推荐下来自智源的Emu2和来自清华大学朱军团队的Unidiffuser,两个文章都探讨了语言生成和图像生成的多模态统一建模方法,某种意义上算是GPT-4o的平替(4o并没有说明自己的语言-视觉-语音多模态方案是怎样的)。
Emu2是从现在最流行的自回归生成范式出发,将图像和文本都tokenize到离散的token进行自回归式的建模,同时接入一个diffusion作为图像生成器(这克服了自回归模型在图像生成的效果不够好和效率低的问题)。个人认为GPT-4o也有可能是采用类似的自回归+扩散模型的方案,最明显的证据就是ChatGPT的DALL E-3还没下架,如果自回归已经能够很好地做图像生成,那么DALL E-3也就没有存在的必要才对。
Unidiffuser则是从diffusion生成范式出发,图像生成自然是不在话下,同时引入一个GPT2LMHeadModel作为语言生成器,克服扩散模型在语言生成上效果不够好的问题。伴随着Sora和DiT的大火,让大家又看到了扩散模型更大的潜力。
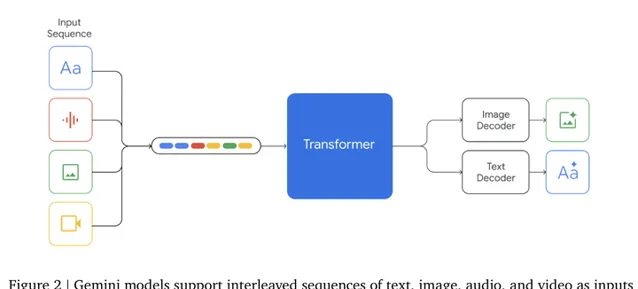
所以两个可谓是殊途同归,在目前没有更好的统一多模态架构出来之前,自回归GPT+扩散模型能够起到优势互补的作用。当然Google在Gemini技术报告里则是说明了自己采用的是原生多模态的方案,将语音、语言、图像全部编码为离散的token,而且也能够自回归地支持图像生成,但是很遗憾在技术报告里并没有看到图像生成的效果,主要还是报告了多模态语言生成的效果。也不排除GPT-4o也是采用了这样大一统的架构。
Emu2代码链接:https:// github.com/baaivision/E mu/tree/main/Emu2

Unidiffuser代码链接:https:// github.com/thu-ml/unidi ffuser

参考文献:
[1]Generative Multimodal Models are In-Context Learners (https:// arxiv.org/abs/2312.1328 6 )
[2]One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale (https:// arxiv.org/abs/2303.0655 5 )
[3]Gemini: A Family of Highly Capable Multimodal Models(https:// arxiv.org/pdf/2312.1180 5 )
[4]Hello GPT-4o (https:// openai.com/index/hello- gpt-4o/ )











