主要的深度學習系列演算法有DBN, ConvNets, RNN等,基本上經典的深度學習演算法都用過。
詳細請看唐路路(研究方向 深度學習 3D重建)在專欄 機器學習&深度學習--學術水準的理解 總結的文章 深度學習在3D重建上的套用
近年來Deep Learning在電腦視覺上的套用主要在2D image 的detection,segmentation, classification等方面,感覺已經快無孔不入了。但是DL在3D scene上的研究相對還較少,比如3D reconstruction or 3D modeling。因此,今天我想淺談下image-based 3D reconstruction.
具體來講,image-based的3D重構演算法可以描述為當給定某個物體或場景的一組照片時, 在一些假設條件下,比如物體材料、觀測視角和光照環境等,透過估計一個最相似的3D shape來解釋這組照片。 一個完整的3D重構流程通常包含以下幾個步驟:
1)收集場景圖片(Collect images);
2)計算每張圖的相機參數(Camera parameters for each image);
3)透過圖組來重構場景的 3D shape(幾何模型)以及其對應的相機參數;
(Reconstruct the 3D geometry of the scene and corresponding camera parameters.)
4)有選擇的重構場景的材料等(Optionally texture the reconstructed scene.)。
(Image source:Multi-View Stereo: A Tutorial, by Yasutaka Furukawa from Washington
University)
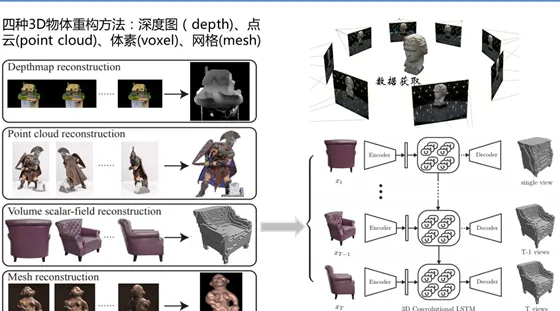
其中最核心的工作是第三步:3D shape的重構演算法。常規的3D shape representation有以下四種:深度圖(depth)、點雲(point cloud)、體素(voxel)、網格(mesh).
近年來,基於Deep learning 的3D reconstruction 也逐漸火熱起來, 例如David EigenNIPS2014上的文章 「 Depth Map Prediction from a Single Image using a Multi-Scale Deep Network 」,以及Fayao Liu 在CVPR2015上的文章「 Deep Convolutional Neural Fields for Depth Estimation from a Single Image 」。兩篇文章都是利用CNN網路結構學習預測 a single image與其對應的depth map 之間的關系。然而我個人覺得depth image 還不足以解釋重構原始input的資訊,它只能作為3D scene understanding的一個輔助資訊。 因此,一些學者開始研究利用一組二維圖來重構3D 點雲圖或voxel以及mesh圖,這裏就不詳細展開了。
個人覺得基於deep learning 的3D 點雲和mesh重構是較難以實施的,因為DL學習一個物體完整的架構需要大量數據支撐。然而傳統3D模型是由 vertices 和 triangulation mesh 組成的,因此不一樣的data size造成了training的困難。所以後續大家都用 voxelization(Voxel)的方法把所有CAD model轉成binary voxel 模式(有值為1,空缺為0)這樣保證了每個模型都是相同的大小。
早期的voxel-based 三維物體重建代表作有 3DShapeNet (http:// princeton.edu ) ,它采用Deep Belief Network (DBN)來學習 voxel 的 probabilistic embedding 然後在給帶有2.5D資訊的圖片後,透過 Gibbs Sampling來不斷預測他的 shape class 和填補他的未知voxel以完成3D模型重建。
後續又有CMU的paper 「Learning a Predictable and Generative Vector Representation for Objects」 ,利用auto-encoder 學習3D Model 的 embedding, 然後透過 ConvNets學習一個 deterministic function 讓其 rendered image infer 到學習到的 embedding 上。因為 auto -encoder是generative的,對於新的test image,模型就會infer 到相關的3D model embedding,再透過decoder生成其相應的 3D model。
同型別的工作還有Choy 在ECCV2016的一篇文章 「3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction」。 采用深度學習從2D影像到其對應的3D voxel模型的對映: 首先利用一個標準的CNN結構對原始input image 進行編碼; 再利用一個標準 Deconvolution network 對其解碼。 中間用Long Short-Term Memory(LSTM是RNN中的一種)進行過渡連線, LSTM 單元排列成3D網格結構, 每個單元接收一個feature vector from Encoder and Hidden states of neighbors by convolution,並將他們輸送到Decoder中. 這樣每個LSTM單元重構output voxel的一部份。 總之,透過這樣的Encoder-3DLSTM-Decoder 的網路結構就建立了2D images -to -3D voxel model 的對映.
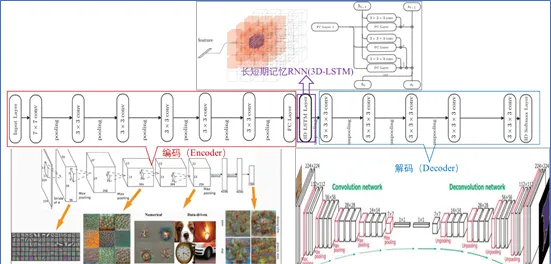
但是,由於3D voxel是三維的,它的resolution成指數增長,所以它的計算相對復雜,目前的工作主要采用32*32*3以下的分辨率以防止過多的占用記憶體。 但這使得最終重構的3D model分辨率並不高, 也可能catch不到一些常規的結構(比如對稱性、直線、曲線等),離真實物體還有較大差距。在DL如此火熱的今天,如何將其更好的套用到3D reconstruction(3D重構) 或3D modeling(3D建模)上確實值得我們進一步深入研究。例如考慮如何提高voxel model 的分辨率; 如何選擇best view 和最少的 view來重構3D物體;如何利用mesh 或point cloud來直接重構3D物體等。但由於mesh 和point cloud是不規則的幾何數據形式,因此直接使用CNN是不可行的。但是可以考慮將3D mesh data 轉化為graphs形式,再對3D曲面上的2D參數進行摺積。具體方法有Spatial construction (Geodesic CNN)和Spectral construction (Spectral CNN)。基於point cloud的方法,可以參考大神Hao Su的CVPR2017文章「PointNet: Deep Learning on Point Sets for 3D classification and Segmentation」和「A Point Set Generation Network for 3D Object Reconstruction from a Single Image」。 但是基於mesh和point cloud的方法總的來講數學東西多,而且細節恢復上效果欠佳。不過可以考慮結合voxel來提高重構精度。這裏就不啰嗦了,有興趣的留言交流。若有理解錯誤的也歡迎指正,謝謝!











