这又是一个高频的场景面试题,同时,它也是一个没有标准答案的、可以跟面试官讨论很久的面试题。
对于这个面试题,我的观点是:「 没有完美的方案,只有最适合某场景的方案。」
这个问题表面上看是数据一致性的问题,其实根本上,又是数据一致性、系统性能和系统复杂度的选择与取舍。
下面我们先历数一下各种技术方案,环肥燕瘦两相宜,总有一款适合你。
首先,分享一套我自己逐字写的、深入浅出、细致易懂的高频面试题详解,旨在以 一站式刷题 + 解惑 的方式帮你提升学习效率,需要的请自取。
强烈建议近期有求职诉求的Javaer好好看看。
1、先更新MySQL,再更新Redis
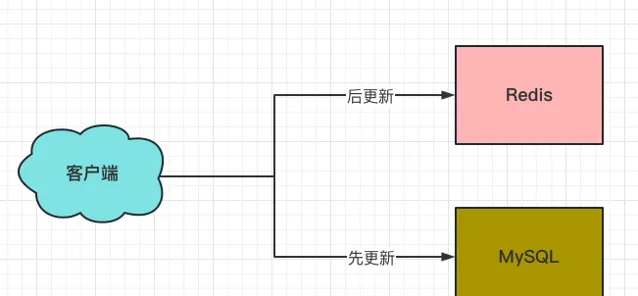
这个方案存在如下问题:
(1)如果先更新MySQL成功了,还未对Redis进行更新的间隙期,这时如果请求过来,读到的都是Redis的更新前数据。
(2)如果先更新MySQL成功了,再更新Redis失败了的话,后面的请求读到的都是Redis的更新前数据,并且后续的补救方案很难做。
补救方案一:为Redis更新失败,将MySQL中的对应数据也回滚了,以此达到两者数据的一致性。但MySQL是主数据源,它代表的是数据的「权威性」,这样做显然并不合理。
补救方案二:通过Redis重试更新的方式进行补救。但如果重试也失败了,还要继续重试吗?是设置固定的重试次数,还是一直重试到成功为止?
另外,重试时间间隔设置多少?时间间隔设置长了,影响业务的时间也会变长;时间间隔设置短了,重试成功率又会降低。这些其实都是问题。
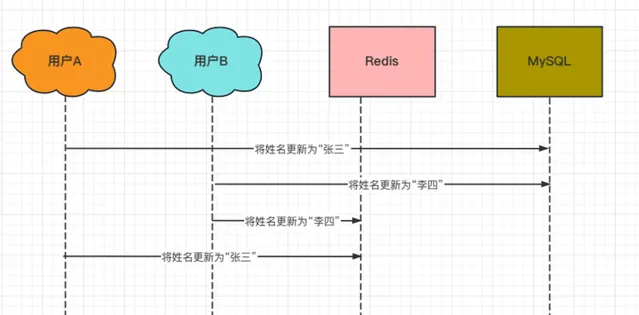
(3)两个线程同时更新的并发问题,如下:
2、先更新Redis,再更新MySQL
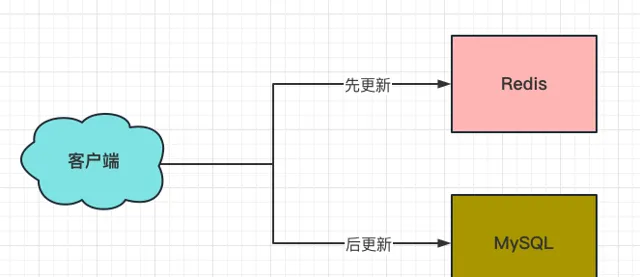
这个方案,要比方案一的「先更新MySQL,再更新Redis」合理一些。原因在于更新完Redis的话,哪怕还没更新MySQL,这时如果请求过来,读到的都是Redis更新后的新数据。
另外,先更新Redis成功,再更新MySQL失败,可以通过再删除Redis所对应的数据进行补救。
但其依然存在如下问题:
(1)如果先更新Redis成功了,再更新MySQL失败了的话,还未对Redis所对应的数据进行删除补救的间隙期,这时如果请求过来,读到的都是Redis未生效的新数据。
(2)如果先更新Redis成功了,再更新MySQL失败了的话,然后再删除Redis对应的数据也失败的时候,应该如何处理?如果通过重试机制继续进行删除Redis的话,又会面临之前说的重试次数和间隔期的问题。
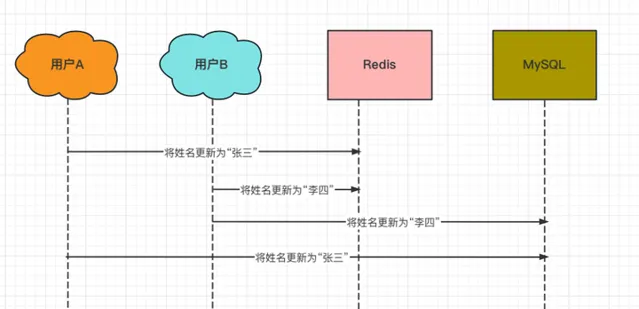
(3)两个线程同时更新的并发问题,如下:
3、先更新MySQL,再删除Redis
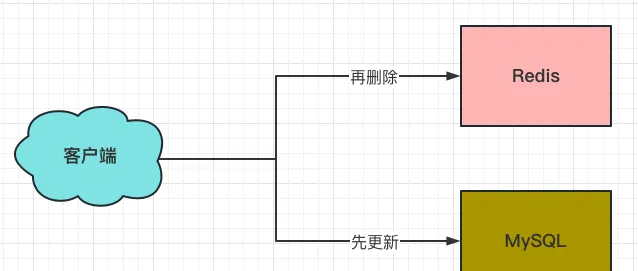
这个方案可以解决「并发更新」的问题,但依然会存在下面的两个问题:
(1)如果先更新MySQL成功了,还未对Redis进行删除的间隙期,这时如果请求过来,读到的都是Redis的删除前数据。
(2)如果先更新MySQL成功了,再删除Redis失败了的话,后面的请求读到的都是Redis的删除前数据,并且后续的补救方案很难做。
4、先删除Redis,再更新MySQL
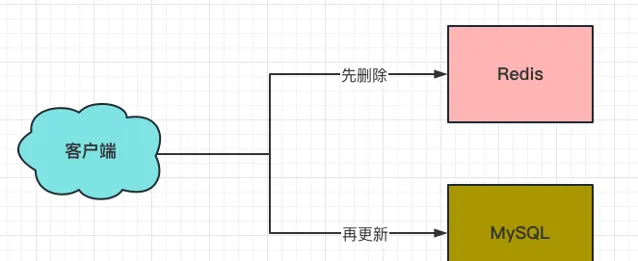
这个方案能解决方案3中遗留的两个棘手的问题:
(1)如果先删除Redis成功了,还未对MySQL进行更新的间隙期,此时对于该条数据而言,只存在于MySQL一个存储载体中,也就没有了数据一致性的问题。
(2)如果先删除Redis成功了,再更新MySQL失败了的话,此时对于该条数据而言,只存在于MySQL一个存储载体中,所谓的补救方案也就不需要了,直接当这条数据没更新成功。
OK,整体看起来似乎「天下无贼」了,但真的如此吗?其实不然,如果配合上Redis的「读策略」,还是会有数据一致性的问题。
4.1 先删除Redis,再更新MySQL + Redis读策略
Redis的读策略:
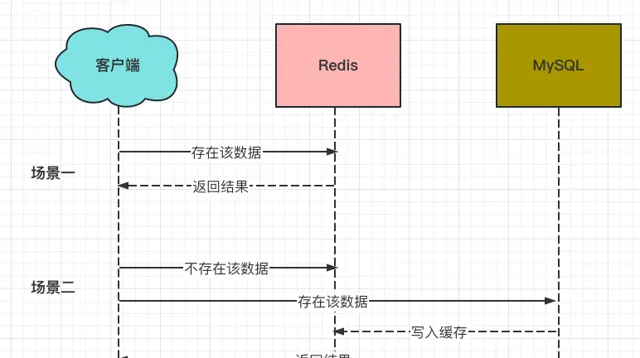
这样一来,就会存在如下问题:
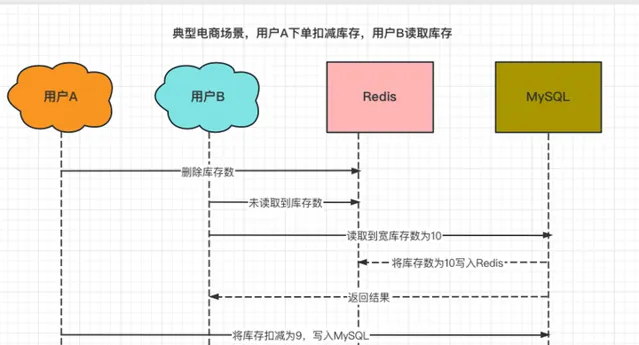
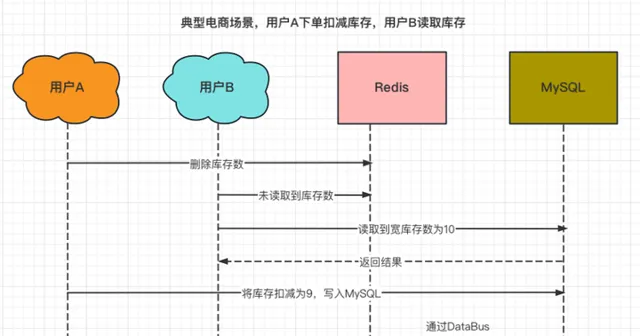
某商品的库存数为10个,用户A购买一件商品时进行库存扣减,因此第一步先删除了Redis中的库存数。
这时,用户B查询该商品的库存,发现Redis中并没有该商品的库存,于是从MySQL中读取库存数后,写入到了Redis中(10个)。
然后,用户A更新数据库,将库存数从10个扣减为9个。
最终,Redis中的库存数是10个,MySQL中的库存数是9个。
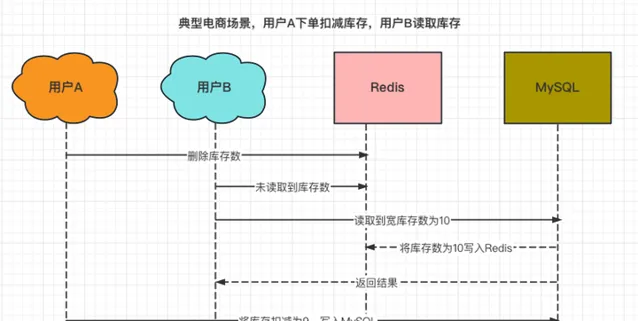
4.2 先删除Redis,再更新MySQL + Binlog同步
该方案将填充Redis的操作,改为通过DataBus和Canal同步Binlog的方式,这样可以解决方案4.1中的Redis读策略带来的数据一致性问题。
但是,这种方案的适用于数据量不大,可以完全吃进Redis缓存中,并设置为永不过期的场景。
而那种数据量庞大到不能全部吃进Redis缓存中,需要在数据读取的时机来写入Redis,长时间未被读取的数据则过期淘汰的场景,就不适合了。
因为这种方案的缓存命中率太低了,也就失去了其应有的价值。
4.3 先删除Redis,再更新MySQL + Redis读策略 + 延时双删
这个方案稍复杂了一些,是在方案4.1中「先删除Redis,再更新MySQL + Redis读策略」,又增加了最后一步Redis删除的操作。
它可以解决「最终,Redis中的库存数是10个,MySQL中的库存数是9个」的数据一致性场景。
也可以跟方案4.2中 「数据量庞大到不能全部吃进Redis缓存中,需要在数据读取的时机来写入Redis,长时间未被读取的数据则过期淘汰」的不适合场景进行互补。
有人会说,这种方案也不能100%保证解决数据一致性的问题,如果最后一步删除操作失败了怎么办?
确实,它并不能保证100%。
但如果第一步删除Redis成功了,第二步Redis读策略恰好在这个间隙期发生并写入Redis成功了,而第三步删除Redis又失败了,这种概率有多大?0.0000001%的可能性有没有?
btw:此处请杠精留言,我最喜欢看到你们面红耳赤、声嘶力竭地杠的样子,很性感。
5、分布式锁
有人说,直接用分布式锁,不就把问题都解决了吗?干吗叽叽歪歪地写这么多字?
是的,分布式锁完全可以解决一致性问题,但你别忘了,引入锁机制的最大弊端是什么?是性能。
而我们用Redis当缓存的初衷是什么?还是性能。有句话怎么说的来着?勿忘初心,方得始终。
结语
还是那句话,系统架构设计中,没有银弹,也没有完美的方案,只有最适合某场景的方案。
分享一套我自己逐字写的、深入浅出、细致易懂的高频面试题详解,旨在以 一站式刷题 + 解惑 的方式帮你提升学习效率,需要的请自取。
强烈建议近期有求职诉求的Javaer好好看看。










