1. 一個很酷的技術: SpeecpFace [1]
這是一種新的神經網路模型,試圖透過某個人的語音來重現其面孔。
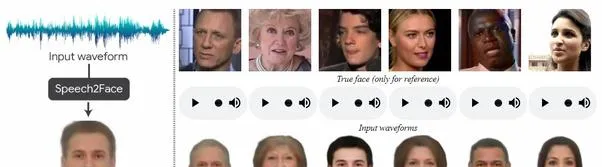
可以看到,雖然結果並不是完美的,但相似之處也是顯而易見的。
ta是由麻省理工學院開發的,相關的研究論文 [2] 於2019年5月底發表。利用了數百萬來自YouTube和其他來源的視訊片段被用來訓練這個模型。
如果有足夠的數據,計算能力和時間,神經網路可以透過分析視訊片段,將聲音與面部配對以及找到兩者之間的模式和趨勢來「學習」如何重建人臉。
模型所生成的臉部會準確地重建鼻子,嘴唇,臉頰和骨骼等結構,除了眼睛之外,其余全部都可以重建。這個ML模型之所以能夠work,是因為準確表示的特征在外觀和語音之間具有直接相關性。例如,聲音較深的人可能比聲音較高的人有更寬的鼻子或下巴,而眼睛的形狀和大小通常不會對某人的發音產生太大影響,這也是眼睛的重建工作不夠準確的原因。
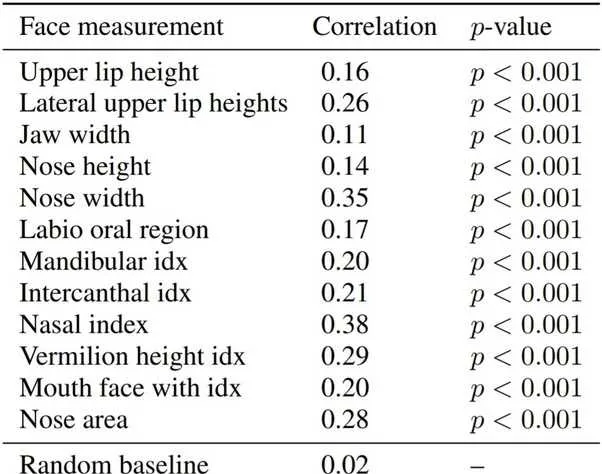
下面是作者列出的所有相關特征。相關性從-1到1,0為不相關,1為絕對相關性:
可以想象這樣一個場景,你正在打電話和某個素不相識的妹子交談。
聽著她的輕聲細語,你大機率在腦海中腦補出這樣一幅場景:一位性格內斂,皮膚白晰,骨骼纖細,柔弱水靈,從小說吳儂軟語長大的妹子,正撐著油紙傘走在寂靜的雨巷。
與此同時,一幅典型的南方溫婉姑娘的長相,想必也早已浮現在你的腦海裏。
雖然你腦海中的形象可能與我的有所不同,但重要的是,我們兩個都針對具有南方輕柔口音的女生提出了一些通用的「平均」形象。她可能是你平時遇到過或者相識的南方女生形象,或者某幾個形象的組合。
這就是目前SpeecpFace的工作方式,但是它有多達數百倍的模式可供考慮。其實我們的大腦已經可以部份完成SpeecpFace的工作,例如能夠僅透過聲音來辨識我們的同學朋友等。
這是SpeecpFace的其他一些結果:

現在有些工作試圖將SpeecpFace與Nvidia的GAN [3] (生成對抗網路)結合起來:

上面所有這些面孔都是由GAN生成的,它們都不存在於現實生活中。它們是神經網路輸出的結果,該神經網路充分了解了實際人類的常見特征和模式,可以自行建立它們。甚至可以將神經網路的輸出發送回輸入,以進一步對其自身進行訓練,從而為訓練提供幾乎無限的數據。
GAN可以建立不存在的人類面孔,SpeecpFace可以透過聲音來構建面孔。WaveNet [4] 已經可以構建接近真實的人聲了,他們的結合現在看來只是時間問題。
也許在不到10年的時間裏,我們可能就有能力創造出一個聲音和外表都和真實人類一樣的人造生命,而且很難分辨出其中的區別,不會有大叔面孔蘿莉發音這種事情發生。
2. 另外, GAN (生成對抗網路)必須值得一提
盡管有答主已經介紹過了,但是有一些套用我想再分享一下:
GAN是Ian Goodfellow在2014年提出的深度學習領域中一個相對較新的概念,從那時起,它就動搖了套用於影像,文本和音訊的AI。簡而言之,GAN是一種神經網路,它會生成與訓練集中的數據相同的偽隨機變量。例如:
動態肖像:

虛假演講:

甚至是不存在的人類形象:

3. 還有,Nvidia的 GauGAN 也是一個極其有趣的套用
今年早些時候,Nvidia開發了一種名為GauGAN的AI,它可以透過粗糙的塗鴉來建立逼真的風景。看看下面的範例:
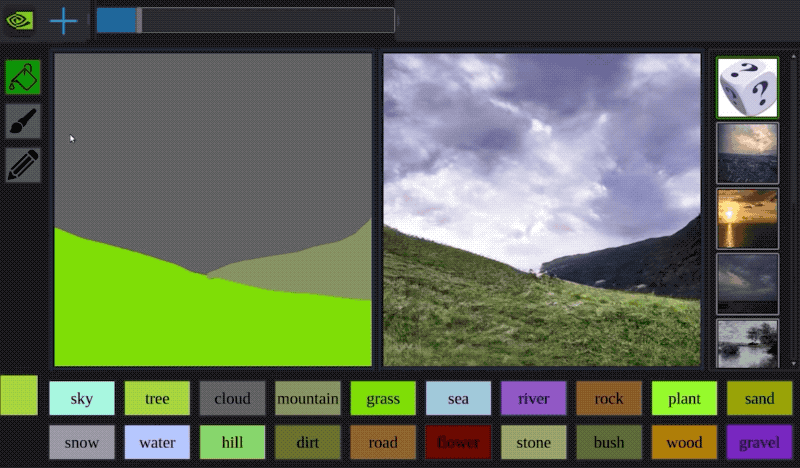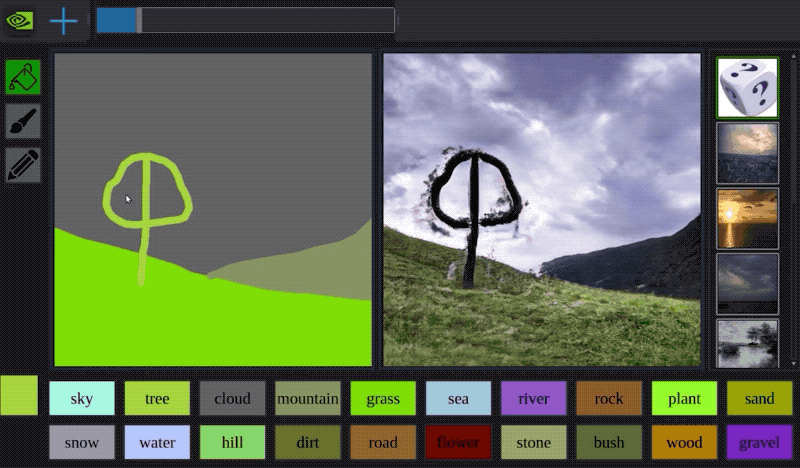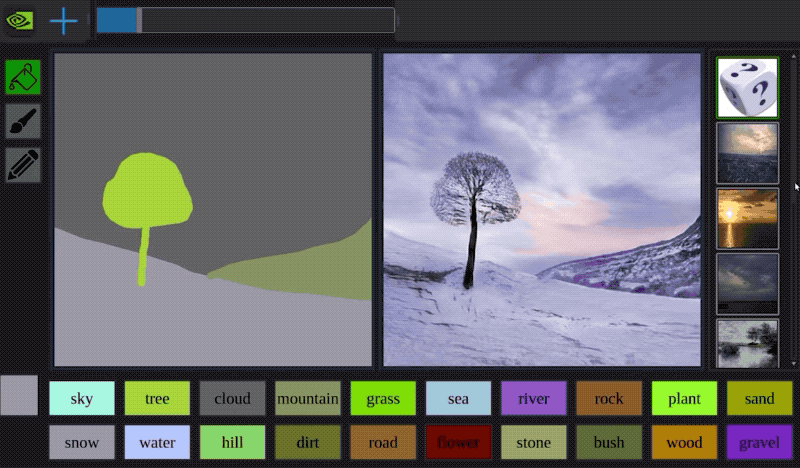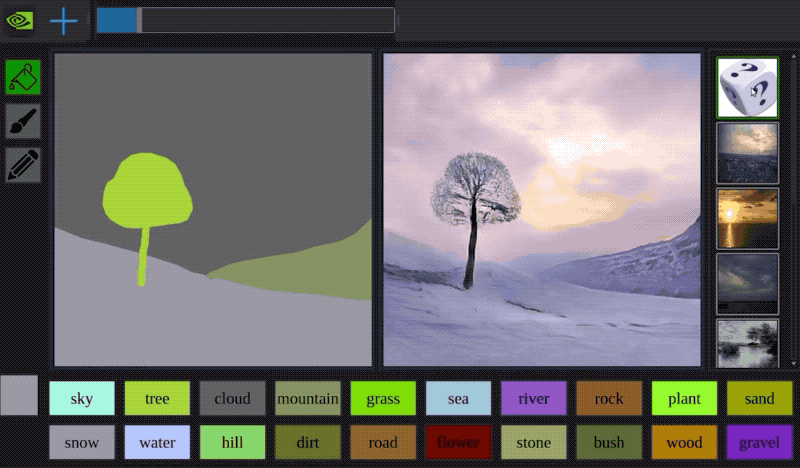
該系統使用生成對抗神經網路將粗糙的分割圖轉換為真實的世界。
It is like a coloring book picture that describes where a tree is, where the sun is, where the sky is, and then the neural network is able to fill in all of the detail and texture, and the reflections, shadows and colors, based on what it has learned about real images. - -Bryan Catanzaro, NVIDIA此外,創作者還制作了一個自主互動演示:演示地址
以上,謝謝!
參考
- ^ SpeecpFace: Learning the Face Behind a Voice https://speecpface.github.io/
- ^https://arxiv.org/abs/1905.09773
- ^ Progressive Growing of GANs for Improved Quality, Stability, and Variation https://research.nvidia.com/publication/2017-10_Progressive-Growing-of
- ^ WaveNet: A Generative Model for Raw Audio | DeepMind https://deepmind.com/blog/wavenet-generative-model-raw-audio/











