我来贡献一点干货和八卦~
AlphaGo的第一作者David Silver还在MIT做post-doc的时候(也有可能是visit?),曾经和我们组师兄合作利用机器学习和蒙特卡罗树搜索玩【文明2】。当时也有不小的轰动:
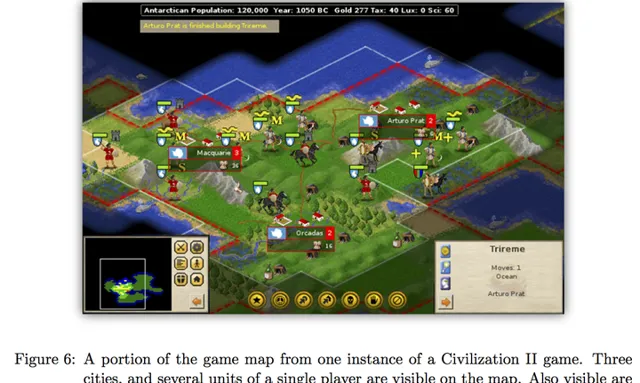
有兴趣的同学可以参考项目主页和论文
[1][2]。可以翻墙youtube的同学还可以看到一段游戏视频。
作为其他答案的补充,下面浅显地针对性地介绍一下蒙特卡罗树搜索(MCTS)。
(***本文图片来源DeepMind和师兄论文)
一、为什么要用搜索?
-------
由于 状态数有限 和 不存在随机性 ,象棋和五子棋这类游戏 理论上 可以由终局自底向上的推算出每一个局面的胜负情况,从而得到最优策略。例如五子棋就被验证为先手必胜
[3]。
遗憾的是,由于大部分博弈游戏状态空间巨大(围棋约为2\times 10^{170} ), 严格计算评估函数是办不到的 。于是人们设计了 (启发式的) 搜索算法 ,一句话概括如下:
由当前局面开始,尝试 看起来可靠的行动 ,达到终局或一定步数后停止,根据后续 局面的优劣 反馈,选择最优行动。通俗的说就是「手下一着子,心想三步棋」、「三思而后行」的意思。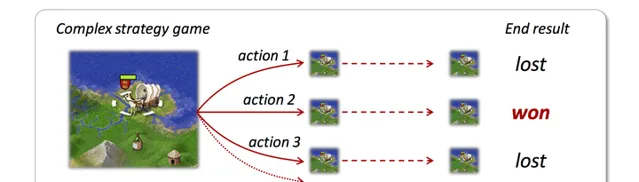
二、哪些是「看起来可靠」的行动?怎么评价局面的优劣?
-------
这里就要引入游戏论和强化学习里面的概念了。在数学上,「最优策略」和「局面判断」可以被量化成为函数Q\left( s, a \right) ,V(s) 。这里s 表示局面状态,a 表示下一步(走子)行动。在强化学习里,两者被称为 策略函数(policy function) 和 局面函数(value function),前者衡量在局面s 下执行a 能带来的价值,后者衡量某一局面s 的价值,越大的值表示对当前行动的选手越有利。
Q和V函数是对我们所谓的「棋感」和「大局观」的量化 。有了这两个估值函数,在搜索的时候我们尽量选择估值更大的行动,达到缩小思考范围(减少搜索分支)的目的。同时即使在未达到终局的情况下,我们也可以依靠局面函数对当前局势优劣做判断。
那么如何得到精确的估值函数就很重要了。 由于不能通过枚举状态空间来精确计算Q和V,传统的做法是人为的设计估值。例如五子棋的局面可以依靠计算「三连」、「四连」等特征的数量乘以相应的分值来估算。这里就涉及到识别特征和衡量特征分值两个问题。对于更加复杂的游戏(例如文明、围棋等),现代的做法是利用机器学习和大量数据, 自动的找到特征,同时拟合出估值函数。 AlphaGo利用深度学习达到了该目的。
三、蒙特卡洛树搜索(MCTS)
-------
蒙特卡洛树搜索是集以上技术于一身的搜索框架,通过反复模拟和采样对局过程(称为 Rollout )来探索状态空间。可以看出它的特点是 非常容易并行 、可任何时候停止(时间和收益上的平衡)、引入了 随机性采样 而减小估值错误带来的负面影响,并且可以在随机探索的过程中,结合强化学习(Reinforcement Learning), 「自学」式的调整估值函数 ,让算法越来越聪明。直观一点的图示如下:
(a) 从当前状态(带有随机性)的模拟对局,该过程可以并行:
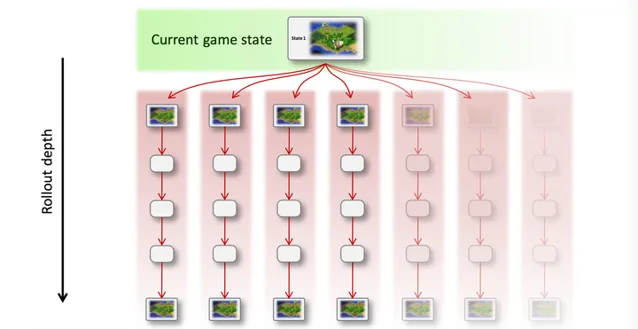
(b) 通过采样和估值结果,选择最优行动,并重复执行这个过程:
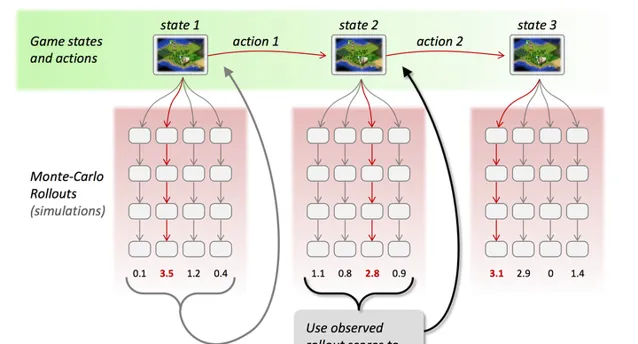
(c) 如果选择强化学习,则根据结果更新估值函数的参数
有兴趣的同学可以阅读AlphaGo或其他相关论文。
四、总结
-------
AlphaGo结合了3大块技术:先进的搜索算法、机器学习算法(即强化学习),以及深度神经网络。这三者的关系大致可以理解为:
这些都不是AlphaGo或者DeepMind团队首创的技术。但是强大的团队将这些结合在一起,配合Google公司强大的计算资源,成就了历史性的飞跃。
一些个人见解:MCTS 、RL 和 DNN这三者,前两者让具有自学能力、并行的博弈算法成为可能,后者让「量化评估围棋局面」成为了可能(这个
@田渊栋大神的
帖子里已经解释了)。
对于AlphaGo来说,这每一个模块都是必要的,DeepMind论文中已经展示了各个模块对于棋力的影响:
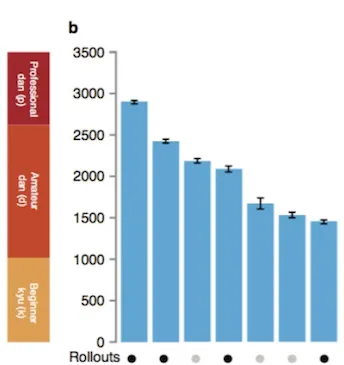
五、RL / MCTS 的其他应用
-------
除了最开始提到的【文明2】游戏和围棋,MCTS和RL还可以应用到各种博弈、游戏场景下。因为评论里有不少讨论,这里增加几个有意思的干货:
其他小八卦
参考文献
-------
[1]
Learning to Win by Reading Manuals in a Monte-Carlo Framework[2]
http://www. jair.org/media/3484/liv e-3484-6254-jair.pdf[3]
wikipedia.org 的页面[4]
http:// nlp.cs.berkeley.edu/pub s/Burkett-Hall-Klein_2011_IMBA_paper.pdf[5]
http://www. nature.com/nature/journ al/v518/n7540/full/nature14236.html










