来回答了。
首先先回答一下RL在自动驾驶领域目前的应用现状:
先说一下行业内大多数主机厂在自动驾驶领域对于RL的应用:
由于强化学习是一种致力于实现通用智能解决复杂问题的方式,其适用于解决时序问题,而自动驾驶作为典型的「工业人工智能」,过程中包含感知、决策、控制三大环节,需要考虑各种极端工况与场景;
其中感知过程中环境要素实在太复杂,且驾驶任务灵活多变,非时序问题很多,RL在其中很难发挥主要作用,更多是DL的天下,如常用的YOLO及其变式等;只有在决策层面,Model Based RL与Rule based相互配合,其中基于规则的构建来应付大部分常见驾驶场景,但需要不断设计更新;RL来解决规则库内不适用的极端场景与问题。这也是目前行业内很多家主机厂都很「默契」采用的L3-L4算法架构。
而对于一些致力于L4解决方案的科技公司来说:
更多是选择深度强化学习DRL方式,也就是将深度学习DL的感知能力和强化学习RL的决策能力相结合,可以直接根据输入的信息进行控制,是一种更接近人类思维方式的人工智能方法,也是更具有潜力的成熟L4级别解决方案。
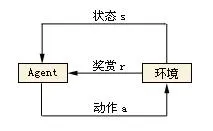
传统RL的核心在于根据环境状态序列,找到一套最优控制策略,以实现最大累计期望奖励。也就是不断在环境中试错,不断改进,下图对于RL研究者们应该非常熟悉了,小鹏在此不再赘述基本原理。
但传统的RL,在解决自动驾驶问题上面临一些通用的瓶颈,其根源是「扁平」方法的不适用 。 SF(Sensor Fusion)与行为规划的输出是多维度求解问题,而当多维度空间「扁平」后,形成的是一个平坦但非常庞大的状态空间,使得原有trial and error的路径非常曲折漫长,反向传播时,奖励信号过于微弱,此时算法工程师调参的过程必定是煎熬而且「 秃 」兀。
延伸出具体影响如下:
1.样本效率:尤其是数据生成效率、L4级别专注于极端场景处理,无疑将消耗很多等待时间
2.扩展:RL方法解决长序或非常复杂的动作及状态空间问题将导致维数灾难。
3.泛化:解决当前问题获得最大的累积奖励的策略,反而会由于过度专一,无法平移解决其他问题
4.抽象:时间与空间的状态抽象由于SF的帮助,此类问题在自动驾驶中难度有所降低。
为了解决以上问题,深度强化学习(DRL)由然而生。
其将深度学习应用到期望奖励趋势预测中,一方面有助于与CV方案的结合可以实现end 2 end方案,另外也可以在未知环境下更好预测规律,并减小期望反馈误差。
2013年DQN 1在NIPS上由DeepMind 发表1,后续又在Nature 2015提出改进版本,此方式是DRL的起始,其核心思想为以下三点:
- 通过Q-Learning使用reward来构造标签;
- experience replay(经验池)的方法来解决相关性及非静态分布问题
- 使用一个CNN(MainNet)产生当前Q值,使用另外一个CNN(Target)产生Target Q值
2015版本算法伪代码如下:

DQN是一种强大的基线智能体,作为初版尝试,在游戏领域实现了很好的通用性。但在工程实践领域,存在无法进行连续动作控制,无法处理长时间记忆(后续加入LSTM改进)和CNN需要精确调参的问题。
后续Deep Mind将A3C(Asynchronous Advantage Actor Critic)和 OpenAI 的同步式变体 A2C 也应用了DQN中(论文链接:https:// arxiv.org/abs/1802.0156 1 ),但仍然没有很好解决以上问题。
DRL中,使用了深度神经网络的分层强化学习(HRL)目前备受关注,其致力于将一个复杂的强化学习问题分解成几个子问题并分别解决,并想相信可以取得比直接解决整个问题更好的效果。理论上核心思想:以HAM、隐藏学习(封建学习),MAXQ为灵感,实现长期信度分配、结构化搜索与迁移学习,从而使得减少问题搜索的复杂性;但在自动驾驶实践中HRL也存在引入额外的超参数,增加了更新层次代理的级别所产生的非平稳性等问题。
最近几年又出现了几个基于DRL HRL想法启发,并在项目实践中取得了不错的效果,典型有以下几篇:
H-DQN [1]
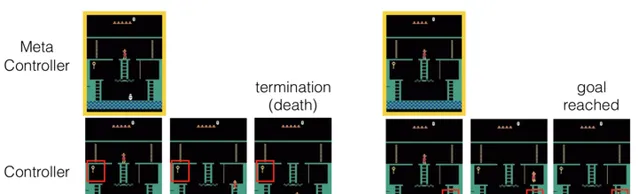
「我们提出分层DQN(h-DQN)的框架,是一个结合分层值函数,在不同的时域尺度运作,有内部激励的深度强化学习。在最高层的值函数通过内部目标学习策略,较低层的函数通过原子动作学习策略来满足目标。h-DQN允许灵活的目标指定,例如实体和关系的函数。这为复杂环境的探索提供了一个高效的空间。
我们通过两个反馈稀疏、延迟的问题证明我们的方法:(1)一种复杂的离散随机决策过程,(2)雅达利经典游戏「蒙特苏马的复仇」。
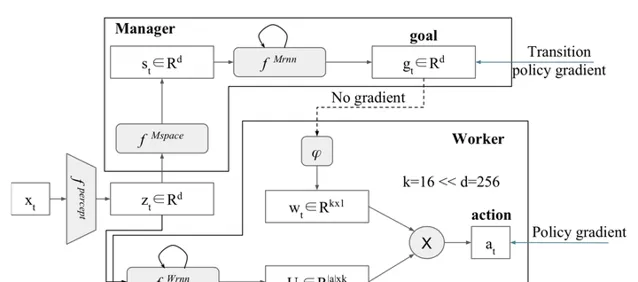
分层强化学习FeUdal网络(FuN)
FeUdal网络提出了模块化的结构。受到Hinton的封建强化学习思想的启发,系统的管理者选择一个方向进入隐状态空间,而工人学会通过环境中的动作来实现这个方向。这意味着FuN代表子目标作为隐状态空间中的方向,然后转化为有意义的行为原语。论文介绍了一种方法,能获得更好的长期信度分配,使记忆更易于追踪。
FuN结构:
H-DRLN [2]

论文主要思想:我们提出了一个终身学习系统,它能将知识从一个任务迁移或重新利用到另一个,同时有效地保留先前学到的知识库。该系统通过学习可重用的技能来迁移知识,完成Minecraft中的任务。
这些可重用的技能,我们称之为深度技能网络,随后通过两种技术:(1)深度技能阵列,(2)技能蒸馏,整合到我们提出的分层深度强化学习网络(H-DRLN)的结构中学习技能。
DDPG(Deep Deterministic Policy Gradient)
这是由DeepMind的Lillicrap 等于 2016 年提出,其核心思想是采用卷积神经网络作为策略函数μ 和 Q 函数的模拟,即策略网络和 Q 网络;然后使用深度学习的方法来训练上述神经网络。
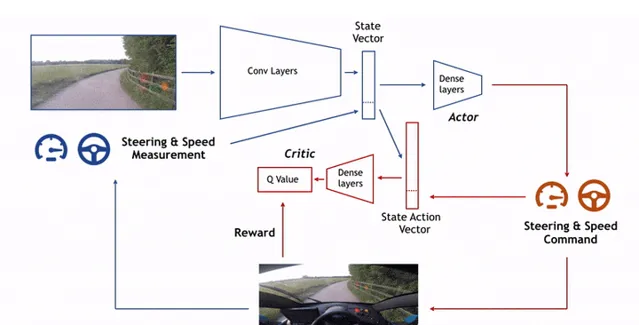
2018- ChauffeurNet [3]
开发并使用了ChauffeurNet处理自动驾驶过程中遇到的极端情况,并且可用避免惩罚不良时间的损失对于激励的扰动降低,提升数据产生效率。
综上只是对RL和DRL的研究在自动驾驶领域进行的部分介绍,还有很多空白领域正在等待研究突破。
但是从目前来看,无论是DRL还是RL都取得了在模拟场景(如游戏领域)取得了令人兴奋的成果,自动驾驶领域也基于TORCS与DRL发展出一套成熟可用的自动驾驶仿真系统 [4]
即便仍然存在实际应用过程的琐碎的矛盾场景和DRL非常难训练去解决非经典等问题,但相信未来会有更多理论可以开发并应用到自动驾驶场景中,成为L4甚至L5级别无人驾驶主要实现助力。
想了解更多自动驾驶与深度学习相关内容,请关注小鹏汽车知乎官方机构号。
谢谢大家!
参考
- ^ 论文链接 https://arxiv.org/abs/1604.06057
- ^ 论文链接 https://arxiv.org/abs/1604.07255
- ^ Learning to Drive by Imitating the Best and Synthesizing the Worst https://arxiv.org/abs/1812.03079v1
- ^ Deep Reinforcement Learning and Control —— Spring 2017, CMU 10703 https://katefvision.github.io/











