這就是amazon發明的「喜歡這個商品的人,也喜歡某某」演算法。
其核心是數學中的「多維空間中兩個向量夾角的余弦公式」,當初我的確是被這演算法驚艷到了。
=============2014-12-01 更新 =============================
不好意思,之前說的有誤,特來更正兼補充。
「商品推薦」系統的演算法(
Collaborative filtering)分兩大類,
第一類,以人為本,先找到與你相似的人,然後看看他們買了什麽你沒有買的東西。這類演算法最經典的實作就是「多維空間中兩個向量夾角的余弦公式」;
第二類, 以物為本直接建立各商品之間的相似度關系矩陣。這類演算法中最經典是'斜率=1' (
Slope One)。amazon發明了暴力簡化的第二類演算法,‘買了這個商品的人,也買了xxx’。
我們先來看看第一類,最大的問題如何判斷並量化兩人的相似性,思路是這樣 --
例子:
有3首歌放在那裏,【最炫民族風】,【晴天】,【Hero】。
A君,收藏了【最炫民族風】,而遇到【晴天】,【Hero】則總是跳過;
B君,經常單曲迴圈【最炫民族風】,【晴天】會播放完,【Hero】則拉黑了
C君,拉黑了【最炫民族風】,而【晴天】【Hero】都收藏了。
我們都看出來了,A,B二位品味接近,C和他們很不一樣。
那麽問題來了,說A,B相似,到底有多相似,如何量化?
我們把三首歌想象成三維空間的三個維度,【最炫民族風】是x軸,【晴天】是y軸,【Hero】是z軸,對每首歌的喜歡程度即該維度上的座標,
並且對喜歡程度做量化(比如: 單曲迴圈=5, 分享=4, 收藏=3, 主動播放=2 , 聽完=1, 跳過=-1 , 拉黑=-5 )。
那麽每個人的總體口味就是一個向量,A君是 (3,-1,-1),B君是(5,1,-5),C君是(-5,3,3)。 (抱歉我不會畫立體圖)
我們可以用向量夾角的余弦值來表示兩個向量的相似程度, 0度角(表示兩人完全一致)的余弦是1, 180%角(表示兩人截然相反)的余弦是-1。
根據余弦公式, 夾角余弦 = 向量點積/ (向量長度的叉積) = ( x1x2 + y1y2 + z1z2) / ( 跟號(x1平方+y1平方+z1平方 ) x 跟號(x2平方+y2平方+z2平方 ) )
可見 A君B君夾角的余弦是0.81 , A君C君夾角的余弦是 -0.97 ,公式誠不欺我也。
以上是三維(三首歌)的情況,如法炮製N維N首歌的情況都是一樣的。
假設我們選取一百首種子歌曲,算出了各君之間的相似值,那麽當我們發現A君還喜歡聽的【小蘋果】B君居然沒聽過,相信大家都知道該怎麽和B君推薦了吧。
第一類以人為本推薦演算法的好處我想已經很清楚了,那就是精準!
代價是運算量很大,而且對於新來的人(聽得少,動作少),也不太好使,
所以人們又發明了第二類演算法。
假設我們對新來的D君,只知道她喜歡最炫民族風,那麽問題來了,給她推薦啥好咯?
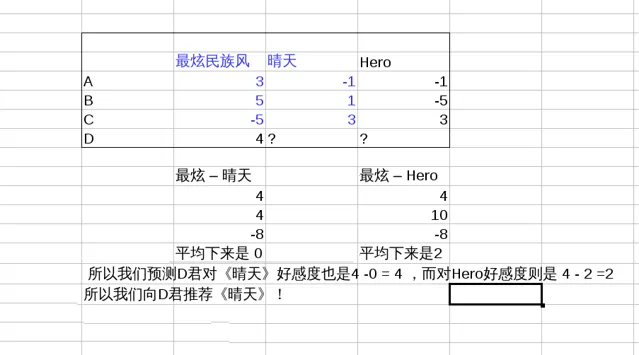
如圖,推薦【晴天】!
呵呵,第二類演算法的好處大家也看出來了,簡單粗暴好操作(也適合map-reduce),可精度差了點。
所以,各家網站真正的推薦演算法,是他們在綜合上述兩類演算法的基礎上,各自研制並且不斷地改進調節的,外人不得而知! ^_^
=== 2014-12-03 再補充 ===
多謝 @劉彥彬 給了一個非常專業的評論 ,不貼出來可惜了。
「這個只能說是理論基礎。歌曲不考慮熱門冷門,同時不考慮使用者數和歌曲數計算復雜度的話第一一天內離線數據計算不完的(當然網易雲音樂使用者量小全量暴力計算當我沒說),實際套用起來復雜很多了。現在的推薦系統並不存在一種演算法通吃,除了演算法上的問題,還需要考慮基礎數據的影響因素,比如兩張歌單有多少歌曲重合,歌單的品質是怎麽樣的。」
我上一帖也說了,
'向量夾角余弦' 解決的是‘量化顧客口味相似度’的問題(是最經典的解法,也有別的解法),
不是有了它就能輕易實作第一類演算法的,難處在後面咯。
我不是幹‘CF/演算法/資料探勘/互聯網’的,只是幾年前偶爾瞄到過這方面文章被驚艷了一下,
見到這題就隨口抖了個機靈,然後被評論區幾位帶板凳來的朋友給推上來了 ^_^
既然大家都這麽有興趣,我在來拋塊磚,說說‘有了理論基礎之後咋整’的思(nao3)考(dong4)。
繼續第一類演算法的話題,目標「每日歌曲推薦」(其實題主感興趣的是這個吧,旁邊‘根據你喜歡的xxx推薦的yyy歌單’我覺得不咋樣)。
首先就是如何定維度。
直接用‘歌’當維度是不行的,第一是太多了算不過來,第二維度數一直猛漲也不是個事。
用‘歌單’或者‘專輯’,‘演唱/演奏者’呢?也有類似的困難。
說到這裏大家應該都意識到了,咱不是還有‘tag’嘛!
雲音樂初期,tag是可以由大家自己填的,我記得我填過‘莫札特’,‘鋼協’,‘交響’這樣的tag,現在都不見了吧。
一段時間之後,tag無法自填了,只能從雲音樂給的tag lib中選,這肯定有原因的。
我的推測就是,他們需要用tag來當作維度,所以不希望tag數經常變化。
第一階段,他們需要搜集使用者的輸入來做出tag lib,
第二階段,他們構建了多維度空間,就不希望再動維度了,因此關閉了自填tag的功能。
假設就用tag做為維度,那麽第二個難處在於,維度上的'刻度'必須有正有負才好使,
使用者沒有機會直接表達對tag的好惡(不能收藏,播放,跳過一個tag),如何定刻度呢。
我認為每一首歌背後是有其所屬tags這個內容的,這個內容在UI上看不到很可能是因為比較容易引起口水。
歌往往隸屬於很多歌單,而那些歌單都是有tags的,根據那些歌單的播放數收藏數分享數可以決定其'權威性',
取'權威性'高的歌單的tag,就可以得到每首歌的tag內容。
然後使用者在表達對一首首歌的好惡的時候,其實就不知不覺地影響了他在相應維度上的刻度。
假設維度和刻度都這樣解決,那麽我們可以對每個使用者做出‘口味向量’了,接下來的難處是,
啥時候算/如何保存‘使用者相似性’?
所有使用者兩兩算一下相似性,存為一個NxN的矩陣,這種事情不是鬧這玩的。
其實到了這一步,不考慮‘以人為本’,直接根據我喜歡的tag,從各tag裏挑一些人氣高的,或者躥升快的歌來推薦也算是能交差了。
不過那樣的話,就容易同質化,也就不易讓使用者‘驚艷’了。
讓我們繼續沿著第一類演算法的思路琢磨琢磨。
多維度空間還有一大好處是,有‘像限’這種的概念,
比如我們可以粗暴地假設,和我同一個像限的人,就是和我‘相似’的人,
如果因為維度太多,或者初期使用者太少等原因找不到同像限的人, 還可以去‘相鄰’的像限找嘛。
OK,假設我們根據tag以及自己的像限,找到了一批和自己‘氣味相投’的人。
再叢這批人中,選幾個‘和我夾角余弦’最大(再綜合一下個人名聲比如星標,粉絲數,和我的互動度等,更好)的人,
從他們聽過而我沒聽過的歌中,再選一批 他們喜歡,或者他們新聽到,新收藏,或者總人氣高的等等,
就可以說是「根據我的口味生成」的「每日歌曲推薦」了。
以上內容,均是臆測,如果雷同,純屬巧合 ^_^











