中國科大 LUG 的
@高一凡在 LUG HTTP 代理伺服器上部署了 Linux 4.9 的 TCP BBR 擁塞控制演算法。從科大的移動出口到新加坡 DigitalOcean 的實測下載速度 從 647 KB/s 提高到了 22.1 MB/s (螢幕擷取如下)。

(應評論區各位 dalao 要求,補充測試環境說明:是在新加坡的伺服器上設定了 BBR, 新加坡的伺服器是數據的發送方 。這個伺服器是存取墻外資源的 HTTP 代理。科大移動出口到 DigitalOcean 之間不是 dedicated 的專線,是走的公網,科大移動出口這邊是 1 Gbps 無限速(但是要跟其他人 share),DigitalOcean 實測是限速 200 Mbps。RTT 是 66 ms。實測結果這麽好,也是因為大多數人用的是 TCP Cubic (Linux) / Compound TCP (Windows), 在有一定丟包率的情況下,TCP BBR 更加激進,搶占了更多的公網頻寬 。因此也是有些不道德的感覺。)
此次 Google 送出到 Linux 主線並行表在 ACM queue 期刊上的 TCP BBR 擁塞控制演算法,繼承了 Google 「先在生產環境部署,再開源和發論文」 的研究傳統。TCP BBR 已經在 Youtube 伺服器和 Google 跨數據中心的內部廣域網路(B4)上部署。
TCP BBR 致力於解決兩個問題:
- 在有一定丟包率的網路鏈路上充分利用頻寬。
- 降低網路鏈路上的 buffer 占用率,從而降低延遲。
TCP 擁塞控制的目標是最大化利用網路上瓶頸鏈路的頻寬。一條網路鏈路就像一條水管,要想用滿這條水管,最好的辦法就是給這根水管灌滿水,也就是:
水管內的水的數量 = 水管的容積 = 水管粗細 × 水管長度
換成網路的名詞,也就是:
網路內尚未被確認收到的封包數量 = 網路鏈路上能容納的封包數量 = 鏈路頻寬 × 往返延遲
TCP 維護一個 發送視窗 ,估計當前網路鏈路上能容納的封包數量,希望在有數據可發的情況下,回來一個確認包就發出一個封包,總是保持發送視窗那麽多個包在網路中流動。
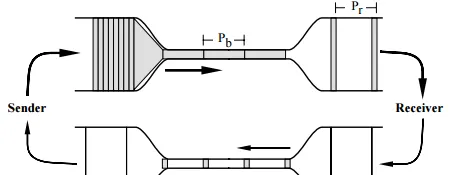
TCP 與水管的類比示意(圖片來源:Van Jacobson,Congestion Avoidance and Control,1988)
如何估計水管的容積呢?一種大家都能想到的方法是不斷往裏灌水,直到溢位來為止。標準 TCP 中的擁塞控制演算法也類似: 不斷增加發送視窗,直到發現開始丟包 。這就是所謂的 」加性增,乘性減」,也就是當收到一個確認訊息的時候慢慢增加發送視窗,當確認一個包丟掉的時候較快地減小發送視窗。
標準 TCP 的這種做法有兩個問題:
首先,假定網路中的丟包都是由於擁塞導致(網路裝置的緩沖區放不下了,只好丟掉一些封包)。事實上網路中有可能存在傳輸錯誤導致的丟包,基於丟包的擁塞控制演算法並不能區分 擁塞丟包 和 錯誤丟包 。在數據中心內部,錯誤丟包率在十萬分之一(1e-5)的量級;在廣域網路上,錯誤丟包率一般要高得多。
更重要的是,「加性增,乘性減」 的擁塞控制演算法要能正常工作, 錯誤丟包率需要與發送視窗的平方成反比 。數據中心內的延遲一般是 10-100 微秒,頻寬 10-40 Gbps,乘起來得到穩定的發送視窗為 12.5 KB 到 500 KB。而廣域網路上的頻寬可能是 100 Mbps,延遲 100 毫秒,乘起來得到穩定的發送視窗為 10 MB。廣域網路上的發送視窗比數據中心網路高 1-2 個數量級,錯誤丟包率就需要低 2-4 個數量級才能正常工作。因此標準 TCP 在有一定錯誤丟包率的 長肥管道(long-fat pipe,即延遲高、頻寬大的鏈路) 上只會收斂到一個很小的發送視窗。這就是很多時候客戶端和伺服器都有很大頻寬,營運商核心網路也沒占滿,但下載速度很慢,甚至下載到一半就沒速度了的一個原因。
其次,網路中會有一些 buffer,就像輸液管裏中間膨大的部份,用於吸收網路中的流量波動。由於標準 TCP 是透過 「灌滿水管」 的方式來估算發送視窗的,在連線的開始階段,buffer 會被傾向於占滿。後續 buffer 的占用會逐漸減少,但是並不會完全消失。客戶端估計的水管容積(發送視窗大小)總是略大於水管中除去膨大部份的容積。這個問題被稱為 bufferbloat(緩沖區膨脹) 。

緩沖區膨脹現象圖示
緩沖區膨脹有兩個危害:
- 增加網路延遲 。buffer 裏面的東西越多,要等的時間就越長嘛。
- 共享網路瓶頸的連線較多時,可能導致 緩沖區被填滿而丟包 。很多人把這種丟包認為是發生了網路擁塞,實則不然。
往返延遲隨時間的變化。 紅線:標準 TCP(可見周期性的延遲變化,以及 buffer 幾乎總是被填滿);綠線:TCP BBR
(圖片引自 Google 在 ACM queue 2016 年 9-10 月刊上的論文 [1],下同)
有很多論文提出在網路裝置上把當前緩沖區大小的資訊反饋給終端,比如在數據中心廣泛套用的 ECN(Explicit Congestion Notification)。然而廣域網路上網路裝置眾多,更新換代困難,需要網路裝置介入的方案很難大範圍部署。
TCP BBR 是怎樣解決以上兩個問題的呢?
-
既然不容易區分擁塞丟包和錯誤丟包,TCP BBR 就幹脆不考慮丟包。
- 既然灌滿水管的方式容易造成緩沖區膨脹,TCP BBR 就分別估計頻寬和延遲,而不是直接估計水管的容積。
頻寬和延遲的乘積就是發送視窗應有的大小。發明於 2002 年並已進入 Linux 內核的 TCP Westwood 擁塞控制演算法,就是分別估計頻寬和延遲,並計算其乘積作為發送視窗。然而 頻寬和延遲就像粒子的位置和動量,是沒辦法同時測準的 :要測量最大頻寬,就要把水管灌滿,緩沖區中有一定量的封包,此時延遲就是較高的;要測量最低延遲,就要保證緩沖區為空,網路裏的流量越少越好,但此時頻寬就是較低的。
TCP BBR 解決 頻寬和延遲無法同時測準 的方法是: 交替測量頻寬和延遲;用一段時間內的頻寬極大值和延遲極小值作為估計值。
在連線剛建立的時候,TCP BBR 采用類似標準 TCP 的 慢啟動 ,指數增長發送速率。然而標準 TCP 遇到任何一個丟包就會立即進入擁塞避免階段,它的本意是填滿水管之後進入擁塞避免,然而(1)如果鏈路的錯誤丟包率較高,沒等到水管填滿就放棄了;(2)如果網路裏有 buffer,總要把緩沖區填滿了才會放棄。
TCP BBR 則是根據收到的確認包,發現有效頻寬不再增長時,就進入擁塞避免階段。(1)鏈路的錯誤丟包率只要不太高,對 BBR 沒有影響;(2)當發送速率增長到開始占用 buffer 的時候,有效頻寬不再增長,BBR 就及時放棄了(事實上放棄的時候占的是 3 倍頻寬 × 延遲,後面會把多出來的 2 倍 buffer 清掉),這樣就不會把緩沖區填滿。
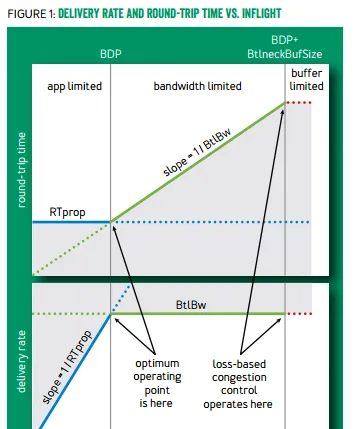
發送視窗與往返延遲和有效頻寬的關系。BBR 會在左右兩側的拐點之間停下,基於丟包的標準 TCP 會在右側拐點停下(圖片引自 TCP BBR 論文,下同)
在慢啟動過程中,由於 buffer 在前期幾乎沒被占用,延遲的最小值就是延遲的初始估計;慢啟動結束時的最大有效頻寬就是頻寬的初始估計。
慢啟動結束後,為了把多占用的 2 倍頻寬 × 延遲消耗掉,BBR 將進入 排空(drain)階段 ,指數降低發送速率,此時 buffer 裏的包就被慢慢排空,直到往返延遲不再降低。如下圖綠線所示。
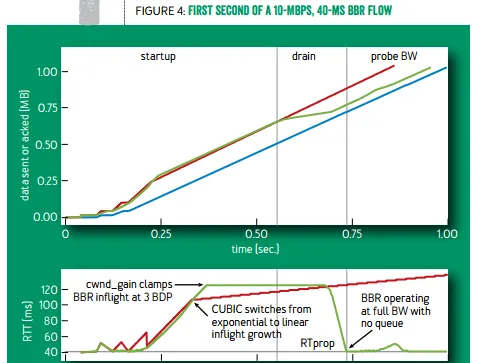
TCP BBR(綠線)與標準 TCP(紅線)有效頻寬和往返延遲的比較
排空階段結束後,BBR 進入穩定執行狀態,交替探測頻寬和延遲。由於網路頻寬的變化比延遲的變化更頻繁, BBR 穩定狀態的絕大多數時間處於頻寬探測階段 。頻寬探測階段是一個正反饋系統:定期嘗試增加發包速率,如果收到確認的速率也增加了,就進一步增加發包速率。
具體來說,以每 8 個往返延遲為周期,在第一個往返的時間裏,BBR 嘗試增加發包速率 1/4(即以估計頻寬的 5/4 速度發送)。在第二個往返的時間裏,為了把前一個往返多發出來的包排空,BBR 在估計頻寬的基礎上降低 1/4 作為發包速率。剩下 6 個往返的時間裏,BBR 使用估計的頻寬發包。
當網路頻寬增長一倍的時候,每個周期估計頻寬會增長 1/4,每個周期為 8 個往返延遲。其中向上的尖峰是嘗試增加發包速率 1/4,向下的尖峰是降低發包速率 1/4(排空階段),後面 6 個往返延遲,使用更新後的估計頻寬。3 個周期,即 24 個往返延遲後,估計頻寬達到增長後的網路頻寬。
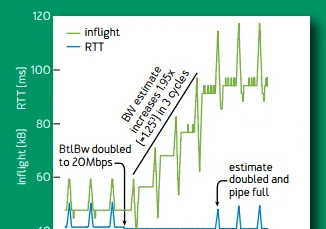
網路頻寬增長一倍時的行為。綠線為網路中包的數量,藍線為延遲
當網路頻寬降低一半的時候,多出來的包占用了 buffer,導致網路中包的延遲顯著增加(下圖藍線),有效頻寬降低一半。延遲是使用極小值作為估計,增加的實際延遲不會反映到估計延遲(除非在延遲探測階段,下面會講)。頻寬的估計則是使用一段滑動視窗時間內的極大值,當之前的估計值超時(移出滑動視窗)之後,降低一半後的有效頻寬就會變成估計頻寬。估計頻寬減半後,發送視窗減半,發送端沒有視窗無法發包,buffer 被逐漸排空。
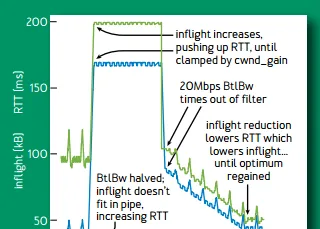
網路頻寬降低一半時的行為。 綠線為網路中包的數量,藍線為延遲
當頻寬增加一倍時,BBR 僅用 1.5 秒就收斂了;而當頻寬降低一半時,BBR 需要 4 秒才能收斂。 前者由於頻寬增長是指數級的;後者主要是由於頻寬估計采用滑動視窗內的極大值,需要一定時間有效頻寬的下降才能反饋到頻寬估計中。
當網路頻寬保持不變的時候,穩定狀態下的 TCP BBR 是下圖這樣的:(我們前面看到過這張圖)可見每 8 個往返延遲為周期的延遲細微變化。
往返延遲隨時間的變化。 紅線:標準 TCP;綠線:TCP BBR
上面介紹了 BBR 穩定狀態下的頻寬探測階段,那麽什麽時候探測延遲呢?在頻寬探測階段中,估計延遲始終是使用極小值,如果實際延遲真的增加了怎麽辦?TCP BBR 每過 10 秒,如果估計延遲沒有改變(也就是沒有發現一個更低的延遲),就進入延遲探測階段。延遲探測階段持續的時間僅為 200 毫秒(或一個往返延遲,如果後者更大),這段時間裏發送視窗固定為 4 個包,也就是幾乎不發包。這段時間內測得的最小延遲作為新的延遲估計。也就是說, 大約有 2% 的時間 BBR 用極低的發包速率來測量延遲 。
TCP BBR 還使用 pacing 的方法降低發包時的 burstiness ,減少突然傳輸的一串包導致緩沖區膨脹。發包的 burstiness 可能由兩個原因引起:
- 數據接收方為了節約頻寬,把多個確認(ACK)包累積成一個發出,這叫做 ACK Compression。數據發送方收到這個累積確認包後,如果沒有 pacing,就會發出一連串的封包。
- 數據發送方沒有足夠的數據可傳輸,積累了一定量的空閑發送視窗。當套用層突然需要傳輸較多的數據時,如果沒有 pacing,就會把空閑發送視窗大小這麽多數據一股腦發出去。
下面我們來看 TCP BBR 的效果如何。
首先看 BBR 試圖解決的第一個問題:在有隨機丟包情況下的吞吐量。如下圖所示, 只要有萬分之一的丟包率,標準 TCP 的頻寬就只剩 30%;千分之一丟包率時只剩 10%;有百分之一的丟包率時幾乎就卡住了。而 TCP BBR 在丟包率 5% 以下幾乎沒有頻寬損失,在丟包率 15% 的時候仍有 75% 頻寬 。

100 Mbps,100ms 下的丟包率和有效頻寬(紅線:標準 TCP,綠線:TCP BBR)
異地數據中心間跨廣域網路的傳輸往往是高頻寬、高延遲的,且有一定丟包率,TCP BBR 可以顯著提高傳輸速度 。這也是中國科大 LUG HTTP 代理伺服器和 Google 廣域網路(B4)部署 TCP BBR 的主要原因。
再來看 BBR 試圖解決的第二個問題: 降低延遲,減少緩沖區膨脹 。如下圖所示, 標準 TCP 傾向於把緩沖區填滿,緩沖區越大,延遲就越高 。當使用者的網路接入速度很慢時,這個延遲可能超過作業系統連線建立的超時時間,導致連線建立失敗。使用 TCP BBR 就可以避免這個問題。
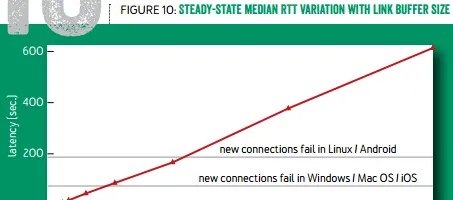
緩沖區大小與延遲的關系(紅線:標準 TCP,綠線:TCP BBR)
Youtube 部署了 TCP BBR 之後,全球範圍的中位數延遲降低了 53%(也就是快了一倍),開發中國家的中位數延遲降低了 80%(也就是快了 4 倍)。從下圖可見, 延遲越高的使用者,采用 TCP BBR 後的延遲下降比例越高,原來需要 10 秒的現在只要 2 秒了 。如果您的網站需要讓用 GPRS 或者慢速 WiFi 接入網路的使用者也能流暢存取,不妨試試 TCP BBR。
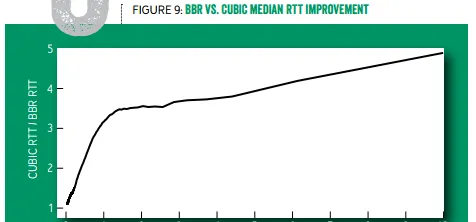
標準 TCP 與 TCP BBR 的往返延遲中位數之比
綜上, TCP BBR 不再使用丟包作為擁塞的訊號,也不使用 「加性增,乘性減」 來維護發送視窗大小,而是分別估計極大頻寬和極小延遲,把它們的乘積作為發送視窗大小。
BBR 的連線開始階段由慢啟動、排空兩階段構成。為了解決頻寬和延遲不易同時測準的問題,BBR 在連線穩定後交替探測頻寬和延遲,其中探測頻寬階段占絕大部份時間,透過正反饋和周期性的頻寬增益嘗試來快速響應可用頻寬變化;偶爾的探測延遲階段發包速率很慢,用於測準延遲。
BBR 解決了兩個問題:
- 在有一定丟包率的網路鏈路上充分利用頻寬。非常適合高延遲、高頻寬的網路鏈路。
- 降低網路鏈路上的 buffer 占用率,從而降低延遲。非常適合慢速接入網路的使用者。
看到評論區很多客戶端和伺服器哪個部署 TCP BBR 有效的問題,需要提醒: TCP 擁塞控制演算法是數據的發送端決定發送視窗,因此在哪邊部署,就對哪邊發出的數據有效。 如果是下載,就應在伺服器部署;如果是上傳,就應在客戶端部署。
如果希望加速存取國外網站的速度,且下載流量遠高於上傳流量,在客戶端上部署 TCP BBR(或者任何基於 TCP 擁塞控制的加速演算法)是沒什麽效果的。需要在 VPN 的國外出口端部署 TCP BBR,並做 TCP Termination & TCP Proxy。也就是客戶建立連線事實上是跟 VPN 的國外出口伺服器建聯,國外出口伺服器再去跟目標伺服器建聯,使得丟包率高、延遲大的這一段(從客戶端到國外出口)是部署了 BBR 的國外出口伺服器在發送數據。或者在 VPN 的國外出口端部署 BBR 並做 HTTP(S) Proxy,原理相同。
大概是由於 ACM queue 的篇幅限制和目標讀者,這篇論文並沒有討論(僅有擁塞丟包情況下)TCP BBR 與標準 TCP 的公平性。也沒有討論 BBR 與現有擁塞控制演算法的比較,如基於往返延遲的(如 TCP Vegas)、綜合丟包和延遲因素的(如 Compound TCP、TCP Westwood+)、基於網路裝置提供擁塞資訊的(如 ECN)、網路裝置采用新排程策略的(如 CoDel)。期待 Google 發表更詳細的論文,也期待各位同行報告 TCP BBR 在實驗或生產環境中的效能。
本人不是 TCP 擁塞控制領域的專家,如有錯漏不當之處,懇請指正。
[1] Cardwell, Neal, et al. "BBR: Congestion-Based Congestion Control." Queue 14.5 (2016): 50.











