很简单,别人不会的你会。
比如,Bitonic Sort(双调排序,时间复杂度 O(n(logn)^2) )是一种并行排序算法,特别适合在GPU上实现。我自己用OpenCL实现了一个并进行了调优,算法是我用纸笔推导的,分为5个kernel。在GPU上编程不同于CPU,没有调试器可用,也没有printf,数组越界电脑直接黑屏。
我就直接用C++实现了一个在CPU上运行的OpenCL kernel,实现了__local限定符 get_global_id get_local_id barrier等函数,用它实现的我的排序算法。这样就可以很方便的进行调试了,验证完成后移植在GPU上。
本人看过多个Bitonic Sort的实现, 在github搜索的基本上就是一堆玩具,没有我实现的好,Microsoft DirectX SDK中的也是玩具。DirectX-Graphics-Samples的 使用了Indirect模式,但是其numthreads是写死了的。 CUDA SDK Samples的 4个Kernel ,还算可以。
相比于其他的实现,我的这个使用#define设置不同的local size,在不同的硬件上实现更好的性能。
这就是Bitonic Sort的kernel代码(完全是自己实现的):
#if VEC_STEP == 4
#define VEC_SEQ (uint4)(0,1,2,3)
#define SCALAR_TYPE int
#define VEC_TYPE int4
#define VEC_TYPE_AS as_int4
#define LOGICAL_TYPE uint4
#define LOGICAL_TYPE_AS as_uint4
#define INDEX_TYPE uint4
#define INDEX_TYPE_AS as_uint4
#define VLOADN vload4
#define VSTOREN vstore4
#define INPUT_TO_PRIVATE(A,B,IA,IB,INPUT) \
A.s0=INPUT[IA.s0];\
A.s1=INPUT[IA.s1];\
A.s2=INPUT[IA.s2];\
A.s3=INPUT[IA.s3];\
B.s0=INPUT[IB.s0];\
B.s1=INPUT[IB.s1];\
B.s2=INPUT[IB.s2];\
B.s3=INPUT[IB.s3];
#define PRIVATE_TO_INPUT(A,B,IA,IB,INPUT) \
INPUT[IA.s0] = A.s0;\
INPUT[IA.s1] = A.s1;\
INPUT[IA.s2] = A.s2;\
INPUT[IA.s3] = A.s3;\
INPUT[IB.s0] = B.s0;\
INPUT[IB.s1] = B.s1;\
INPUT[IB.s2] = B.s2;\
INPUT[IB.s3] = B.s3;
#else
#error Need VEC_SEQ
#endif
#ifndef LOCAL_VEC_SIZE
#error Need LOCAL_VEC_SIZE
#endif
#ifndef WG_SIZE
#error Need WG_SIZE
#endif
//#define LOCAL_VEC_SIZE 4096
//设 global_size 为 2^m local_size为 2^n 那么
void
BitnoicSortLocalStage1_1
(
__local
SCALAR_TYPE
*
input
,
const
unsigned
int
num_local
)
{
size_t
gid
=
get_group_id
(
0
);
size_t
num_groups
=
get_num_groups
(
0
);
size_t
lid
=
get_local_id
(
0
);
size_t
lsize
=
get_local_size
(
0
);
#pragma unroll
for
(
unsigned
int
step1
=
1
;
step1
<
LOCAL_VEC_SIZE
;
step1
<<=
1
)
{
unsigned
int
sh
=
0
;
for
(
unsigned
int
step2
=
step1
;
step2
>=
1
;
step2
>>=
1
)
{
for
(
unsigned
int
loop
=
lid
;
loop
<
LOCAL_VEC_SIZE
/
2
;
loop
+=
lsize
*
VEC_STEP
)
{
INDEX_TYPE
iloop
=
VEC_SEQ
*
(
uint
)
lsize
+
loop
;
INDEX_TYPE
gloop
=
iloop
+
(
LOCAL_VEC_SIZE
/
2
)
*
num_local
;
INDEX_TYPE
t1
=
gloop
&
step1
;
INDEX_TYPE
t2
=
t1
^
step1
;
INDEX_TYPE
u1
=
(
iloop
&
(
~
(
step2
-
1
)))
<<
1
;
INDEX_TYPE
u2
=
(
step2
-
1
)
&
iloop
;
INDEX_TYPE
a
=
u1
+
u2
+
(
t1
>>
sh
);
INDEX_TYPE
b
=
u1
+
u2
+
(
t2
>>
sh
);
VEC_TYPE
ia
;
// = input[a];
VEC_TYPE
ib
;
// = input[b];
INPUT_TO_PRIVATE
(
ia
,
ib
,
a
,
b
,
input
);
LOGICAL_TYPE
icomp
=
LOGICAL_TYPE_AS
(
ia
<
ib
);
LOGICAL_TYPE
ncomp
=
LOGICAL_TYPE_AS
(
!
icomp
);
VEC_TYPE
oa
=
select
(
ia
,
ib
,
icomp
);
VEC_TYPE
ob
=
select
(
ia
,
ib
,
ncomp
);
PRIVATE_TO_INPUT
(
oa
,
ob
,
a
,
b
,
input
);
}
barrier
(
CLK_LOCAL_MEM_FENCE
);
sh
++
;
}
}
}
void
BitnoicSortLocalStage1_2
(
__local
SCALAR_TYPE
*
input
,
const
unsigned
int
step1_begin
,
const
unsigned
int
shift
,
const
unsigned
int
num_local
)
{
size_t
gid
=
get_group_id
(
0
);
size_t
num_groups
=
get_num_groups
(
0
);
size_t
lid
=
get_local_id
(
0
);
size_t
lsize
=
get_local_size
(
0
);
unsigned
int
sh
=
shift
;
unsigned
int
step1
=
step1_begin
;
#pragma unroll
for
(
unsigned
int
step2
=
(
LOCAL_VEC_SIZE
/
2
);
step2
>=
1
;
step2
>>=
1
)
{
for
(
unsigned
int
loop
=
lid
;
loop
<
LOCAL_VEC_SIZE
/
2
;
loop
+=
lsize
*
VEC_STEP
)
{
INDEX_TYPE
iloop
=
VEC_SEQ
*
(
uint
)
lsize
+
loop
;
INDEX_TYPE
gloop
=
iloop
+
(
LOCAL_VEC_SIZE
/
2
)
*
num_local
;
INDEX_TYPE
t1
=
step1
&
gloop
;
INDEX_TYPE
t2
=
t1
^
step1
;
INDEX_TYPE
u1
=
(
iloop
&
(
~
(
step2
-
1
)))
<<
1
;
INDEX_TYPE
u2
=
(
int
)(
step2
-
1
)
&
iloop
;
INDEX_TYPE
a
=
u1
+
u2
+
(
t1
>>
sh
);
INDEX_TYPE
b
=
u1
+
u2
+
(
t2
>>
sh
);
VEC_TYPE
ia
;
// = input[a];
VEC_TYPE
ib
;
// = input[b];
INPUT_TO_PRIVATE
(
ia
,
ib
,
a
,
b
,
input
);
LOGICAL_TYPE
icomp
=
LOGICAL_TYPE_AS
(
ia
<
ib
);
LOGICAL_TYPE
ncomp
=
LOGICAL_TYPE_AS
(
!
icomp
);
VEC_TYPE
oa
=
select
(
ia
,
ib
,
icomp
);
VEC_TYPE
ob
=
select
(
ia
,
ib
,
ncomp
);
PRIVATE_TO_INPUT
(
oa
,
ob
,
a
,
b
,
input
);
}
barrier
(
CLK_LOCAL_MEM_FENCE
);
sh
++
;
}
}
//运行1次
__kernel
__attribute__
((
reqd_work_group_size
(
WG_SIZE
,
1
,
1
)))
void
BitonicSortLocalStage1_1Kernel
(
__global
SCALAR_TYPE
*
input
,
const
unsigned
int
step1
,
const
unsigned
int
step2
,
const
unsigned
int
len
)
{
size_t
gid
=
get_group_id
(
0
);
size_t
num_groups
=
get_num_groups
(
0
);
size_t
lid
=
get_local_id
(
0
);
size_t
lsize
=
get_local_size
(
0
);
unsigned
int
loop_count
=
len
/
LOCAL_VEC_SIZE
;
__local
SCALAR_TYPE
value
[
LOCAL_VEC_SIZE
];
for
(
unsigned
int
ng
=
gid
;
ng
<
loop_count
;
ng
+=
num_groups
)
{
async_work_group_copy
(
value
,
input
+
(
ng
*
LOCAL_VEC_SIZE
)
,
LOCAL_VEC_SIZE
,(
event_t
)
0
);
barrier
(
CLK_LOCAL_MEM_FENCE
);
//wait_group_events(1,&e1);
BitnoicSortLocalStage1_1
(
value
,
ng
);
async_work_group_copy
(
input
+
(
ng
*
LOCAL_VEC_SIZE
),
value
,
LOCAL_VEC_SIZE
,(
event_t
)
0
);
barrier
(
CLK_LOCAL_MEM_FENCE
);
//wait_group_events(1,&e2);
}
}
//运行m-n次
__kernel
__attribute__
((
reqd_work_group_size
(
WG_SIZE
,
1
,
1
)))
void
BitonicSortLocalStage1_2Kernel
(
__global
SCALAR_TYPE
*
input
,
const
unsigned
int
step1
,
const
unsigned
int
step2
,
const
unsigned
int
len
,
const
unsigned
int
sh
)
{
size_t
gid
=
get_group_id
(
0
);
size_t
num_groups
=
get_num_groups
(
0
);
size_t
lid
=
get_local_id
(
0
);
size_t
lsize
=
get_local_size
(
0
);
unsigned
int
loop_count
=
len
/
LOCAL_VEC_SIZE
;
__local
SCALAR_TYPE
value
[
LOCAL_VEC_SIZE
];
for
(
unsigned
int
ng
=
gid
;
ng
<
loop_count
;
ng
+=
num_groups
)
{
async_work_group_copy
(
value
,
input
+
(
ng
*
LOCAL_VEC_SIZE
)
,
LOCAL_VEC_SIZE
,(
event_t
)
0
);
barrier
(
CLK_LOCAL_MEM_FENCE
);
BitnoicSortLocalStage1_2
(
value
,
step1
,
sh
,
ng
);
async_work_group_copy
(
input
+
(
ng
*
LOCAL_VEC_SIZE
),
value
,
LOCAL_VEC_SIZE
,(
event_t
)
0
);
barrier
(
CLK_LOCAL_MEM_FENCE
);
}
}
void
BitonicSortLocalStage2
(
__local
SCALAR_TYPE
*
input
)
{
size_t
gid
=
get_group_id
(
0
);
size_t
num_groups
=
get_num_groups
(
0
);
size_t
lid
=
get_local_id
(
0
);
size_t
lsize
=
get_local_size
(
0
);
size_t
gsize
=
get_global_size
(
0
);
#pragma unroll
for
(
unsigned
int
step1
=
LOCAL_VEC_SIZE
/
2
;
step1
>=
1
;
step1
>>=
1
)
{
for
(
int
loop
=
lid
;
loop
<
LOCAL_VEC_SIZE
/
2
;
loop
+=
lsize
*
VEC_STEP
)
{
INDEX_TYPE
iloop
=
VEC_SEQ
*
(
uint
)
lsize
+
loop
;
INDEX_TYPE
u1
=
(
~
(
step1
-
1
)
&
iloop
)
<<
1
;
INDEX_TYPE
u2
=
((
step1
-
1
)
&
iloop
);
INDEX_TYPE
a
=
u1
+
u2
;
INDEX_TYPE
b
=
a
+
step1
;
VEC_TYPE
ia
;
// = input[a];
VEC_TYPE
ib
;
// = input[b];
INPUT_TO_PRIVATE
(
ia
,
ib
,
a
,
b
,
input
);
LOGICAL_TYPE
icomp
=
LOGICAL_TYPE_AS
(
ia
<
ib
);
LOGICAL_TYPE
ncomp
=
LOGICAL_TYPE_AS
(
!
icomp
);
VEC_TYPE
icomp_
=
VEC_TYPE_AS
(
icomp
&
1
);
VEC_TYPE
ncomp_
=
VEC_TYPE_AS
(
ncomp
&
1
);
VEC_TYPE
oa
=
ia
*
icomp_
+
ib
*
ncomp_
;
VEC_TYPE
ob
=
ia
*
ncomp_
+
ib
*
icomp_
;
PRIVATE_TO_INPUT
(
oa
,
ob
,
a
,
b
,
input
);
}
barrier
(
CLK_LOCAL_MEM_FENCE
);
}
}
//运行1次
__kernel
__attribute__
((
reqd_work_group_size
(
WG_SIZE
,
1
,
1
)))
void
BitonicSortLocalStage2Kernel
(
__global
SCALAR_TYPE
*
input
,
const
unsigned
int
step1
,
const
unsigned
int
step2
,
const
unsigned
int
len
)
{
size_t
gid
=
get_group_id
(
0
);
size_t
num_groups
=
get_num_groups
(
0
);
size_t
lid
=
get_local_id
(
0
);
size_t
lsize
=
get_local_size
(
0
);
unsigned
int
loop_count
=
len
/
LOCAL_VEC_SIZE
;
__local
SCALAR_TYPE
value
[
LOCAL_VEC_SIZE
];
for
(
unsigned
int
ng
=
gid
;
ng
<
loop_count
;
ng
+=
num_groups
)
{
async_work_group_copy
(
value
,
input
+
(
ng
*
LOCAL_VEC_SIZE
)
,
LOCAL_VEC_SIZE
,(
event_t
)
0
);
barrier
(
CLK_LOCAL_MEM_FENCE
);
BitonicSortLocalStage2
(
value
);
async_work_group_copy
(
input
+
(
ng
*
LOCAL_VEC_SIZE
),
value
,
LOCAL_VEC_SIZE
,(
event_t
)
0
);
barrier
(
CLK_LOCAL_MEM_FENCE
);
}
}
//运行(m-n) + (m-n)(m-n-1)/2 次
__kernel
__attribute__
((
reqd_work_group_size
(
WG_SIZE
,
1
,
1
)))
void
BitonicSortGlobalStage1Kernel
(
__global
SCALAR_TYPE
*
input
,
const
unsigned
int
step1
,
const
unsigned
int
step2
,
const
unsigned
int
len
,
const
unsigned
int
sh
)
{
size_t
gid
=
get_global_id
(
0
);
size_t
num_groups
=
get_num_groups
(
0
);
size_t
lid
=
get_local_id
(
0
);
size_t
lsize
=
get_local_size
(
0
);
size_t
gsize
=
get_global_size
(
0
);
for
(
unsigned
int
loop
=
gid
*
VEC_STEP
;
loop
<
len
/
2
;
loop
+=
gsize
*
VEC_STEP
)
{
unsigned
int
t1
=
step1
&
loop
;
unsigned
int
t2
=
t1
^
step1
;
unsigned
int
u1
=
((
~
(
step2
-
1
))
&
loop
)
<<
1
;
unsigned
int
u2
=
(
step2
-
1
)
&
loop
;
unsigned
int
a
=
u1
+
u2
+
(
t1
>>
sh
);
unsigned
int
b
=
u1
+
u2
+
(
t2
>>
sh
);
VEC_TYPE
ia
;
VEC_TYPE
ib
;
ia
=
VLOADN
(
a
/
VEC_STEP
,
input
);
//input[a];
ib
=
VLOADN
(
b
/
VEC_STEP
,
input
);
//input[b];
LOGICAL_TYPE
icomp
=
LOGICAL_TYPE_AS
(
ia
<
ib
);
LOGICAL_TYPE
ncomp
=
LOGICAL_TYPE_AS
(
!
icomp
);
VEC_TYPE
oa
=
select
(
ia
,
ib
,
icomp
);
VEC_TYPE
ob
=
select
(
ia
,
ib
,
ncomp
);
VSTOREN
(
oa
,
a
/
VEC_STEP
,
input
);
//input[a];
VSTOREN
(
ob
,
b
/
VEC_STEP
,
input
);
//input[b];
}
}
//运行m-n次
__kernel
__attribute__
((
reqd_work_group_size
(
WG_SIZE
,
1
,
1
)))
void
BitonicSortGlobalStage2Kernel
(
__global
SCALAR_TYPE
*
input
,
const
unsigned
int
step1
,
const
unsigned
int
step2
,
const
unsigned
int
len
)
{
size_t
gid
=
get_global_id
(
0
);
size_t
num_groups
=
get_num_groups
(
0
);
size_t
lid
=
get_local_id
(
0
);
size_t
lsize
=
get_local_size
(
0
);
size_t
gsize
=
get_global_size
(
0
);
for
(
unsigned
int
loop
=
gid
*
VEC_STEP
;
loop
<
len
/
2
;
loop
+=
gsize
*
VEC_STEP
)
{
unsigned
int
u1
=
(
~
(
step1
-
1
)
&
loop
)
<<
1
;
unsigned
int
u2
=
((
step1
-
1
)
&
loop
);
unsigned
int
a
=
u1
+
u2
;
unsigned
int
b
=
a
+
step1
;
VEC_TYPE
ia
;
VEC_TYPE
ib
;
ia
=
VLOADN
(
a
/
VEC_STEP
,
input
);
//input[a];
ib
=
VLOADN
(
b
/
VEC_STEP
,
input
);
//input[b];
LOGICAL_TYPE
icomp
=
LOGICAL_TYPE_AS
(
ia
<
ib
);
LOGICAL_TYPE
ncomp
=
LOGICAL_TYPE_AS
(
!
icomp
);
VEC_TYPE
icomp_
=
VEC_TYPE_AS
(
icomp
&
1
);
VEC_TYPE
ncomp_
=
VEC_TYPE_AS
(
ncomp
&
1
);
VEC_TYPE
oa
=
ia
*
icomp_
+
ib
*
ncomp_
;
VEC_TYPE
ob
=
ia
*
ncomp_
+
ib
*
icomp_
;
VSTOREN
(
oa
,
a
/
VEC_STEP
,
input
);
//input[a];
VSTOREN
(
ob
,
b
/
VEC_STEP
,
input
);
//input[b];
}
}
后来找到工作后,将其改成DirectX Compute Shader实现的。完全独自一人完成,公司除本人外没有一个人会。这个是为了做粒子效果用的,而粒子效果需要进行排序。
以后打算使用HLSL Shader Model 6 的新指令(vote, ballot, shuffle)进行性能优化,性能可以更快。
在GPU上还有一种排序 Radix Sort(基数排序),Bullet物理引擎用的就是Radix Sort。与Bitonic Sort相比 速度会快一些,但是会占额外的内存空间(Bitonic Sort不需要,可以就地进行排序,Radix Sort需要2个Buffer,一个读一个写),浮点数比较需要处理(Bullet引擎的FlipFloat)。本人也用OpenCL实现了一个并进行了测试,包含7个Kernel。其中有ExclusiveScan,Histogram等并行计算常用算法。
=============
2019年1月20日更新:
二叉树,估计大家都知道是什么。
但在GPU上建造二叉树各位听说过吗?
Bullet物理引擎就用到了,用于射线相交检测的BVH,需要将AABB包围盒转换成Morton Code后排序,然后根据排序后的Morton Code建造二叉树。
具体原理请看
和论文 Maximizing Parallelism in the Construction of BVHs, Octrees,and k-d Trees (该链接里就有)
借用论文中的一张图:
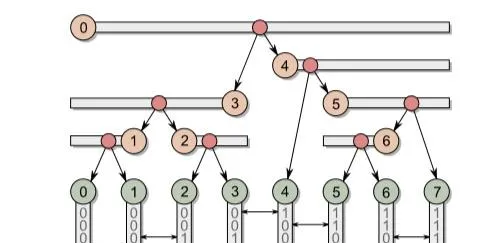
如图
红色代表中间节点 绿色代表叶子节点。一共有8个叶子节点,7个中间节点。
水平的箭头代表二进制公共前缀的高度,如3-4之间就为0,0-1之间为3
让0为最高的节点,开始查找最高的公共前缀高度,找到3-4之间最高,于是0节点指向3,4节点
3节点 2-3公共前缀高度为4,3-4公共前缀高度为0,2-3比3-4低所以向左查找。查找比3-4高度低的最高的节点。
找到1-2之间公共前缀高度为2,最高。3节点指向1,2节点。
4节点 3-4公共前缀高度为0,4-5公共前缀高度为1,3-4比4-5高所以向右查找。查找比3-4高度低的最高的节点。
找到4-5之间公共前缀高度为1,最高。4节点指向4,5节点。由于4节点指向自身,因此指向叶子节点。
叶子节点间,中间节点间完全无依赖,可以完全并行的建造。
Bullet物理引擎使用的方法与上述有些不同。
Bullet物理引擎的做法是:
每个叶子节点,如果左边的公共前缀高度比右边大,那么就指向左边的中间节点,如果右边大就指向右边的。最左的节点 公共前缀高度最小,最右的节点公共前缀高度最大。
每个中间节点,分别从左右方向查找离该节点最近的公共前缀高度比该节点高的节点,如果找不到, 公共前缀高度为最小。
如果找到的左边的公共前缀高度比右边大,那么就指向左边的中间节点,如果右边大就指向右边的。
当时为了搞懂算法原理,我把运行时产生的数据输出成文本,才找出了其中的规律。
这就是Bullet物理引擎,一个自带的Demo,看看左下角有多少个立方体。
这个Demo中的拾取算法(射线-三角形相交)就用到了BVH,每一帧的拾取都会建造BVH。碰撞检测也可以用BVH,但这个Demo用的是SAP。
写本文时入职才2个月,第一份工作。
可以看看我的另一个回答:
//=====================
2019年1月27日更新:
看到评论中有些人用过CUDA,我就说一说CUDA 和DirectX12 做计算的区别,难度不是一个等级的:
CUDA分配Buffer 直接用 cudaMalloc 。DirectX12用CreateCommittedResource,再根据资源的使用方式创建view。
CUDA上传用cudaMemcpy,而DirectX12 有2种方法:第一种直接创建一个 upload buffer ,然后memcpy。第二种创建一个 default buffer,再创建一个upload buffer,先memcpy到upload buffer,再根据资源类型 CopyBufferRegion CopyTextureRegion 到default buffer。
Root Signature :shader的资源绑定布局,相当于函数参数的定义,这个CUDA没有。
Descriptor Heap: CUDA没有,存放 view的地方。相当于预先定义的一个数组,存放Buffer 的指针。
Resource Barrier:资源状态转换,CUDA没有。上传资源时upload buffer状态转换为 COPY_SOURCE ,default buffer状态转换为COPY_DEST。当参数使用时default buffer状态转换为SHADER_RESOURCE。
Command Queue Command List Command Allocator :所有的渲染命令如 Draw Dispatch Copy Clear 都要记录到 Command List中,而 Command List需要指定Command Allocator 。完成后Close,Command Queue 再ExecuteCommandList执行记录的命令。
Fence Signal :ExecuteCommandList 是非阻塞的,执行后立即返回。需要等待的话创建一个Fence, 然后Command Queue再Signal创建的Fence,Fence再Wait。










