这个问题之前OpenAI 的核心研发人员 Jack Rae在一次分享中解答过。下面我们就分享下如何通过压缩理论,解释为什么像GPT这样的自然语言模型拥有智能。
1. 压缩即智能——为什么ChatGPT拥有智能
目前规模较大的语言模型,在训练基础模型时,都采用了预测下一个词的任务。这个任务非常简单,就是根据语言中前面的词,来生成下一个词。这样学习到的似乎只是词之间的表面统计关系,怎么就能体现出智能呢?这确实很难理解。
2月28日,OpenAI 的核心研发人员 Jack Rae 在 Stanford MLSys Seminar 上分享了一个主题:压缩与人工通用智能。他的核心观点是:人工通用智能的基础模型应该能够最大程度地无损压缩有效信息。他还分析了这个目标的合理性,以及 OpenAI 是如何按照这个目标进行工作的。
Jack Rae 是 OpenAI 的团队负责人,主要研究大型语言模型和远程记忆。他曾在 DeepMind 工作了 8年,领导了大型语言模型研究组。在分享中,Jack Rae 提出了以下两个核心观点。
Jack Rae 在 Stanford ML Seminar 上的分享非常精彩,让人感觉豁然开朗。他用压缩理论来解释为什么 GPT 具有智能,是一个很有创意的观点。下面我们就具体介绍一下 Jack Rae 是如何论证的。
1.1 直观理解AGI
在探讨压缩如何能够实现人工通用智能之前,先来了解一下什么是人工通用智能。「中文房间」是约翰·塞尔(John Searle)在1980年提出的一个著名的思想实验,用来质疑计算机是否能够真正理解语言。实验的设想可以通过下面的文字描述。
一个只会说英语,对中文一无所知的人被关在一个密闭的房间里。房间里只有一个小窗口,还有一本中英文对照的手册,以及足够的纸和笔。有人从窗口递进来一些写着中文的纸条。房间里的人根据手册上的规则,把这些纸条翻译成中文,并用中文写回去。尽管他完全不懂中文,但是通过这个过程,他可以让房间外的人认为他会说流利的中文。这就是「中文房间」的实验,图1-1展示了它的示意图。

一个庞大而烦琐的手册说明了这个人的智能水平很低,因为他只能按照手册上的指示去做,一旦遇到手册中没有的情况,他就束手无策了。
如果我们能够从海量的数据中学习到一些语法和规则,那么就可以用一个简洁而高效的手册来指导这个人,这样他就能够更灵活地应对各种情况,表现出更高的智能水平(泛化能力更强)。
手册的厚度反映了智能的强度。手册越厚,说明智能越弱;手册越薄,说明智能越强。就像在公司里,你雇用一个人,他能力越强,你需要给他的指示就越少;他能力越弱,你需要给他的指示就越多。
这个例子用一个比较形象的方式解释了为什么压缩就是智能。
1.2 如何实现无损压缩
假设 Alice 需要把一个(可能无限长)的数据集D = \{x_1, x_2, ..., x_n, ...\} 从遥远的半人马座星系传输回地球上的 Bob,假设如下。
先看一下基准传输方法。由于 x_{t+1} 的可能性有m = 256种,所以 z_{t+1} 可以表示为一个8比特的整数(即1字节)。假如当 x_{t+1}=7 时, z_{t+1}=00000111 表示 x_{t+1} 。这时需要传输的比特数 |z_{t+1}| = \log m = \log 256 = 8 。另外,Alice还要将上面的代码写成代码 f_0 ,在一开始传输给Bob。图1-2是编码数据传输的示意图。
这样传输一个大小为n的数据集的D_n = \{x_1, x_2, ..., x_n\} 的代价S_0 可以表示为如下形式。
\begin{align} S_0 & = \#bits \\ & = |f_0| + \sum_{t=1}^n |z_{t}| \\ & = |f_0| + n \log m \end{align} \\ \tag1 接下来从信息论角度解释一下基准的信息量。
基准方法对于 x_{t+1} 的分布没有先验知识,因此其概率分布故P(x_{t+1}) = \dfrac{1}{m} 是一个离散均匀分布。此时信息量表示为如下形式。
I= -\log P(x_{t+1}) = -\log \dfrac{1}{m} = \log m = |z_{t+1}| \\\tag2
因此, |z_{t+1}| 也可以看作是 P(x_{t+1}) 的信息量。
在介绍了基准方法之后,接下来介绍一下基于神经网络的无损压缩方法。想要利用一个自回归神经网络来实现压缩。具体来说,假设如下的一个场景。
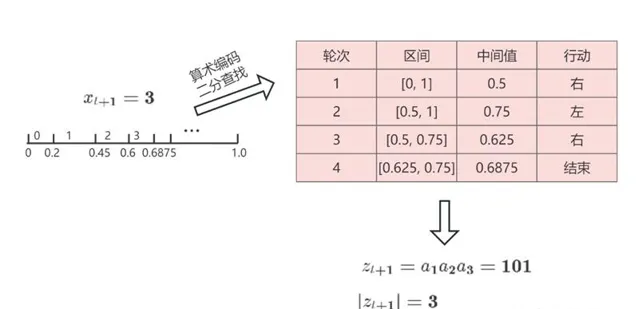
这样一来,Alice 就实现了把x_{t+1}=3 按照 Alice 和 Bob 共同掌握的概率分布编码成 z_{t+1}=\left( 1,0,1 \right)_2 ,并且把它无损地传输给 Bob。Bob 也可以按照同样的概率分布把z_{t+1}=\left( 1,0,1 \right)_2 解码回 x_{t+1}=3 。这个过程比基准方法节省了很多传输的数据量。原本需要传8比特,现在只需要传3比特。图1-4是整个过程的示意图。
2. GPT是对数据的无损压缩
前面介绍了算术编码的原理,它可以实现无损压缩,从而减少数据传输的量。我们的目标是最小化传输的量,也就是最小化二分查找的次数。
为了计算二分查找的次数的上界,可以用一个直观的方法。还是用上面的例子,x_{t+1} = 3 。将x_{t+1} 的区间均匀铺满整个[0,1] 区间,假设p = P(x_{t+1}=3 | x_{1:t}, f) ,那么会分成m= {\large\lceil} \dfrac{1}{p}\large\rceil 个区间,那么大约要查询\log m 次。如果不考虑取整的误差,可以得到二分查找的次数,表示为如下的形式。
|z_{t+1}| \sim \log m \sim -\log p\tag3 实际上,二分查找的次数的上界可以表示为如下的形式。
|z_{t+1}|\le \lceil \log \dfrac{1}{p}\rceil \lt -\log p + 1 \\\tag4
这样就可以知道传输数据集 D_n 的代价 S_1 ,表示为如下的形式。 \begin{align} S_1 & = |f_1| + \sum_{t=1}^n |z_{t+1}| \\ & \lt |f_1| + \sum_{t=1}^n [-\log P(x_{t+1} | x_{1:t}, f) + 1] \\ & = |f_1| + n + \sum_{t=1}^n -\log P(x_{t+1} | x_{1:t}, f_1) \end{align} \\\tag5
如果仔细观察,会发现-\log P(x_{t+1} ) 其实就是训练时x_{t+1} 这个 token 的 loss。所以可以进一步发现\sum_{t=1}^n -\log P(x_{t+1} | x_{1:t}, f_1) 这一项就是训练曲线下方的面积,具体示例如图2-1所示。
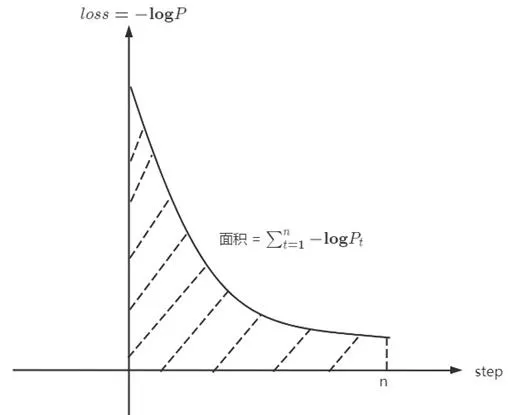
因此,GPT的训练过程本质上就是对整个数据集 D 的无损压缩。图2-2详细展示了GPT无损压缩的每一项内容。
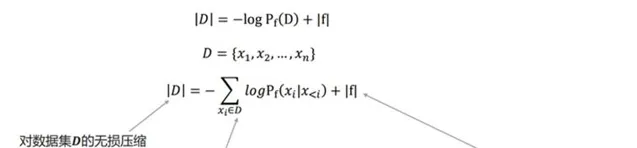
按照上述方式计算并存储z_{t} ,那么 "训练代码 + 所有的z_t " 便是对数据集D 的无损压缩。只是在平时训练中计算得到下一个token的分布,并且计算loss进行反传后,便扔掉了这个分布,自然也没有计算并存储z_t 。但是「无损压缩」和「模型训练」的过程是等价的。
有了压缩的量化公式,便可以很方便地计算压缩率,下面是压缩率的计算公式。 \begin{align} r_n = 1 - \dfrac{S_1}{S_0} \gt 1 - \dfrac{|f_1| + n + \sum_{t=1}^n -\log P(x_{t+1} | x_{1:t}, f_1)}{|f_0| + n \log m} \end{align} \\\tag6
这也解释了为什么模型越大,往往表现越智能,更容易出现涌现。这是因为模型越大,往往loss越低,从而压缩率越高,模型越智能。(这里是根据数据压缩理论,就是压缩率越高,模型越智能)。
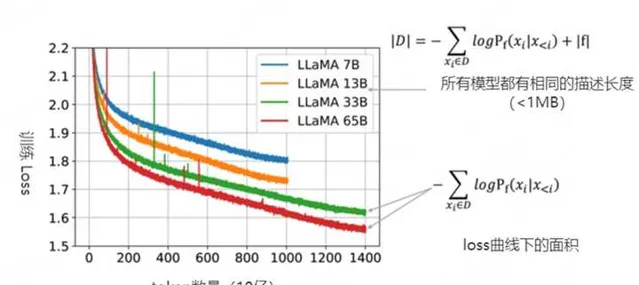
上图2-3是 LLaMA 模型的一些训练曲线,绿线和红线表示的两个模型只在数据集上训练了1个epoch,因此可以把训练损失视为| D |中下一个词(next-token)预测损失。同时也可以粗略地估计模型的描述长度(~1MB)。即便模型的参数量不同,但LLaMA 33B和LLaMA 65B两个模型有着相同的数据描述长度(用于训练的代码相同)。但65B模型显然有着更低的训练损失,把两项相加,可以看出65B实际上是更好的压缩器。
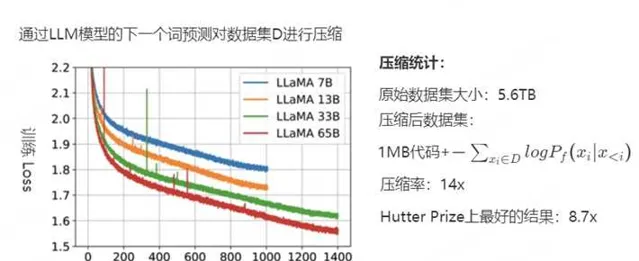
下图2-4是更具体的数据,用于初始化和训练模型的代码约为 1MB,粗略地计算负对数似然大约是 400GB,而用于训练的原始数据是5.6TB的文本,因此该模型的压缩率为14倍。而Hutter Prize上最好的文本压缩器能实现8.7倍的压缩。接下来,讨论一下压缩率的变化。
假设训练稳定,loss 平滑下降收敛到 \lim_{t\rightarrow\infty} -\log P(x_{t+1} | x_{1:t}, f_1) = - \log p^* ,那么当数据集D 无限增长时,压缩的极限可以表示为如下形式。
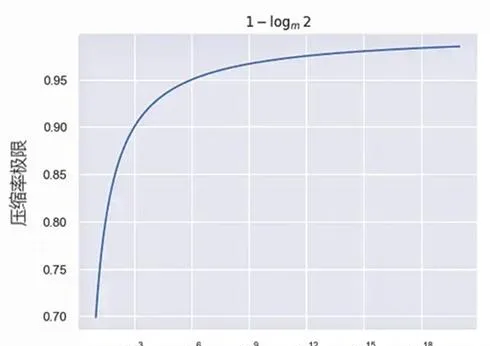
\begin{align} r & = \lim_{n \rightarrow \infty} r_n \\ & = \lim_{n \rightarrow \infty} 1 - \dfrac{|f_1| + n + \sum_{t=1}^n -\log P(x_{t+1} | x_{1:t}, f_1)}{|f_0| + n \log m} \\ & = \lim_{n \rightarrow \infty} 1 - \dfrac{|f_1| + n + n(- \log p^*)}{|f_0| + n \log m} \\ & = 1 - \dfrac{1-\log p^*}{\log m} \\ & = 1 - \log_m 2 + \log_m p^* \\ \end{align} \\\tag7
当 p^* \to 1 (预测得完全准确),压缩率的曲线如图2-5所示。由此可见,预测下一个词(next token prection)看似简单,但是却可以用压缩理论完美地解释,这也是为什么OpenAI坚持「预测下一个词」的原因。
虽然像GPT这样的大模型可以实现压缩机制,但是这种压缩方式也有局限性。比如对于所有的一切都进行压缩非常不现实,像素级的图像建模开销非常大,对视频进行像素级别的建模非常不现实。还有就是非常多在现实中的数据可能是无法直接观测到的,不能指望通过压缩所有可观测到的数据实现通用人工智能。以围棋游戏AlphaZero为例,观察有限数量的人类游戏不足以实现真实的突破。相反,需要其智能体(Agent)自行进行对弈并收集数据中间的数据。
参考











