transformer的细节到底是怎么样的?
本文梳理了所有 transformer 的技术的细节,想要了解transformer的技术细节,看这一篇就足够了!
内容上是这样的,以 GPT2/llama/ViT/Whisper的信息为基础说明
文字序列的 token 化
做为transformer 的输入,只有一个 token 的概念。但是这个 token 是什么呢?大部分人的咋一看的结果就是一串文字转成一串数字,像 ascii码一样的东西嘛。
实际上它确实复杂一些。因为 token 到 transformer 的输入时已经变成了一个二维的矩阵。而一个简单的文字序列如何变成二维矩阵
一个简单的图像如何变成二维矩阵
一个简单的声音如何变成二维矩阵
这些都是个问题。
文字序列的 token 化
文字的序列化是下面这样的操作
- 文字序列根据 BPE 或者其它别的编码方法得到 Token(你可以认为 token 是一种文字的编码方式,一个英文单词编码在 1~2 个 token, 一个汉字编码是 1~3 个 token,每个 token 都是一个数字)
- Token 通过查表直接得到 Embeding的矩阵(这个表通常非常大 ,比如GPT3 可能是 12288x4096, 12288是 token 个数,4096 是维度,也就是每个 token 查表后有 4096 维,这东西也是训练出来的)
- Token 通过 Postion 计算 Positional Encoding(标准算法公式)
- 将 Embedding 与 Positional Encoding 相加得到 Transformer的输入

Token 的查表结果
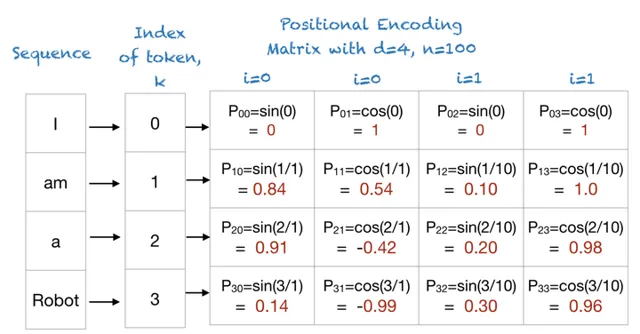
Token 的 Positional Encoding 结果,它的计算公式如下。
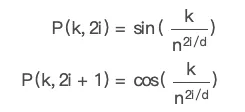
上面只是讲了 transformer 的输入的 token 如何生成这一部分,你可以感觉到,其实这东西的细节还是不少的。如果你真的想通过学习 大模型/LLM 的知识来达到学习知识、增加职业竞争力,我比较建议你听听知乎知学堂推出的【程序员的AI大模型进阶之旅】,非常适合想学大模型的学员。课程适合有一定编程基础的程序员,邀请了圈内知名的ai大牛授课,趁着现在还免费,我建议你看看⬇️
别忘了添加助教领取上课的课件,这对于快速入门大模型,跟老师深入沟通还是比较有帮助的。
图像的 token 化
图像的 token 化也比较简单,它就是直接分割成小块,通常是 16x16, 再按顺序排好,然后把它们加个位置编码就好了。
看下面这张图,它就是把一个图片如何搞成了 token,然后再输入到了 transformer。
在这里,图片被切割拉平后,是直接扔到一个 CNN 网络里搞成 Transformer 的输入部分的。
声音的 token 化
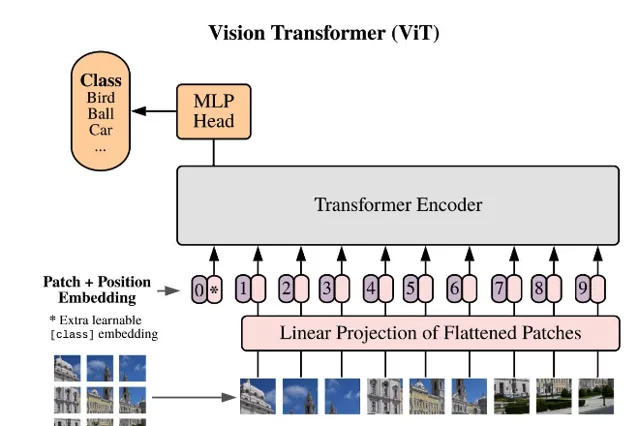
可能声音的 token 化是最简单的,因为它天生就有二维特殊,mel 谱数据。
以 openai 的 whisper 项目为例,它的声音输入的 token 就很简单。每 30ms 一个,80 个log mel 谱数据。这样只要不断的切段,这个声音就直接变成了二维矩阵了。差不多类似下面的东西,
但是它有位置编码吗?当然也有了,它的核心 Positional Embedding 算法是下面这个。
在正式解释 Transformer 前,全图镇楼
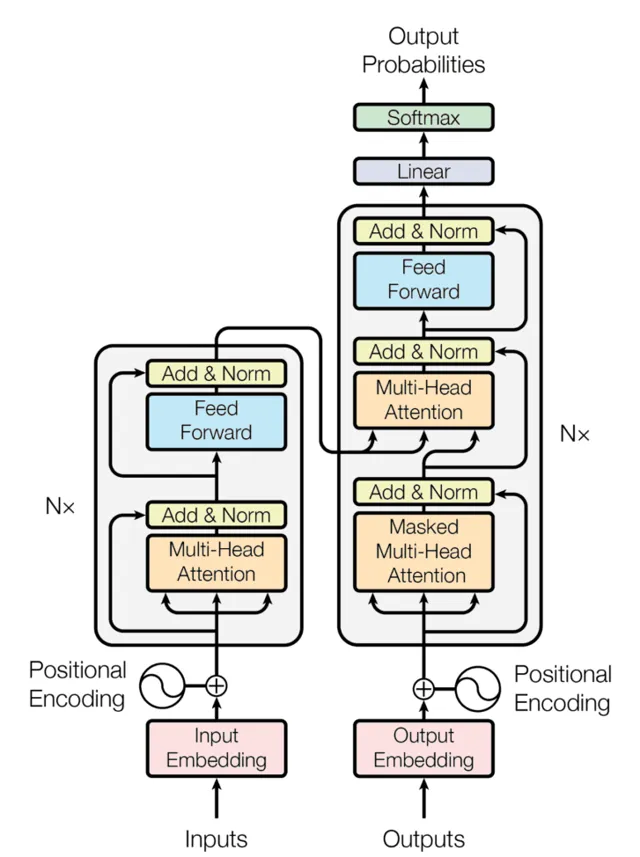
encoder 实现
对于 encoder 来讲,它的核心是Attention 机制。了解了它你就了解了整个 transformer 世界了。在 Attention 机制的基础上又通过多头机制,把它扩展成了 Encoder 的核心部分。
下面这张图是最核心的 Scaled Dot-Product Attention ,请一定要弄懂它。
Scaled Dot-Product Attention

这里的 Q 、 K 、 V 都是分别 有一个训练后的矩阵与上面讲的 Embedding+PositionalEncoding 的结果相乘后的数据。在 Encoder 里是没有 Mask 的计算的,它是用于 Decoder 部分的。
MHA/Multi-Head Attention
再然后用Scaled Dot-Product Attention 组成了下面的 MHA/Multi-Head Attention 。
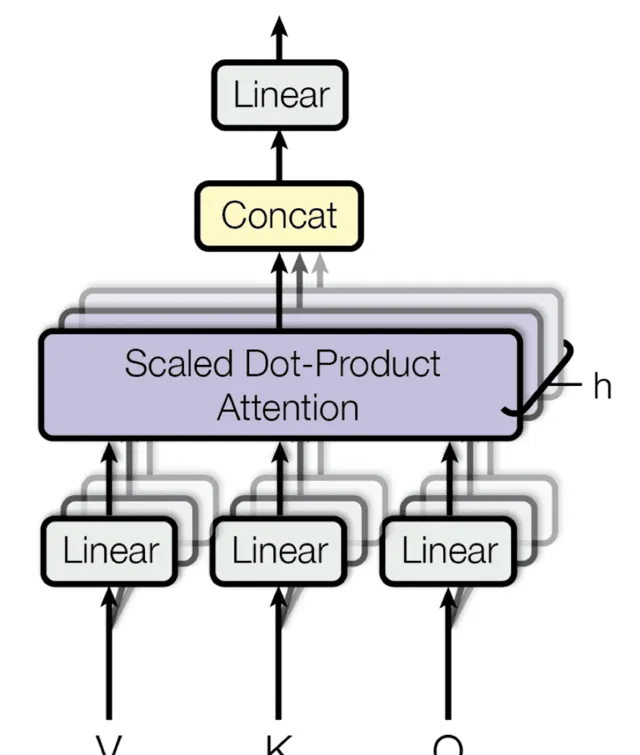
这样,通过 MHA结构再加上 Add&Norm 及 Feed Forward(一个标准的 MLP 网络),然后再用 Add & Norm 就得到了一个 Attention 块。这样的 N 个串连处理后,就能得到 Encoder 部分。
Encoder全部
decoder 实现
decoder 与 encoder 相比,它的计算方式的变化是增加了一个可选的 mask,同时它的输入有一部分是直接来自于 Encoder 的, 而另一部分 则是来自于自身的输出的不断SHIFT,也就是输出部分不断的向右移增加 的输入部分。下面这个图的 Decoder 部分就比较好理解了。
Mask 实现
那就有一个问题 mask 在什么时间使用,它的实现方式是什么。
实际上 Mask 与输入是相对应的,Outputs 的长度与 Mask 是互补的。
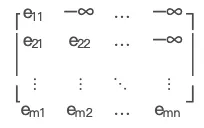
它的实际计算是通过 masked_fill(mask==0, -1e9)类似这样的一段代码实现的。因为 Outputs 以外的 Embedding 数据是会被写成全「0」的,把它再填 成一个极小值 -1e9 后,这个经过 softmax 计算时,这些数据就会变成近似于 0 的极小数。
相信你看了 Encoder 的计算方式,是一定会很容易理解 Decoder 这一部分的。
不过请相信我,一定要自己动手写一下,才会真的理解这个模型有多好玩!
output 实现
这个大概是所有的工作里最简单的,只要最后用个Linear 层,再用个softmax 就可以得到 token了,那自然再反查一下 BPE 编码(如果我们是这么用的),那就有了结果了不是?
也就是下面这一点儿图了。 不过不要看它在图里占的小,这个实际上是一个巨大的查表输出,因为 Softmax 与 Token 表的大小是一致的。也就是你的每一次计算输出的是巨大一维数组,以 GPT3举例 可能是 12288, 12288是 原来token编码的词表大小。现在你可以查到这里对应的 Token 了吧!
flash attention 优化
做为最近出现的,马上就迅速实际应用的 Transformer 优化,可以说是最近针对 transformer 的优化最正确的方向,它的目标极其明确,尽可能的优化显卡的计算使用方式,最大化计算最小化数据传输,同时不改变任何原来的网络结构,只要你简单的替换掉 transformer 的传统计算就成了。
单纯的看这个图就能看到作者的大方向的思路,从整体的角度去优化这个 Attention 机制。大家在谈一个模型的快慢时,经常谈到的就 算力,是 FLOPS, 是 flops,是 TOPS,但是很多人并不知道,现在的芯片经常碰到的问题是,算力比 IO 快好多,经常处于算力在等待的状态,也就是 访存比高 。所以优化算法,去优化它的算力,远没有优化它的 IO 能得到更好的整体效果。
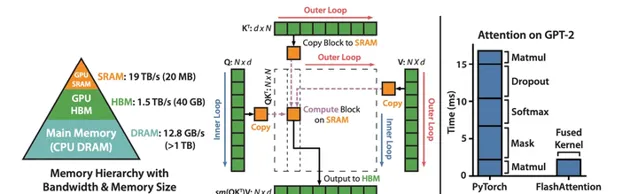
单纯的看这个图就能看到作者的大方向的思路,从整体的角度去优化这个 Attention 机制。大家在谈一个模型的快慢时,经常谈到的就 算力,是 FLOPS, 是 flops,是 TOPS,但是很多人并不知道,现在的芯片经常碰到的问题是,算力比 IO 快好多,经常处于算力在等待的状态,也就是 访存比高 。所以优化算法,去优化它的算力,远没有优化它的 IO 能得到更好的整体效果。
如果大家有兴趣可以看另一个回答:
https://www. zhihu.com/question/6020 57035/answer/3297728852
streaming llm 优化
这是我看到的最鼓舞人心的方向,它非常好的解决了 基于transformer 的llm 的窗口问题,可以让窗口无限大。也就是有可能实现类人的智能世界 。
在大方向上,这个 streamingllm 是找到了一个 token 的有用的特征:sink token 。 就是找到在 softmax 时得分最高的 token,实际上也应该是相关性最好的那一个(好像通常是第一个)。这样就能只靠很少的 token 就能保留历史信息,而有了足够的历史信息就能很好的保证你的持续输出了不是?
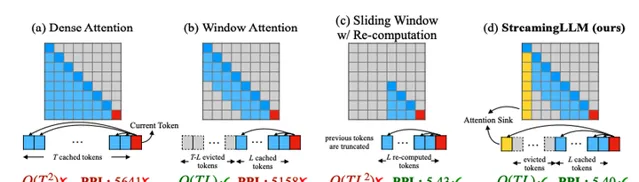
不得不说这个方向确实特别吸引我,我要好好研究一下,然后再写一篇文章。
参考
[1]streaming-llm https:// github.com/mit-han-lab/ streaming-llm
[2]flash attention https:// github.com/Dao-AILab/fl ash-attention
[3]openai whisper https:// github.com/openai/whisp er
[4] Transformer Implements from scratch https:// github.com/hkproj/pytor ch-transformer.git
[5] llm visulation https:// bbycroft.net/llm











