
今天給大家分享一個實用的爬蟲計畫, 批次采集4K桌布 ,從此桌布不愁,張張精品。記得點贊收藏哦,話不多說,盤它!(偷笑)
先上地址:pic.netbian.com/
該網站下載圖片是需要登入的,因此
cookie
的獲取是我們面臨的第一個問題。
獲取cookie
我們使用
selenium
自動獲取
cookie
。
先匯入所需要的模組。
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
開啟網站首頁。
driver = webdriver.Chrome()
driver.get('https://pic.netbian.com/')
F12
開啟開發者工具,定位登入標簽的位置。
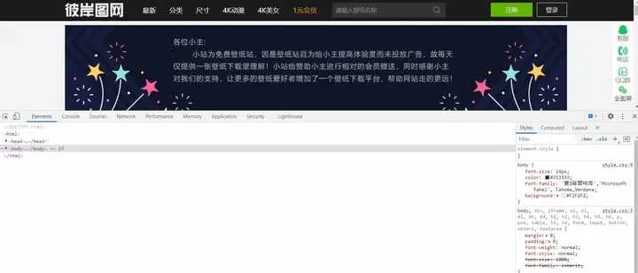
wait = WebDriverWait(driver, 10, 0.5)
wait.until(EC.presence_of_element_located(
(By.XPATH, '/html/body/div[1]/div/div[2]/a[2]')),
message='定位超時').click()
這裏
selenium
開啟頁面速度比較慢,我們可以使用顯示等待,每隔0.5s就檢測一次元素是否存在,超過10s則丟擲異常。
定位QQ登入
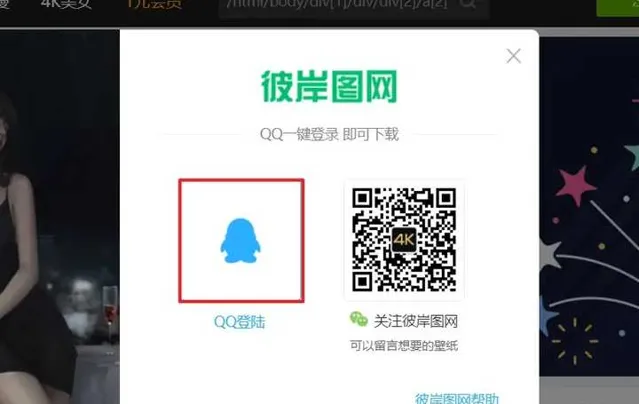
跳轉後點選帳號密碼登入。
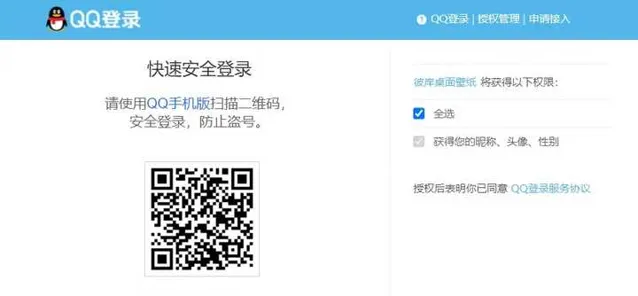
然後定位帳號密碼,點選登入
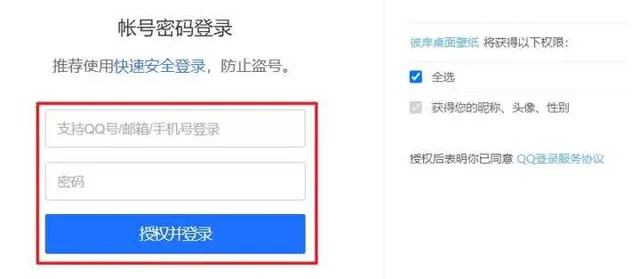
上述步驟程式碼
driver.find_element(By.XPATH, '/html/body/div[1]/div/div[2]/div[1]/div[3]/ul/li[1]/a/em').click()
# 定位頁面標簽,判斷是否跳轉成功
wait.until(EC.presence_of_element_located(
(By.XPATH, '//*[@id="combine_page"]/div[1]/div')),
message='定位超時')
# 切換進入iframe
driver.switch_to.frame('ptlogin_iframe')
# 點選帳號密碼登入
driver.find_element(By.ID, 'switcher_plogin').click()
# 輸入帳號
username = driver.find_element(By.ID, 'u')
username.send_keys('帳號')
# 輸入密碼
password = driver.find_element(By.ID, 'p')
password.send_keys('密碼')
# 點選登入
driver.find_element(By.ID, 'login_button').click()
下一步,我們判斷一下頁面是否跳轉成功,如果成功,就直接獲取頁面的
cookie
。
wait.until(EC.presence_of_element_located(
(By.XPATH, '/html/body/div[1]/div/ul/li[2]/a')),
message='定位超時')
cookies = {}
for item in driver.get_cookies():
cookies[item['name']] = item['value']
print(cookies)
圖片采集
cookie已經獲取到了,現在可以開始圖片的采集了。圖片有很多分類,這次演示采集的是動漫圖片。
首先匯入所需的模組。
import requests
import os
import re
from lxml import etree
在當前路徑下建立一個資料夾保存圖片。
isExists = os.path.exists('./4ktupian')
if not isExists:
os.makedirs('./4ktupian')
我們手動下載一張圖片,觀察一下下載連結。
https://
pic.netbian.com/downpic
.php?id=25487& classid=66
經對比發現,各個圖片下載連結
?
前面的部份都是相同的,
id
是圖片的
id
,
classid
為分類
id
,而動漫這個分類的ID就是66。
唯一需要註意的就是圖片的id,它可以從圖片跳轉的連結上面提取。
OK,基本邏輯理清楚了。
采集部份的程式碼如下,這裏共爬取 15 頁的圖片,300張。
headers = {
'Users-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'
}
for page in range(1, 16):
if (page == 1):
new_url = 'http://pic.netbian.com/4kdongman/'
else:
new_url = format(url % page)
response = requests.get(url=new_url, headers=headers, cookies=cookies)
# 設定獲取響應數據的編碼格式
response.encoding = 'gbk'
page_text = response.text
# 數據解析
tree = etree.HTML(page_text)
li_list = tree.xpath('//ul[@ class="clearfix"]/li')
img_id_list = []
img_name_list = []
for li in li_list:
img_id = li.xpath('./a/@href')[0]
img_id = re.findall('\d+', img_id)[0]
img_id_list.append(img_id)
img_name_list.append(li.xpath('./a/img/@alt')[0])
# 獲取完整圖片url
img_url_list = []
for img_url in img_id_list:
img_url_list.append(f'https://pic.netbian.com/downpic.php?id={img_url}& classid=66')
# 提取圖片數據
for i in range(len(img_url_list)):
img_data = requests.get(url=img_url_list[i], headers=headers, cookies=cookies).content
filePath = './4ktupian/' + img_name_list[i] + '.jpg'
with open(filePath, 'wb')as fp:
fp.write(img_data)
print('%s,下載成功' % img_name_list[i])
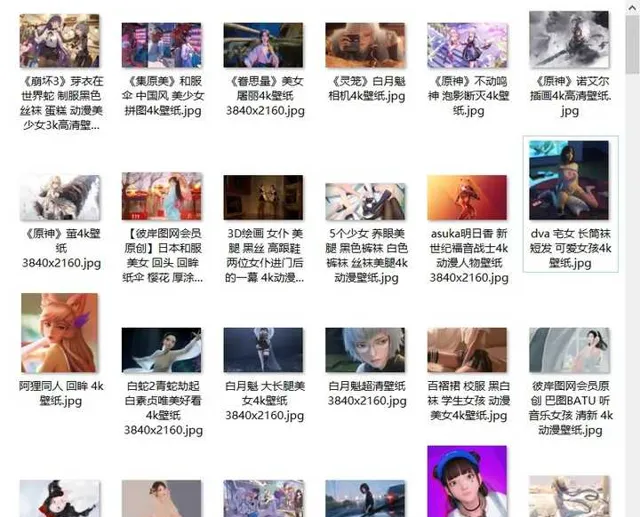
每個圖片大小都在2-4M左右,巨清晰。

看到這,大家別高興得太早,網站提供了會員制,年度會員才能夠每日下載200張,所以,上面的程式碼中理論是下載300張,但實際原畫質的只有240張左右,其余圖片均無法開啟。普通使用者,每日提供一張免費下載原圖的機會。
考慮到維護一個網站確實不容易,我也贊助了一下,贈送了包年會員,每天200次下載機會,但手動下載200張確實也不現實,所以才有了這篇文章。哈哈,大家全當學技術就好啦。
文中程式碼已全部整理好,采集的圖片,也已經打包好了,有需要話











