唉。死不悔改,而且一錯再錯。
首先,問題是錯的。我在另一個貼文裏
Windows 10 給 Linux 子系統寫顯卡驅動的是一個人嗎,是誰呢?提到的是Direct3D9/11的驅動,是給Drawbridge寫的,而不是Linux子系統。他們在發展上有個先後的關系,但不是一個東西。題主對此完全一知半解的情況下,不仔細看就斷章取義,實在太胡攪蠻纏。
其次,不擼兔子的說法,基本每個點都是錯誤的。
「parrallels的虛擬顯卡最多只是把OpenGL呼叫轉發到宿主機上。「
不,那麽做行不通。(甚至parallels都拼錯了)
」Linux子系統和Windows子系統在內核看來是同等地位的。應該不需要搞這套東西才對。」
不,Linux子系統在Picoprocess裏。Linux子系統和Windows本身是guest和host的關系。
「不提供CUDA真正的原因肯定不是不想做。而是已經做好了」
不,根本沒寫。而且如果你懂CUDA的話,就知道轉API容易,難點是視訊記憶體存取和管理。
「只是把Library OS裏面的呼叫轉發到外面。「
不,那麽做行不通。
好了,現在我就來說說為什麽直接把API呼叫轉到外面行不通。會有很多細節,像題主和不擼兔子這樣沒做過的人根本不會了解。
1. 流量。
API呼叫看似簡單,只要把所有的API都轉出去,就行了。原先遠端桌面就是這麽做的。但缺點是,API呼叫所要消耗的流量遠大於在驅動層搞。舉個例子,把同一個設定狀態呼叫兩次,你就得在API層轉兩次。最多就是cache一下,把變化的傳了。而在D3D的體系裏,有runtime做狀態管理,只會把真正修改了有起作用的狀態往下傳給驅動,並會做嚴格的狀態驗證。所以在驅動層,你所需要轉的數據遠少於API層。
2. 出錯控制。
如果執行過程出了嚴重問題,你需要的是不讓host crash,最多讓guest crash。如果從API層走,那麽這件事情無法避免。如果guest裏有多了個驗證,就會把錯誤留在子系統,而不會傳出來。
3. bug-to-bug相容
如果只是API層,那麽要求guest和host的runtime完全一致,才可以保證100%相容。而從驅動走,runtime是在guest,那麽只要都符合WDDM,就沒問題。guest和host的runtime可以解耦。
4. 什麽是驅動。
驅動不在於你怎麽實作,你是直接去真實硬體,還去了虛擬硬體。只要是按照驅動的規範實作、編譯、部署,系統看到的是個裝置,那就是驅動。我給Drawbridge寫的第一版,是可以在普通的Windows上裝的,你能在裝置管理員裏看到多了一塊顯卡,程式可以在上面建立裝置,進行渲染。(由於沒有實作電源管理的部份,在休眠後會睡死)
這裏放一張WDDM的架構圖。驅動需要實作的是user-mode display driver(UMD)和Display miniport driver(KMD)。OpenGL installable client driver屬於可選。
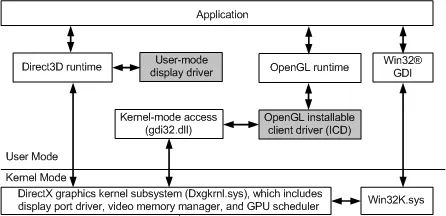
從這張圖也可以看到,你如果從API層面轉(也就是D3D runtime和OpenGL runtime),那麽系統並不會認為你是個裝置,也沒法按照系統的規範去使用你這個裝置。那就不是個驅動,也沒法實作完整的功能。
另一個嚴重問題是,GDI的部份你怎麽辦。GDI是直接呼叫win32k,win32k又會透過dxgkrnl去呼叫KMD。難道想連GDI都一起轉出來?
到了Android上,情況會更遭。Android的驅動介面和OpenGLES很像,所以從表面上看,從驅動層和從API層區別不大。但遭就遭在不同的那一點點。首先是系統有一些私有介面,只有surface flinger等android系統內會呼叫,而host不會有對應的。這得在驅動裏解決。第二,android上的視訊記憶體管理是由驅動做的,不但host沒有對應,其他裝置也會直接呼叫視訊記憶體管理做一些事情,比如說網路攝影機。這都不可能透過API層面實作。必須提供一個驅動讓系統使用。
總的來說,比起API層,驅動層至少要有狀態管理和command list,以及可能要有視訊記憶體管理。這些,我寫的驅動裏都有。
5. 如何傳輸數據
不要以為host和guest都在一台電腦,傳輸數據就很容易。圖形的東西數據量之大,API呼叫次數之多,都是遠遠超過其他方面的API的。還要考慮異構(CPU和GPU)上的延遲,傳輸數據這方面根本不trival。
前面提到的command list,就是一部份必做的事情。如果來一個API呼叫,就穿一次,即便memcpy也受不了。更好地實作是放到一個列表,只有在某些需要同步的呼叫下才把整個command list發送出去。我的實驗是,用和沒用,效能差6倍。另一方面是對於大塊的數據,紋理、vb,host和guest之間如何直接對映,減少拷貝而又不影響安全性,這都是得考慮的事情。
以上這幾點不光對D3D有效,對OpenGL/OpenGLES也有效。換句話說,不管什麽系統,都應該在驅動層,而不是API層做這件事情。否則死路一條。
而在CUDA方面,更難處理。因為不像D3D/OGL,texture和buffer這些都是用封裝過後的形態表示(D3D用的物件,OGL用的id),只要建立一個host和guest的對映,之後在上面的操作就能連上。CUDA裏面你可以申請一塊視訊記憶體,接著就用指標到處指了。所以需要仔細做全視訊記憶體所有權分析和數據對映。這些問題別說解決,連發現都不容易。
少年,你們仍然對力量一無所知。











