簡要概述原理:
每個檔都由各種不同程式碼組成,比如01程式碼。這類檔只有數位0與1組合。
壓縮原理就是 【 透過尋找其中的規律,簡化數位的排列】 。
比如
00000110001111111111
可以簡化成
5個0,2個1,3個0,10個1的排列
100000000000
可以簡化成數學的
10^10
至於
@yskin
說 沒見過2G壓縮到十幾兆的。
實際上在極限壓縮方式下其實28.1G壓到25.8M都可以。
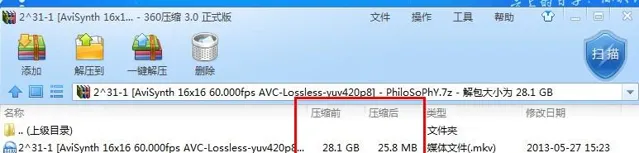
附下載
2^31-1 [AviSynth 16x16 60.000fps AVC-Lossless-yuv420p8]
開啟看後基本都能理解這個壓縮的大概原理了。
下面是幾種常見檔壓縮演算法原理介紹:
字典演算法
字典演算法是最為簡單的壓縮演算法之一。它是把文本中出現頻率比較多的單詞或詞匯組合做成一個對應的字典列表,並用特殊程式碼來表示這個單詞或詞匯。例如:
有字典列表:
00=Chinese
01=People
02=China
源文本:I am a Chinese people,I am from China 壓縮後的編碼為:I am a 00 01,I am from 02。壓縮編碼後的長度顯著縮小,這樣的編碼在SLG遊戲等專有名詞比較多的遊戲中比較容易出現,比如【SD高達】。
----------------------------------------------------------------------------------------------------------------------
固定位長演算法(Fixed Bit Length Packing)
這種演算法是把文本用需要的最少的位來進行壓縮編碼。
比 如八個十六進制數:1,2,3,4,5,6,7,8。轉換為二進制為:00000001,00000010,00000011,00000100, 00000101,00000110,00000111,00001000。每個數只用到了低4位元,而高4位元沒有用到(全為0),因此對低4位元進行壓縮編 碼後得到:0001,0010,0011,0100,0101,0110,0111,1000。然後補充為字節得到:00010010, 00110100,01010110,01111000。所以原來的八個十六進制數縮短了一半,得到4個十六進制數:12,34,56,78。
這也是比較常見的壓縮演算法之一。
------------------------------------------------------------------------------------------------------------
RLE(Run Length Encoding)
是一個針對無失真壓縮的非常簡單的演算法。它用重復字節和重復的次數來簡單描述來代替重復的字節。盡管簡單並且對於通常的壓縮非常低效,但它有的時候卻非常有用(例如,JPEG就使用它)。

原理圖2.1顯示了一個如何使用RLE演算法來對一個數據流編碼的例子,其中出現六次的符號‘93’已經用3個字節來代替:一個標記字節(‘0’在本例中)重復的次數(‘6’)和符號本身(‘93’)。RLE解碼器遇到符號‘0’的時候,它表明後面的兩個字節決定了需要輸出哪個符號以及輸出多少次。
這種壓縮編碼是一種變長的編碼,RLE根據文本不同的具體情況會有不同的壓縮編碼變體與之相適應,以產生更大的壓縮比率。
變體1:重復次數+字元
文本字串:A A A B B B C C C C D D D D,編碼後得到:3 A 3 B 4 C 4 D。
變體2:特殊字元+重復次數+字元
文本字串:A A A A A B C C C C B C C C,編碼後得到:B B 5 A B B 4 C B B 3 C。編碼串的最開始說明特殊字元B,以後B後面跟著的數位就表示出重復的次數。
變體3:把文本每個字節分組成塊,每個字元最多重復 127 次。每個塊以一個特殊字節開頭。那個特殊字節的第 7 位如果被置位,那麽剩下的7位數值就是後面的字元的重復次數。如果第 7 位沒有被置位,那麽剩下 7 位就是後面沒有被壓縮的字元的數量。例如:文本字串:A A A A A B C D E F F F。編碼後得到:85 A 4 B C D E 83 F(85H= 10000101B、4H= 00000100B、83H= 10000011B)
實作RLE可以使用很多不同的方法。基本壓縮庫中詳細實作的方式是非常有效的一個。一個特殊的標記字節用來指示重復節的開始,而不是對於重復非重復節都coding run。
因此非重復節可以有任意長度而不被控制字節打斷,除非指定的標記字節出現在非重復節(頂多以兩個字節來編碼)的稀有情況下。為了最佳化效率,標記字節應該是輸入流中最少出現的符號(或許就不存在)。
重復runs能夠在32768字節的時候運轉。少於129字節的要求3個字節編碼(標記+次數+符號),而大雨128字節要求四個字節(標記+次數的高4位元|0x80+次數的低4位元)。這是通常所有采用的壓縮的做法,並且也是相比較三個字節固定編碼(允許使用3個字節來編碼256個字節)而言非常少見的失真壓縮率的方法。
在這種模式下,最壞的壓縮結果是:
輸出大小=257/256*輸入大小+1
其他還有很多很多變體演算法,這些演算法在Winzip Winrar這些軟體中也是經常用到的。
----------------------------------------------------------------------------------------------------------------
霍夫曼編碼(Huffman Encoding)
哈夫曼編碼是無失真壓縮當中最好的方法。它使用預先二進制描述來替換每個符號,長度由特殊符號出現的頻率決定。常見的符號需要很少的位來表示,而不常見的符號需要很多為來表示。
哈夫曼演算法在改變任何符號二進制編碼引起少量密集表現方面是最佳的。然而,它並不處理符號的順序和重復或序號的序列。
原理我不打算探究哈夫曼編碼的所有實際的細節,但基本的原理是為每個符號找到新的二進制表示,從而通常符號使用很少的位,不常見的符號使用較多的位。
簡短的說,這個問題的解決方案是為了尋找每個符號的通用程度,我們建立一個未壓縮數據的柱狀圖;透過遞迴拆分這個柱狀圖為兩部份來建立一個二元樹,每個遞迴的一半應該和另一半具有同樣的權(權是∑NK =1符號數k, N是分之中符號的數量,符號數k是符號k出現的次數)
這棵樹有兩個目的:
1. 編碼器使用這棵樹來找到每個符號最優的表示方法
2. 解碼器使用這棵樹唯一的標識在壓縮流中每個編碼的開始和結束,其透過在讀壓縮數據位的時候自頂向底的遍歷樹,選擇基於數據流中的每個獨立位的分支,一旦一個到達葉子節點,解碼器知道一個完整的編碼已經讀出來了。

我們來看一個例子會讓我們更清楚。圖2.2顯示了一個10個字節的未壓縮的數據。
根據符號頻率,哈夫曼編碼器生成哈夫曼樹(圖2.4)和相應的編碼表示(圖2.3)。
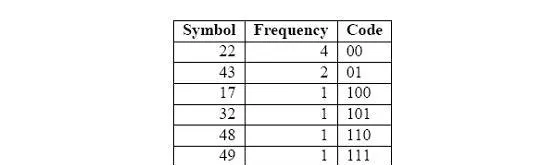
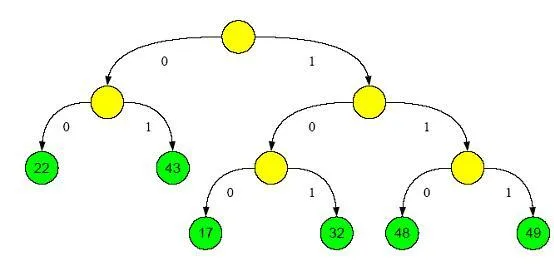
你可以看到,常見的符號接近根,因此只要少數位來表示。於是最終的壓縮數據流如圖2.5所示。

壓縮後的數據流是24位元(三個字節),原來是80位(10個字節)。當然,我應該儲存哈夫曼樹,這樣解碼器就能夠解碼出對應的壓縮流了,這就使得該例子中的真正數據流比輸入的流數據量大。這是相對較短的數據上的副作用。對於大數據量來說,上面的哈夫曼樹就不占太多比例了。解碼的時候,從上到下遍歷樹,為壓縮的流選擇從左/右分支,每次碰到一個葉子節點的時候,就可以將對應的字節寫到解壓輸出流中,然後再從根開始遍歷。 實作哈夫曼編碼器可以在基本壓縮庫中找到,其是非常直接的實作。
這個實作的基本缺陷是:
1. 慢位流實作
2. 相當慢的解碼(比編碼慢)
3. 最大的樹深度是32(編碼器在任何超過32位元大小的時候結束)。如果我不是搞錯的話,這是不可能的,除非輸出的數據大於232字節。
另一方面,這個實作有幾個優點:
1. 哈夫曼樹以一個緊密的形式每個符號要求12位元(對於8位元的符號)的方式儲存,這意味著最大的頭為384。
2. 編碼相當容易理解
哈夫曼編碼在數據有噪音的情況(不是有規律的,例如RLE)下非常好,這中情況下大多數基於字典方式的編碼器都有問題。
3. Rice對於由大word(例如:16或32位元)組成的數據和教低的數據值,Rice編碼能夠獲得較好的壓縮比。音訊和高動態變化的影像都是這種型別的數據,它們被某種預言預處理過(例如delta相鄰的采樣)。
盡管哈夫曼編碼處理這種數據是最優的,卻由於幾個原因而不適合處理這種數據(例如:32位元大小要求16GB的柱狀圖緩沖區來進行哈夫曼樹編碼)。因此一個比較動態的方式更適合由大word組成的數據。
原理Rice編碼背後的基本思想是盡可能的用較少的位來儲存多個字(正像使用哈夫曼編碼一樣)。實際上,有人可能想到Rice是靜態的哈夫曼編碼(例如,編碼不是由實際數據內容的統計資訊決定,而是由小的值比高的值常見的假定決定)。
編碼非常簡單:將值X用X個‘1’位之後跟一個0位來表示。
實作在基本壓縮庫針對Rice做了許多最佳化:
1. 每個字最沒有意義的位被儲存為k和最有意義的N-k位用Rice編碼。K作為先前流中少許采樣的位平均數。這是通常最好使用Rice編碼的方法,隱藏噪音且對於動態變化的範圍並不導致非常長的Rice編碼。
2. 如果rice編碼比固定的開端長,T,一個可選的編碼:輸出T個‘1’位,緊跟(log2(X-T))個‘1’和一個‘0’位,接著是X-T(最沒有意義的(log2(X-T))-1位)。這對於大值來說都是比較高效的程式碼並且阻止可笑的長Rice編碼(最壞的情況,對於一個32位元word單個Rice編碼可能變成232位元或512MB)。
如果開端是4,下面是結果編碼表:
X
bin
Rice
Thresholded
Rice
0
00000
0
0
1
00001
10
10
2
00010
110
110
3
00011
1110
1110
4
00100
11110
11110
5
00101
111110
111110
6
00110
1111110
11111100
+1
7
00111
11111110
11111101
8
01000
111111110
1111111000
+1
9
01001
1111111110
1111111001
10
01010
11111111110
1111111010
-1
11
01011
111111111110
1111111011
-2
12
01100
1111111111110
111111110000
13
01101
11111111111110
111111110001
-1
14
01110
111111111111110
111111110010
-2
15
01111
1111111111111110
111111110011
-3
16
10000
11111111111111110
111111110100
-4
17
10001
111111111111111110
111111110101
-5
18
10010
1111111111111111110
111111110110
-6
19
10011
11111111111111111110
111111110111
-7
20
10100
111111111111111111110
11111111100000
-5
就像你看到的一樣,在這個實作中使用threshold方法僅僅兩個編碼導致一個最壞的情況;剩下的編碼產生比標準Rice編碼還要短的編碼。
最壞的情況,輸出。
--------------------------------------------------------------------------------------------------------------
Lempel-Ziv (LZ77)
Lempel-Ziv壓縮模式有許多不同的變量。基本壓縮庫有清晰的LZ77演算法的實作(Lempel-Ziv,1977),執行的很好,原始碼也非常容易理解。
LZ編碼器能用來通用目標的壓縮,特別對於文本執行的很好。
它也在RLE和哈夫曼編碼器(RLE,LZ,哈夫曼)中使用來大多數情況下獲得更多的壓縮。這個壓縮演算法是有版權的。
原理在LZ壓縮演算法的背後是使用RLE演算法用先前出現的相同字節序列的參照來替代。
簡單的講,LZ演算法被認為是字串匹配的演算法。例如:在一段文本中某字串經常出現,並且可以透過前面文本中出現的字串指標來表示。當然這個想法的前提是指標應該比字串本身要短。
例如,在上一段短語「字串」經常出現,可以將除第一個字串之外的所有用第一個字串參照來表示從而節省一些空間。
一個字串參照透過下面的方式來表示:
1. 唯一的標記
2. 偏移數量
3. 字串長度
由編碼的模式決定參照是一個固定的或變動的長度。後面的情況經常是首選,因為它允許編碼器用參照的大小來交換字串的大小(例如,如果字串相當長,增加參照的長度可能是值得的)。
實作使用LZ77的一個問題是由於演算法需要字串匹配,對於每個輸入流的單個字節,每個流中此字節前面的哪個字節都必須被作為字串的開始從而盡可能的進行字串匹配,這意味著演算法非常慢。
另一個問題是為了最佳化壓縮而調整字串參照的表示形式並不容易。例如,必須決定是否所有的參照和非壓縮字節應該在壓縮流中的字節邊界發生。
基本壓縮庫使用一個清晰的實作來保證所有的符號和參照是字節對齊的,因此犧牲了壓縮比率,並且字串匹配程式並不是最佳化的(沒有緩存、歷史緩沖區或提高速度的小技巧),這意味著程式非常慢。
另一方面,解壓縮程式非常簡單。
一個提高LZ77速度的試驗已經進行了,這個試驗中使用陣列索引來加速字串匹配的過程。然而,它還是比通常的壓縮程式慢。
當然靜態數據和動態數據的壓縮策略是完全不同的。
一個壓縮檔是不是還可以用其他演算法再繼續壓縮?
可以,但沒要。壓縮檔有極限值存在。高壓一遍已經很接近這個值了,再壓縮的話基本也就只有一丁點壓縮率提升,甚至會增加體積。

隨便做的渣繪圖。不要在意細節→ →
————————————————————————————————————————
下面是題外話。
那麽一般要如何簡單實作高壓縮?
系統檔諸如GAL遊戲跟一些純程式碼的文件基本能直接用 7Z 進行 無失真壓縮 就可以了。當然,高壓縮率也意味著更費時間的壓縮跟解壓。壓縮率小的沒必要用 7z,直接打包反而更適合。
影音圖檔多數壓縮率只能透過再編碼失真壓縮。比如BMP影像轉jpg 吧圖片的一些一般人用不到的雜資訊去除,APE轉MP3之類。基本除了音原始檔外其他要對比不太明顯。(照片BMP透過7Z壓縮後解壓其實是有點變化的,這個不細說,一說就沒完沒了了。)
https:// share.dmhy.org/topics/v iew/293217_Sola_BDRIP_1920x1080_TV13_OVA_Meu3_CM_Info3_SP5_NCoped_x264_m4a_10bit.html
→→至於有的人說我上面附帶的極限壓縮例子太坑爹,於是再附帶一個我做的動畫壓制1080p BDMV 透過10bit x264再編碼壓縮成每話90M大小視訊。源BDBOX總大小119.16GB。
畫面的話我【個人主觀看法】覺得在 電腦 觀看跟源盤 沒什麽區別。(PS3跟一些高端硬體芯片的解碼器播放那是另一回事了)
畫面控追求的BDMV無失真畫質也是 相對無失真 。真正意義上的無失真畫質輸出的影片,渲染體積1分鐘視訊就超過10G。我個人渲過最大的是18秒44.5G 8k視訊。
參考資料
[1]
幾種壓縮演算法原理介紹










