據了解,在大模型領域有研究人員認為智慧與資料壓縮緊密相關甚至是等價的。這種觀點在大模型的快速開發中變得更加引人註目。
基於此,一些研究者提出大模型的壓縮理論,將語言建模(Language Modeling)和壓縮建立等價關系,從全新角度闡述了大模型訓練的本質以及模型智慧的來源。
但是,對於關於壓縮能力和智慧之間關系的實驗證據卻很十分有限。
為此,香港科技大學團隊希望填補這一空白,透過實驗研究來探討大模型之中壓縮和智慧的關系。
其希望借此回答這樣一個問題:如果一個大模型相比另一個大模型,能夠以無失真的方式使用更少的位元編碼一個文本語料庫,這是否表示它具有更高的智慧?
在本項工作中,該課題組遵循「智慧與資料壓縮緊密相關甚至是等價的」的定義,從大模型在下遊任務中的能力來衡量它的智慧水平。
並聚焦於三個具有代表性的能力:知識能力、編程能力和數學推理能力。
為了實作上述的目標,他們在多達 30 個大模型和 12 項基準(benchmark)上進行實驗,針對不同的大模型進行橫向比較。
這些大模型有著不同的架構設計、不同的分詞器、以及在不同的數據上訓練。
結果如下圖所示:
總體來看,大模型的下遊能力(Y 軸)和其壓縮能力(X 軸)高度線性相依,二者的皮爾森相關系數為-0.94。
並且,這種線性關系可以很好地延伸到各個子領域(圖片右側),甚至延伸到大多數的基準測試。
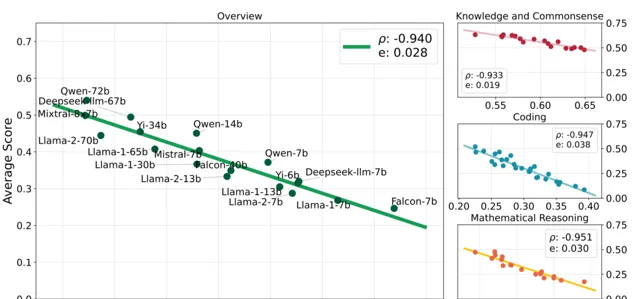
在實驗設計上,他們收集和清洗各自領域的最新語料數據,並在收集的語料上測試大模型的壓縮效能。
具體來說,針對知識能力、編程能力和數學推理能力,該團隊分別從 Common Crawl、GitHub 和 arXiv 收集語料,並采用 標準的清洗流程針對數據進行清洗。
與此同時,他們使用 bits per character 作為模型壓縮能力的衡量指標,並引入了「上下文視窗統一」和「滑動視窗」等方法使得評估結果更準確、以及更具有可比性。
最後,該團隊在一系列下遊任務上評估這些大模型,使用平均基準分數來衡量其特定領域的智慧,並評估智慧和壓縮兩者的線性相依關系。
總的來說,課題組揭示了這樣一個規律:即大模型的智慧(下遊任務能力),幾乎與它們壓縮外部語料的能力呈線性相依。
憑借此,本次研究為大模型的智慧水平評估提供了全新的角度,為使用壓縮能力作為模型評測指標提供了依據。
據介紹,使用壓縮能力作為評估指標具有無監督、靈活和可靠的特點。
同時,由於不需要數據標註,測試所需的數據可以很方便地進行叠代,從而可以減輕大多數評估方法所面臨的數據汙染和過度擬合問題。
由此可見,本次成果在大模型的評估和最佳化方面具有很大的潛在價值。
日前,相關論文以【壓縮線性代表智慧】 (Compression Represents Intelligence Linearly)為題發在 arXiv 。

圖 | 相關論文(來源:arXiv)
香港科技大學博士生黃裕振、張靜涵是(共同)第一作者,指導老師為何俊賢。

圖 | 黃裕振(來源:黃裕振)
另據悉,他們已經在 GitHub 開源了所使用的語料數據集和數據收集程式碼等(https://github.com/hkust-nlp/llm-compression-intelligence)。
本次課題之中,盡管該團隊盡可能全面地開展研究,但其依然存在一些局限性,但也為實作新的突破帶來了一定機會。
機會之一在於:大模型通常可以分為兩種基礎模型(Base model)和微調模型(Finetune model)。本項研究只關註了基礎模型,而微調模型的測試和評估依然有待探索。
機會之二在於:本次研究中的實驗主要針對短文本和中長文本,對於長文本的場景依然有待探索。
機會之三在於:本次結論可能並不適用於未得到充分訓練的模型,因此可以探討在這些模型中壓縮效率與智慧之間的關系。
參考資料:
1.https://arxiv.org/pdf/2404.09937
營運/排版:何晨龍
01/ 科學家研發數位非福斯特電路,功率處理能力提高3個數量級,能用於遠距離聲通訊或無線通訊
02/ 清華團隊遠赴雲南養蚊子,借此發現新型抗病毒細菌,為蚊媒傳染病防控提供有力方案
03/ 馬普所團隊補齊固-液界面的基礎理論缺失,突破奈米塗層的傳統認知,推動無氟奈米塗層的套用
04/ 科學家闡釋純量子AI演算法理論,對同類演算法具有普遍指導意義,或極大提升生化及圖文領域模型效能
05/ 讓心衰治療告別「治標不治本」:科學家發現新型小分子激動劑,能有效緩解心肌肥大和纖維化












