你以为图形程序员这么好当的啊。。。
上古时期有一个叫做 画家算法 [1] 的东西,本质上很简单:从远向近地绘制物体,这样遮挡关系就是正确的了,当然有了z-buffer也就没人再用了, 反倒是为了充分利用硬件的early-z特性,会从近向远排序物体(这点在移动硬件上也是一样的,不管是TBR还是TBDR)。 不过同样的道理也适用于半透明的混合,因为混合操作本身就是和顺序相关的,所以最简单的当然是对场景物体按照从后往前的顺序排序然后依次绘制。

这个办法不能完美解决问题,因为我们排序的时候是按照物体的包围盒去排序的,对于一些相交的物体来说,它们的三角面的前后顺序未必和物体的前后顺序一致,甚至遇到穿插的模型,两个三角面内的像素也可能前后关系不一致,比如下图这样:
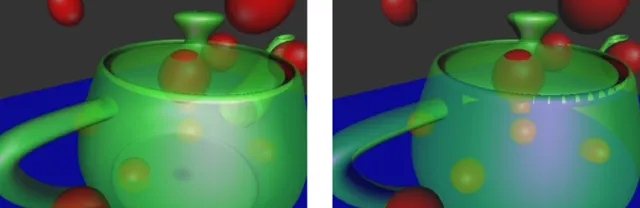
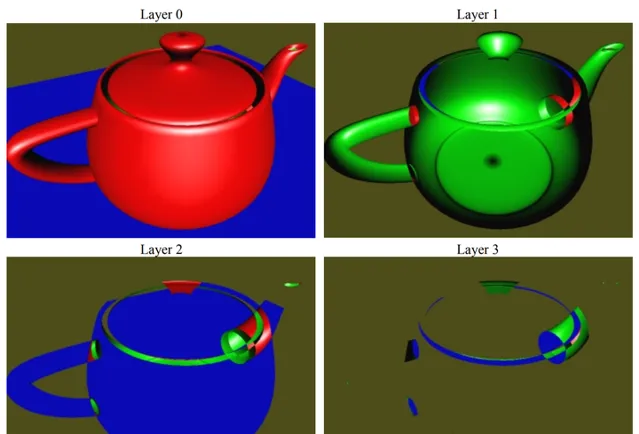
由此才引出你提到的OIT,即次序无关的半透明,早期最经典的方案叫做 depth peeling [2] ,这个算法的过程有点像剥皮,它主要依赖固定管线的depth test,每「一层」半透明图层需要一张render target,对于一个固定像素来说,我们需要知道的是从视点(可认为是depth为0的位置)到不透明像素(不透明像素的深度,如果没有就是1)之间到底有几个半透明图层,我们生成半透明图层的深度顺序是从前往后的,也就是我们先找到 最前面 的半透明图层,然后 找到最前面这一层和不透明层之间夹着的次前的半透明图层 ,以此类推,比如我们有n个半透明图层,那写出来的伪代码大概是这样的(由于是伪代码,我们也不太去强调ping-pong buffer之类的优化,直观为主):
/** CPU side **/
SetDepthWrite(true); // 开启深度写入和比较
SetDepthTest(true, Less);
SetDepthBuffer(BackFaceDepthBuffer);
drawPrimitives(OpaqueMeshList);
for i = 1...n
// 设置输出的RT
SetColorBuffer(ColorTextures[i]);
SetDepthBuffer(FrontFaceDepthBuffers[i]);
SetTexture(FrontFaceDepthBuffers[i - 1]); // 把上一层已经得到的深度传入shader
SetTexture(BackFaceDepthBuffer);
drawPrimitives(TransparentMeshList);
BlendColor(ColorTextures)
/** GPU side, pixel shader **/
Texture2D LastLayerDepth;
Texture2D BackLayerDepth;
float4 Color: SV_Target0;
void main()
{
Color = CalculateColor();
float CurDepth = CalculateDepth();
float LastDepth = Sample(LastLayerDepth, uv); // 读取上一个半透明层当前位置的深度,对于第一层,可以传入一个全黑的Texture
clip(CurDepth- LastDepth); // 根据这个深度剔除掉已经找到的半透明层像素
float BackDepth = Sample(BackLayerDepth, uv);
clip(BackDepth - CurDepth);
}
其实这个算法写出来非常简单,但是根据伪代码也能看出来一个比较明显的问题:同一个半透明物体draw call次数比较多,带宽消耗也比较大,后来在这个算法的基础之上又演化出了 Dual Depth Peeling [3] ,这里就不展开描述了。
另有一类基于半调映射思路做的随机半透明混合 [4] ,基本思路是「 如果我想吃牛奶味的饼干可我恰好只有普通饼干和牛奶,那只要吃一口饼干喝一口牛奶,然后放在嘴里嚼一嚼混在一起就有那味儿了 」。但说到底,牛奶还是牛奶,饼干还是饼干,只是在一个大的尺度上看,好像它们混在了一起。比较典型的就是screen door transparency [5] ,对于每一个位置上,它只有一个sample,也就是说并没有真正地做alpha blend,但他附近有一些待混合的其他sample,于是当你远处来看,或者刚好是个近视眼的时候,那一块看起来就好像是一个经过半透明混合的结果了,这类方法也有它的好处:每个像素都有完整的深度和颜色信息,并且不依赖alpha blend。

除了Screen door transparency,后来的hashed alpha testing [6] 也是类似的思路:

在Compute Shader和UAV(Unorder Access View)诞生之后,由于我们可以自由读写一块GPU Buffer上的任意位置,在GPU中构造一些复杂的数据结构就成为了可能性, per pixel linked list 就是其中一个。这个结构说白了就是我们在CPU中用的链表,链表里面可以存的东西有很多种,比如某个位置的所有半透明像素的颜色的值(用来做半透明渲染) [7] ,又或者影响某个像素的所有光源的索引(用来做光照渲染) [8] 。当年AMD有一个变形金刚的半透明渲染DEMO,用的就是这个技术。

PPLL固然效果完美,但是占用显存大(要预分配足够的链表空间,如果是做光照那就是N*GBufferSize),带宽高仍然是非常大的限制,所以实际上也没有大规模流行起来(对于半透明渲染来说这个几乎无解)。
总结来说,从后向前排序,尽量在设计上规避半透明的问题还是常用的方案,后续有时间我会在专栏另写一篇更详细的OIT技术综述。另外还有比较简单的方法,即先绘制背面的半透明,再绘制正面的半透明,对于只有两层半透明(车窗)来说也勉强够用 [9] 。
参考
- ^ 画家算法 https://zh.wikipedia.org/wiki/画家算法
- ^ https://my.eng.utah.edu/~cs5610/handouts/order_independent_transparency.pdf
- ^https://developer.download.nvidia.cn/SDK/10/opengl/src/dual_depth_peeling/doc/DualDepthPeeling.pdf
- ^https://luebke.us/publications/StochTransp-slides.pdf
- ^https://digitalrune.github.io/DigitalRune-Documentation/html/fa431d48-b457-4c70-a590-d44b0840ab1e.htm
- ^https://developer.download.nvidia.cn/assets/gameworks/downloads/regular/GDC17/RealTimeRenderingAdvances_HashedAlphaTesting_GDC2017_FINAL.pdf?rGDx5SUsI9mG0yPZRBiihKCRjHycAbgCE5nAB5ySwOZHJ44NfD5ADaNES5N_AvxdkAwye7_nS2Dx0dx4iBO4jC1sHOWysiDULZnK8tQw7pohpCKbl7oBjb_LVz5KsnGVaYsEUyxxe03fJHYs_j-1DP8o6jlpa-b-X3AlegjhaL9NPv9R6C-n6Bqp8utdd1AOW8BLFhZFcsKTGXyHQOiRdmHEzq1_Q
- ^ https://www.slideshare.net/hgruen/oit-and-indirect-illumination-using-dx11-linked-lists
- ^http://advances.realtimerendering.com/s2014/insomniac/Light Linked List.pptx
- ^http://www.klayge.org/2011/11/29/klayge-4-0中deferred-rendering的改进(三):透明的烦恼/











